K Means Clustering en R Programming es un algoritmo no lineal no supervisado que agrupa datos en función de la similitud o grupos similares. Busca dividir las observaciones en un número predeterminado de grupos. La segmentación de datos se lleva a cabo para asignar cada ejemplo de entrenamiento a un segmento llamado clúster. En el algoritmo no supervisado, se otorga una gran confianza en los datos sin procesar con un gran gasto en la revisión manual para la revisión de la relevancia. Se utiliza en una variedad de campos como la banca, la salud, el comercio minorista, los medios de comunicación, etc.
Teoría
El agrupamiento de K-Means agrupa los datos en grupos similares. El algoritmo es como sigue:
- Elija el número K clústeres.
- Seleccione al azar K puntos, los centroides (no necesariamente de los datos dados).
- Asigne cada punto de datos al centroide más cercano que forme grupos K.
- Calcule y coloque el nuevo centroide de cada centroide.
- Reasigne cada punto de datos a un nuevo clúster.
Después de la reasignación final, nombre el clúster como Clúster final.
El conjunto de datos
IrisEl conjunto de datos consta de 50 muestras de cada una de las 3 especies de Iris (Iris setosa, Iris virginica, Iris versicolor) y un conjunto de datos multivariante introducido por el estadístico y biólogo británico Ronald Fisher en su artículo de 1936 El uso de mediciones múltiples en problemas taxonómicos. Se midieron cuatro características de cada muestra, es decir, la longitud y el ancho de los sépalos y pétalos y, basándose en la combinación de estas cuatro características, Fisher desarrolló un modelo discriminante lineal para distinguir las especies entre sí.
# Loading data data(iris) # Structure str(iris)

Realización de clústeres de K-Means en conjuntos de datos
Usando el algoritmo de agrupamiento de K-Means en el conjunto de datos que incluye 11 personas y 6 variables o atributos
# Installing Packages
install.packages("ClusterR")
install.packages("cluster")
# Loading package
library(ClusterR)
library(cluster)
# Removing initial label of
# Species from original dataset
iris_1 <- iris[, -5]
# Fitting K-Means clustering Model
# to training dataset
set.seed(240) # Setting seed
kmeans.re <- kmeans(iris_1, centers = 3, nstart = 20)
kmeans.re
# Cluster identification for
# each observation
kmeans.re$cluster
# Confusion Matrix
cm <- table(iris$Species, kmeans.re$cluster)
cm
# Model Evaluation and visualization
plot(iris_1[c("Sepal.Length", "Sepal.Width")])
plot(iris_1[c("Sepal.Length", "Sepal.Width")],
col = kmeans.re$cluster)
plot(iris_1[c("Sepal.Length", "Sepal.Width")],
col = kmeans.re$cluster,
main = "K-means with 3 clusters")
## Plotiing cluster centers
kmeans.re$centers
kmeans.re$centers[, c("Sepal.Length", "Sepal.Width")]
# cex is font size, pch is symbol
points(kmeans.re$centers[, c("Sepal.Length", "Sepal.Width")],
col = 1:3, pch = 8, cex = 3)
## Visualizing clusters
y_kmeans <- kmeans.re$cluster
clusplot(iris_1[, c("Sepal.Length", "Sepal.Width")],
y_kmeans,
lines = 0,
shade = TRUE,
color = TRUE,
labels = 2,
plotchar = FALSE,
span = TRUE,
main = paste("Cluster iris"),
xlab = 'Sepal.Length',
ylab = 'Sepal.Width')
Producción:
- Modelo kmeans_re:
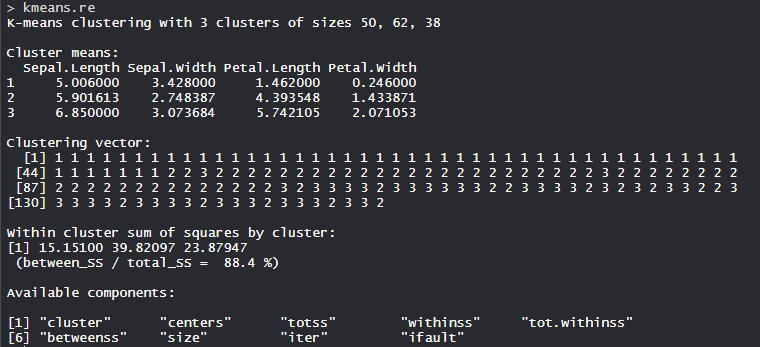
Se fabrican los 3 clusters que son de 50, 62 y 38 tamaños respectivamente. Dentro del clúster, la suma de cuadrados es 88,4%.
- Identificación del conglomerado:
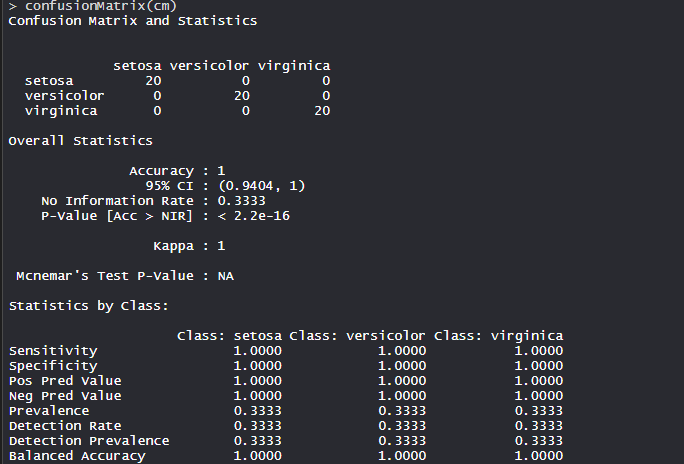
El modelo logró una precisión del 100 % con un valor p inferior a 1. Esto indica que el modelo es bueno.
- Array de confusión:
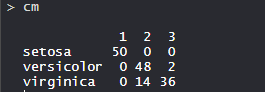
Entonces, 50 Setosa se clasifican correctamente como Setosa. De 62 Versicolor, 48 Versicolor se clasifican correctamente como Versicolor y 14 se clasifican como virginica. De 36 vírgenes, 19 vírgenes se clasifican correctamente como vírgenes y 2 se clasifican como Versicolor.
- K-medias con gráfico de 3 grupos:
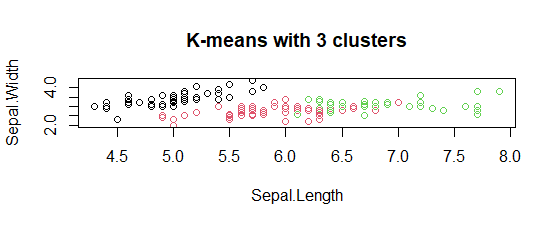
El modelo mostró 3 parcelas de conglomerados con tres colores diferentes y con Sepal.longitud y con Sepal.ancho.
- Trazado de centros de conglomerados:
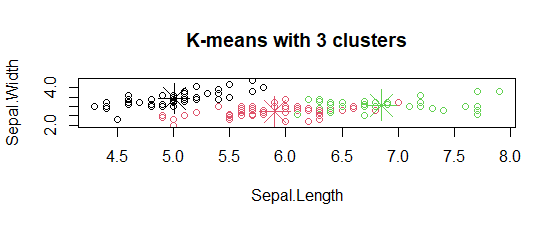
En la parcela, los centros de los conglomerados están marcados con cruces del mismo color del conglomerado.
- Parcela de conglomerados:
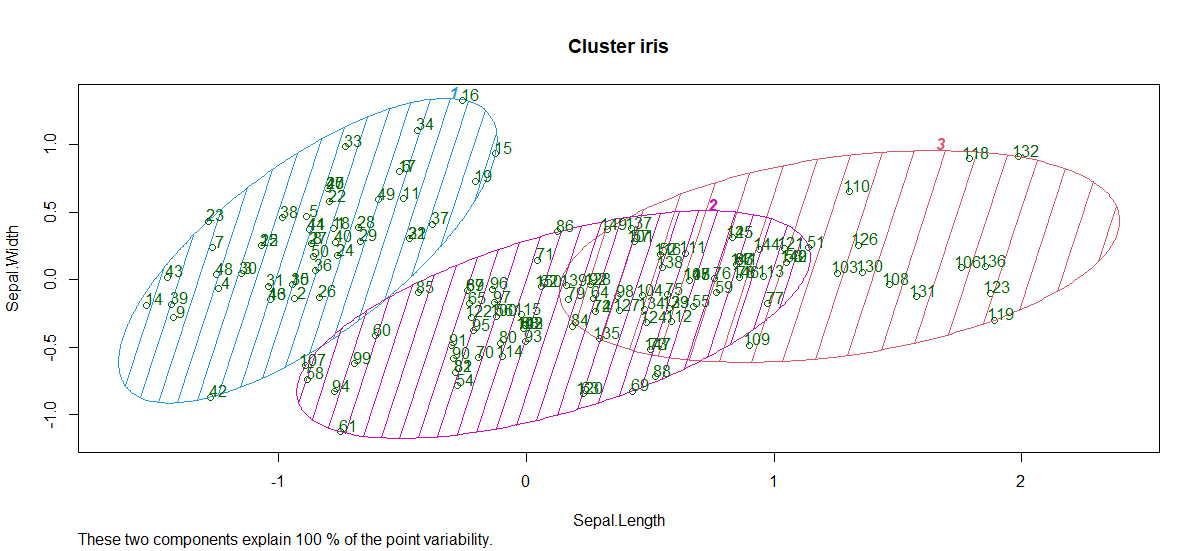
Entonces, se forman 3 grupos con diferentes longitudes y anchos de sépalos. Por lo tanto, el algoritmo de agrupación en clústeres K-Means se usa ampliamente en la industria.