Requisitos previos: Algoritmo de aprendizaje de una regla
La cobertura secuencial es un algoritmo popular basado en la clasificación basada en reglas que se utiliza para aprender un conjunto disyuntivo de reglas. La idea básica aquí es aprender una regla, eliminar los datos que cubre y luego repetir el mismo proceso. En este proceso, de esta manera, abarca todas las reglas involucradas con él de manera secuencial durante la fase de entrenamiento.
Algoritmo involucrado:
Sequential_covering (Target_attribute, Attributes, Examples, Threshold):
Learned_rules = {}
Rule = Learn-One-Rule(Target_attribute, Attributes, Examples)
while Performance(Rule, Examples) > Threshold :
Learned_rules = Learned_rules + Rule
Examples = Examples - {examples correctly classified by Rule}
Rule = Learn-One-Rule(Target_attribute, Attributes, Examples)
Learned_rules = sort Learned_rules according to performance over Examples
return Learned_rules
El algoritmo de Aprendizaje Secuencial se ocupa hasta cierto punto del problema de baja cobertura en el algoritmo de Aprender-Una-Regla que cubre todas las reglas de manera secuencial.
Trabajando en el Algoritmo:
El algoritmo involucra un conjunto de ‘reglas ordenadas’ o ‘lista de decisiones’ a tomar.
Paso 1: cree una lista de decisiones vacía, ‘R’.
Paso 2 – Algoritmo ‘ Aprender una regla’
Extrae la mejor regla para una clase particular ‘y’, donde una regla se define como: (Fig.2)
Forma general de regla

Al principio,
Paso 2.a: si todos los ejemplos de entrenamiento son clase ‘y’, entonces se clasifica como ejemplo positivo .
Paso 2.b: de lo contrario, si todos los ejemplos de entrenamiento ∉ clase ‘y’, se clasifica como ejemplo negativo .Paso 3: la regla se vuelve ‘deseable’ cuando cubre la mayoría de los ejemplos positivos.
Paso 4: cuando se obtenga esta regla, elimine todos los datos de entrenamiento asociados con esa regla.
(es decir, cuando la regla se aplica al conjunto de datos, cubre la mayoría de los datos de entrenamiento y debe eliminarse)Paso 5: la nueva regla se agrega al final de la lista de decisiones, ‘R’. (Fig. 3)
Fig. 3: Lista de decisiones ‘R’
A continuación, se muestra una representación visual que describe el funcionamiento del algoritmo.
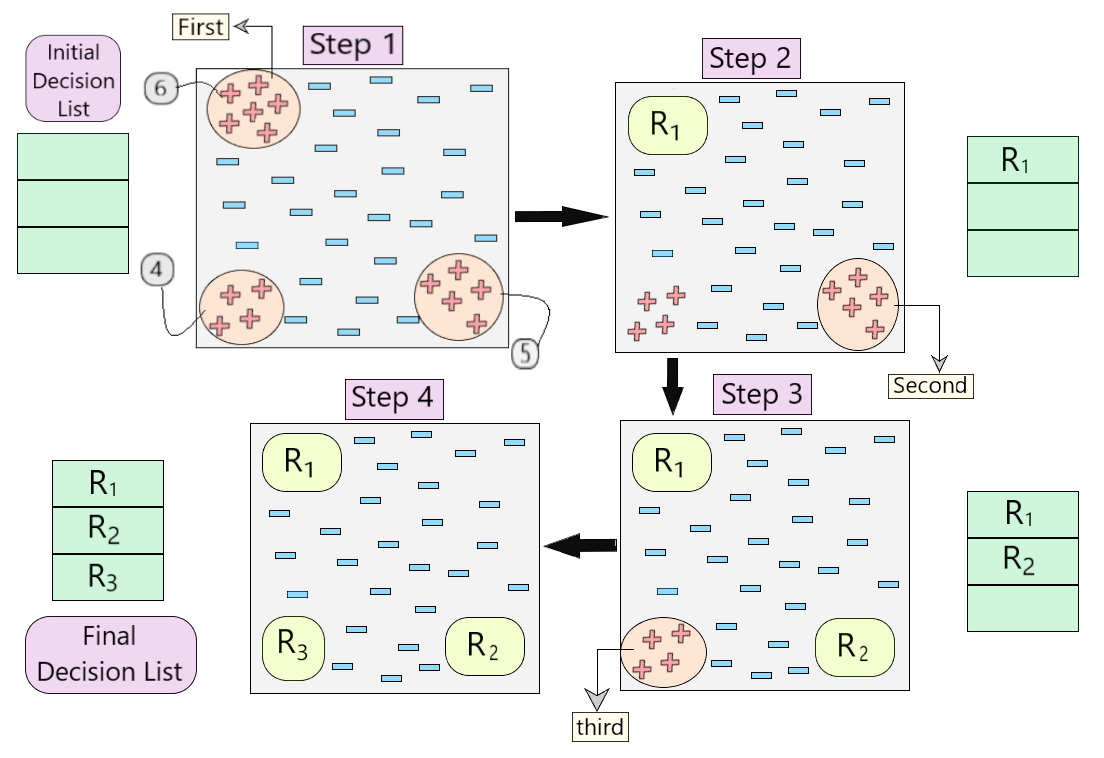
Fig 4: Representación visual del funcionamiento del algoritmo.
- Entendamos paso a paso cómo funciona el algoritmo en el ejemplo que se muestra en la Fig.4.
- Primero, creamos una lista de decisiones vacía. Durante el Paso 1, vemos que hay tres conjuntos de ejemplos positivos presentes en el conjunto de datos. Entonces, según el algoritmo, consideramos el que tiene el número máximo de ejemplos positivos. (6, como se muestra en el Paso 1 de la Fig. 4)
- Una vez que cubrimos estos 6 ejemplos positivos, obtenemos nuestra primera regla R 1 , que luego se incluye en la lista de decisiones y esos ejemplos positivos se eliminan del conjunto de datos. (como se muestra en el Paso 2 de la Fig. 4)
- Ahora, tomamos la siguiente mayoría de ejemplos positivos (5, como se muestra en el Paso 2 de la Fig. 4) y seguimos el mismo proceso hasta obtener la regla R 2 . (Lo mismo para R 3 )
- Al final, obtenemos nuestra lista de decisión final con todas las reglas deseables.
Sequential Learning es un poderoso algoritmo para generar clasificadores basados en reglas en Machine Learning. Utiliza el algoritmo ‘Learn-One-Rule’ como base para aprender una secuencia de reglas disyuntivas. Para dudas/consultas con respecto al algoritmo, comente a continuación.
Publicación traducida automáticamente
Artículo escrito por prakharr0y y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA