La agrupación de aplicaciones con ruido basada en la densidad ( DBScan ) es un algoritmo no lineal de aprendizaje no supervisado. Utiliza la idea de accesibilidad de densidad y conectividad de densidad. Los datos se dividen en grupos con características similares o clústeres, pero no es necesario especificar el número de esos grupos por adelantado. Un clúster se define como un conjunto máximo de puntos densamente conectados. Descubre grupos de formas arbitrarias en bases de datos espaciales con ruido.
Teoría
En el agrupamiento DBScan, la dependencia de la distancia-curva de dimensionalidad es mayor. El algoritmo es como sigue:
- Seleccione al azar un punto p .
- Recupere todos los puntos que son densidad alcanzable desde p con respecto al radio máximo del vecindario (EPS) y el número mínimo de puntos dentro del vecindario eps (Min Pts).
- Si el número de puntos en la vecindad es mayor que Min Pts, entonces p es un punto central.
- Para p puntos centrales, se forma un grupo. Si p no es un punto central, márquelo como ruido/valor atípico y pase al siguiente punto.
- Continúe el proceso hasta que todos los puntos hayan sido procesados.
El agrupamiento de DBScan es insensible al orden.
El conjunto de datos
IrisEl conjunto de datos consta de 50 muestras de cada una de las 3 especies de Iris (Iris setosa, Iris virginica, Iris versicolor) y un conjunto de datos multivariante introducido por el estadístico y biólogo británico Ronald Fisher en su artículo de 1936 El uso de mediciones múltiples en problemas taxonómicos. Se midieron cuatro características de cada muestra, es decir, la longitud y el ancho de los sépalos y pétalos y, basándose en la combinación de estas cuatro características, Fisher desarrolló un modelo discriminante lineal para distinguir las especies entre sí.
# Loading data data(iris) # Structure str(iris)

Realización de DBScan en conjunto de datos
Usando el algoritmo de agrupamiento de DBScan en el conjunto de datos que incluye 11 personas y 6 variables o atributos
# Installing Packages
install.packages("fpc")
# Loading package
library(fpc)
# Remove label form dataset
iris_1 <- iris[-5]
# Fitting DBScan clustering Model
# to training dataset
set.seed(220) # Setting seed
Dbscan_cl <- dbscan(iris_1, eps = 0.45, MinPts = 5)
Dbscan_cl
# Checking cluster
Dbscan_cl$cluster
# Table
table(Dbscan_cl$cluster, iris$Species)
# Plotting Cluster
plot(Dbscan_cl, iris_1, main = "DBScan")
plot(Dbscan_cl, iris_1, main = "Petal Width vs Sepal Length")
Producción:
- Modelo dbscan_cl:
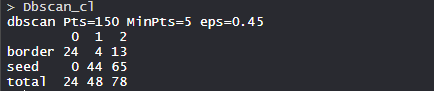
En el modelo, hay 150 Pts con puntos mínimos son 5 y eps es 0,5.
- Identificación del conglomerado:

Se muestran los clústeres en el modelo.
- Grupo de trazado:
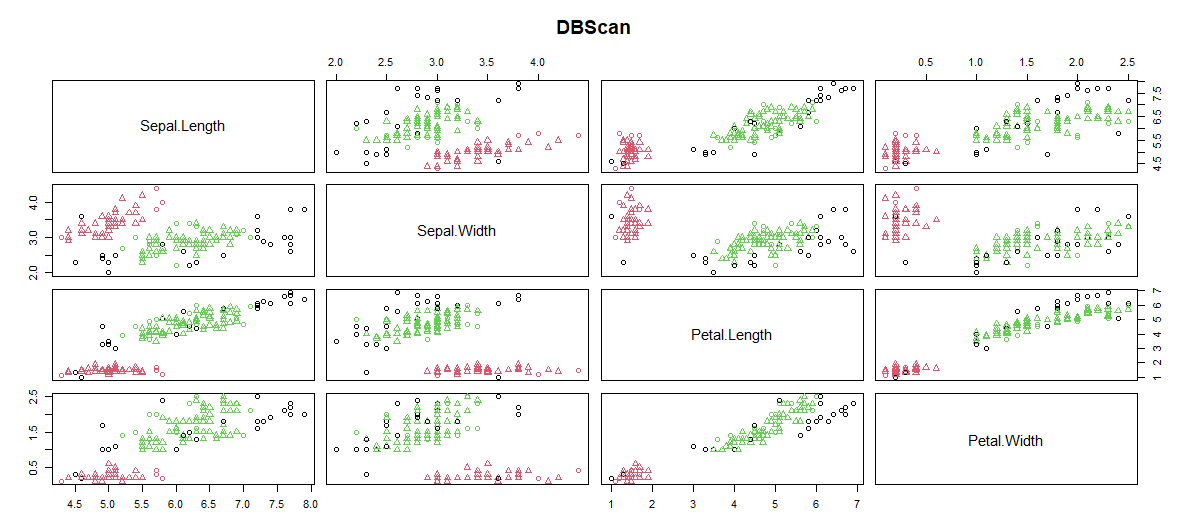
El clúster DBScan se traza con Sepal.Length, Sepal.Width, Petal.Length, Petal.Width.
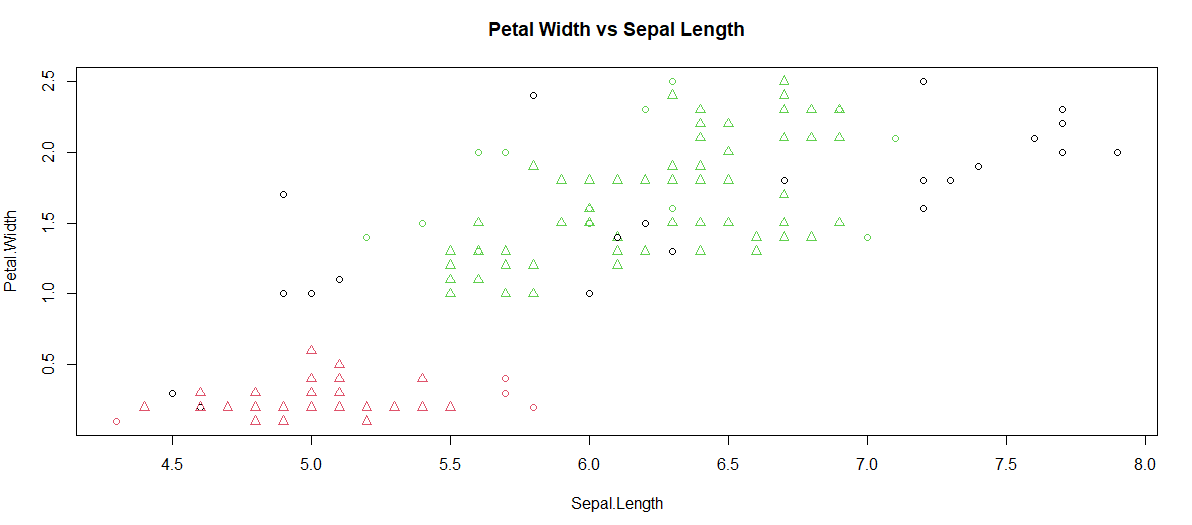
La trama se traza entre Petal.Width y Sepal.Length.
Por lo tanto, el algoritmo de agrupamiento de DBScan también puede formar formas inusuales que son útiles para encontrar un grupo de formas no lineales en la industria.