Aprendizaje Supervisado:
Es el aprendizaje donde el valor o resultado que queremos predecir está dentro de los datos de entrenamiento (datos etiquetados) y el valor que está en los datos que queremos estudiar se conoce como Variable Objetivo o Variable Dependiente o Variable de Respuesta .
Todas las demás columnas en el conjunto de datos se conocen como característica o variable predictora o variable independiente.
El aprendizaje supervisado se clasifica en dos categorías:
- Clasificación : aquí nuestra variable objetivo consiste en las categorías.
- Regresión : aquí nuestra variable objetivo es continua y generalmente tratamos de encontrar la línea de la curva.
Como hemos entendido, para llevar a cabo el aprendizaje supervisado necesitamos datos etiquetados. ¿Cómo podemos obtener datos etiquetados? Hay varias formas de obtener datos etiquetados:
- Datos históricos etiquetados
- Experimentar para obtener datos: Podemos realizar experimentos para generar datos etiquetados como Pruebas A/B.
- Colaboración colectiva
Ahora es el momento de comprender los algoritmos que se pueden usar para resolver el problema del aprendizaje automático supervisado. En esta publicación, utilizaremos el popular paquete scikit-learn .
Nota: Hay algunos otros paquetes, como TensorFlow, Keras, etc., para realizar el aprendizaje supervisado.
Algoritmo del vecino más cercano:
Este algoritmo se utiliza para resolver los problemas del modelo de clasificación. El algoritmo K-vecino más cercano o K-NN básicamente crea un límite imaginario para clasificar los datos. Cuando ingresan nuevos puntos de datos, el algoritmo intentará predecir eso al más cercano de la línea límite.
Por lo tanto, un valor de k mayor significa curvas de separación más suaves que dan como resultado modelos menos complejos. Mientras que un valor de k más pequeño tiende a sobreajustar los datos y da como resultado modelos complejos.
Nota: Es muy importante tener el valor k correcto al analizar el conjunto de datos para evitar el sobreajuste y el ajuste insuficiente del conjunto de datos.
Usando el algoritmo del vecino más cercano, ajustamos los datos históricos (o entrenamos el modelo) y predecimos el futuro.
Ejemplo del algoritmo del vecino más cercano k
Python3
# Import necessary modules from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split from sklearn.datasets import load_iris # Loading data irisData = load_iris() # Create feature and target arrays X = irisData.data y = irisData.target # Split into training and test set X_train, X_test, y_train, y_test = train_test_split( X, y, test_size = 0.2, random_state=42) knn = KNeighborsClassifier(n_neighbors=7) knn.fit(X_train, y_train) # Predict on dataset which model has not seen before print(knn.predict(X_test))
En el ejemplo que se muestra arriba, se realizan los siguientes pasos:
- El algoritmo del vecino más cercano se importa del paquete scikit-learn.
- Cree características y variables de destino.
- Divida los datos en datos de entrenamiento y de prueba.
- Genere un modelo k-NN utilizando el valor de los vecinos.
- Entrene o ajuste los datos en el modelo.
- Predice el futuro.
Hemos visto cómo podemos usar el algoritmo K-NN para resolver el problema del aprendizaje automático supervisado. Pero, ¿cómo medir la precisión del modelo?
Considere un ejemplo que se muestra a continuación donde predijimos el rendimiento del modelo anterior:
Python3
# Import necessary modules from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split from sklearn.datasets import load_iris # Loading data irisData = load_iris() # Create feature and target arrays X = irisData.data y = irisData.target # Split into training and test set X_train, X_test, y_train, y_test = train_test_split( X, y, test_size = 0.2, random_state=42) knn = KNeighborsClassifier(n_neighbors=7) knn.fit(X_train, y_train) # Calculate the accuracy of the model print(knn.score(X_test, y_test))
Precisión del modelo:
Hasta ahora todo bien. Pero, ¿cómo decidir el valor k correcto para el conjunto de datos? Obviamente, debemos estar familiarizados con los datos para obtener el rango del valor k esperado, pero para obtener el valor k exacto, debemos probar el modelo para todos y cada uno de los valores k esperados. Consulte el ejemplo que se muestra a continuación.
Python3
# Import necessary modules
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import numpy as np
import matplotlib.pyplot as plt
irisData = load_iris()
# Create feature and target arrays
X = irisData.data
y = irisData.target
# Split into training and test set
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.2, random_state=42)
neighbors = np.arange(1, 9)
train_accuracy = np.empty(len(neighbors))
test_accuracy = np.empty(len(neighbors))
# Loop over K values
for i, k in enumerate(neighbors):
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
# Compute training and test data accuracy
train_accuracy[i] = knn.score(X_train, y_train)
test_accuracy[i] = knn.score(X_test, y_test)
# Generate plot
plt.plot(neighbors, test_accuracy, label = 'Testing dataset Accuracy')
plt.plot(neighbors, train_accuracy, label = 'Training dataset Accuracy')
plt.legend()
plt.xlabel('n_neighbors')
plt.ylabel('Accuracy')
plt.show()
Producción:
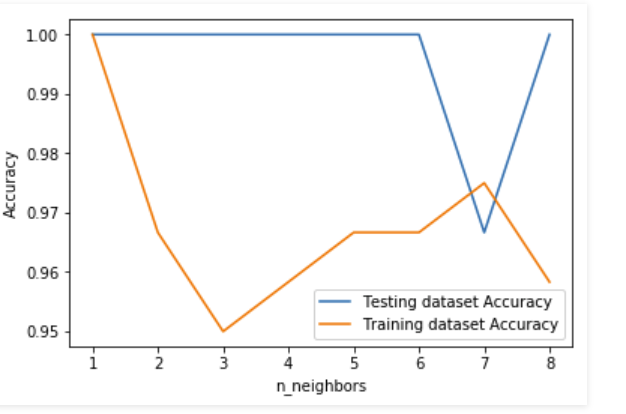
Aquí, en el ejemplo que se muestra arriba, estamos creando un gráfico para ver el valor k para el que tenemos una alta precisión.
Nota: Esta es una técnica que no se usa en toda la industria para elegir el valor correcto de n_neighbors. En su lugar, hacemos un ajuste de hiperparámetros para elegir el valor que ofrece el mejor rendimiento. Cubriremos esto en publicaciones futuras.
Resumen:
en esta publicación, hemos entendido qué es el aprendizaje supervisado y cuáles son sus categorías. Después de tener una comprensión básica del aprendizaje supervisado, exploramos el algoritmo del vecino más cercano que se utiliza para resolver problemas de aprendizaje automático supervisado. También exploramos la medición de la precisión del modelo.
Publicación traducida automáticamente
Artículo escrito por tavishaggarwal1993 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA