Prophet es una herramienta de código abierto de Facebook utilizada para pronosticar datos de series temporales que ayuda a las empresas a comprender y posiblemente predecir el mercado. Se basa en un modelo aditivo descomponible donde las tendencias no lineales se ajustan a la estacionalidad, también tiene en cuenta los efectos de las vacaciones. Antes de pasar directamente a la codificación, aprendamos ciertos términos que se requieren para entender esto.
Tendencia:
La tendencia muestra la tendencia de los datos a aumentar o disminuir durante un largo período de tiempo y filtra las variaciones estacionales.
Estacionalidad:
La estacionalidad son las variaciones que ocurren en un corto período de tiempo y no es lo suficientemente prominente como para llamarse una «tendencia».
Comprender el modelo del profeta
La idea general del modelo es similar a un modelo aditivo generalizado . La «Ecuación del Profeta» se ajusta, como se mencionó anteriormente, a la tendencia, la estacionalidad y las vacaciones. Esto está dado por,
dónde,
- g(t) se refiere a la tendencia (cambios durante un largo período de tiempo)
- s(t) se refiere a la estacionalidad (cambios periódicos o de corto plazo)
- h(t) se refiere a los efectos de las vacaciones en el pronóstico
- e(t) se refiere a los cambios incondicionales que son específicos de una empresa, una persona o una circunstancia. También se le llama término de error.
- y(t) es el pronóstico.
Esto parece bastante fácil, entonces, ¿por qué necesitamos una herramienta como Prophet para ayudarnos con la previsión?
Lo necesitamos porque, aunque el modelo aditivo descomponible básico parece simple, el cálculo de los términos que contiene es tremendamente matemático y, si no sabe lo que está haciendo, puede llevar a hacer pronósticos erróneos que podrían tener graves repercusiones en el mundo real. . Entonces, para automatizar este proceso, vamos a usar Prophet.
Sin embargo, para comprender las matemáticas detrás de este proceso y cómo funciona Prophet en realidad, veamos cómo pronostica los datos.
Prophet nos proporciona dos modelos (sin embargo, los modelos más nuevos se pueden escribir o ampliar según los requisitos específicos). Uno es el modelo de crecimiento logístico y el otro es el modelo lineal por partes.. Por defecto, Prophet usa un modelo lineal por partes, pero se puede cambiar especificando el modelo. La elección de un modelo es delicada ya que depende de una variedad de factores como el tamaño de la empresa, la tasa de crecimiento, el modelo de negocio, etc. Si los datos a pronosticar tienen datos saturados y no lineales (crecen de forma no lineal y después punto de saturación, muestra poco o ningún crecimiento o reducción y solo muestra algunos cambios estacionales), entonces el modelo de crecimiento logístico es la mejor opción. Sin embargo, si los datos muestran propiedades lineales y tuvieron tendencias de crecimiento o reducción en el pasado, entonces, el modelo lineal por partes es una mejor opción.
El modelo de crecimiento logístico se ajusta usando la siguiente ecuación estadística,

dónde,
- C es la capacidad de carga
- k es la tasa de crecimiento
- m es un parámetro de desplazamiento
El modelo lineal por partes se ajusta usando las siguientes ecuaciones estadísticas,

donde c es el punto de cambio de tendencia (define el cambio en la tendencia). ? es un parámetro de tendencia y se puede ajustar según los requisitos para la previsión.
Descargue el conjunto de datos:
ahora usemos este conocimiento con un ejemplo real. Considere el conjunto de datos de pasajeros aéreos (abra el enlace a continuación y guarde el archivo .csv)
https://raw.githubusercontent.com/rahulhegde99/Time-Series-Analysis-and-Forecasting-of-Air-Passengers/master/airpassengers .csv
El conjunto de datos anterior contiene el número de pasajeros aéreos en EE. UU. desde enero de 1949 hasta diciembre de 1960. La frecuencia de los datos es de 1 mes. Ahora intentemos construir un modelo que va a pronosticar el número de pasajeros para los próximos cinco años utilizando el análisis de series de tiempo.
Instalaciones
Instale Pandas para la manipulación de datos y para la estructura de datos del marco de datos.
pip install pandas
Instale Prophet para realizar pronósticos y análisis de series temporales.
pip install fbprophet
Nota: si no desea instalar los módulos localmente, use Jupyter Notebooks o Google Colab.
Implementación:
Código: Importar todos los módulos requeridos
import pandas as pd from fbprophet import Prophet from fbprophet.plot import add_changepoints_to_plot
Código: lea el archivo .csv descargado anteriormente y muéstrelo.
data = pd.read_csv('https://raw.githubusercontent.com/rahulhegde99/Time-Series-Analysis-and-Forecasting-of-Air-Passengers/master/airpassengers.csv')
data.head()
Producción:
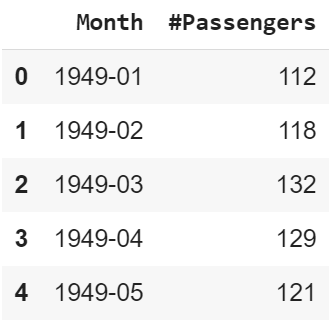
Facebook Prophet predice datos solo cuando están en un formato determinado. El marco de datos con los datos debe tener una columna guardada como ds para datos de series de tiempo e y para los datos a pronosticar. Aquí, la serie temporal es la columna Mes y los datos a pronosticar son la columna #Pasajeros . Entonces, hagamos un nuevo marco de datos con nuevos nombres de columna y los mismos datos. Además, ds debe tener un formato de fecha y hora.
Código:
df = pd.DataFrame() df['ds'] = pd.to_datetime(data['Month']) df['y'] = data['#Passengers'] df.head()
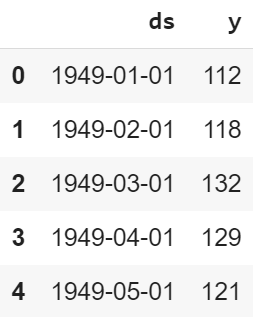
Código: inicializa un modelo y ajusta nuestro dataframe df a él.
m = Prophet() m.fit(df)
Queremos que nuestro modelo prediga para los próximos 5 años, es decir, hasta 1965. La frecuencia de nuestros datos es de 1 mes y, por lo tanto, para 5 años, es 12*5=60 meses. Por lo tanto, debemos agregar de 60 a más filas de datos mensuales a un marco de datos.
Código:
future = m.make_future_dataframe(periods=12 * 5, freq='M')
Ahora, en el marco de datos futuro , solo tenemos valores ds y debemos predecir los valores y .
Código:
forecast = m.predict(future) forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper', 'trend', 'trend_lower', 'trend_upper']].tail()
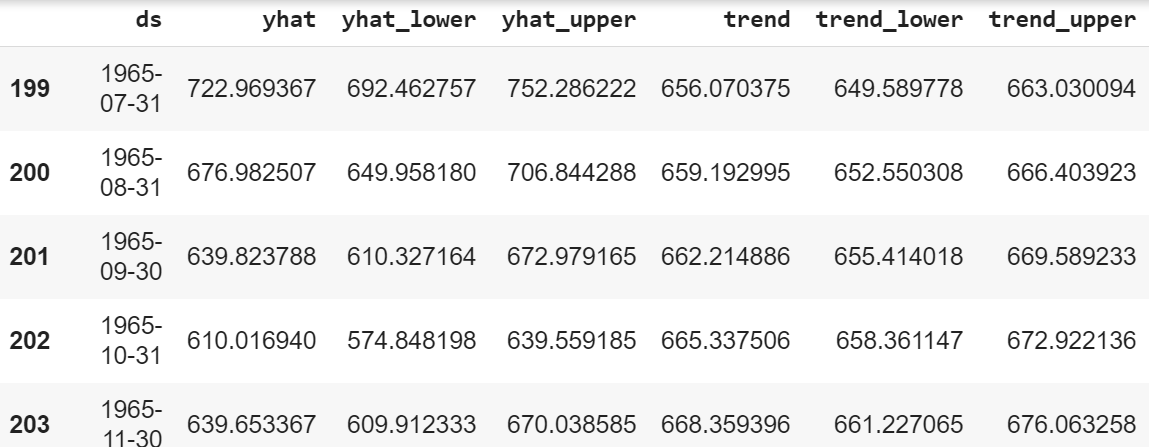
En la tabla ds , como sabemos, se encuentran los datos de la serie temporal. ycuál es la predicción, yhat_lower y yhat_upper son los niveles de incertidumbre (básicamente significa que la predicción y los valores reales pueden variar dentro de los límites de los niveles de incertidumbre). A continuación tenemos la tendencia que muestra el crecimiento a largo plazo, la reducción o el estancamiento de los datos, trend_lower y trend_upper son los niveles de incertidumbre.
Código: Trazar los datos pronosticados.
fig1 = m.plot(forecast)
La siguiente imagen muestra la predicción básica. El azul claro es el nivel de incertidumbre ( yhat_upper y yhat_lower ), el azul oscuro es la predicción ( yhat ) y los puntos negros son los datos originales. Podemos ver que los datos predichos están muy cerca de los datos reales. En los últimos cinco años, no hay datos «reales», pero al observar el rendimiento de nuestro modelo en los años en los que hay datos disponibles, es seguro decir que las predicciones son casi precisas.
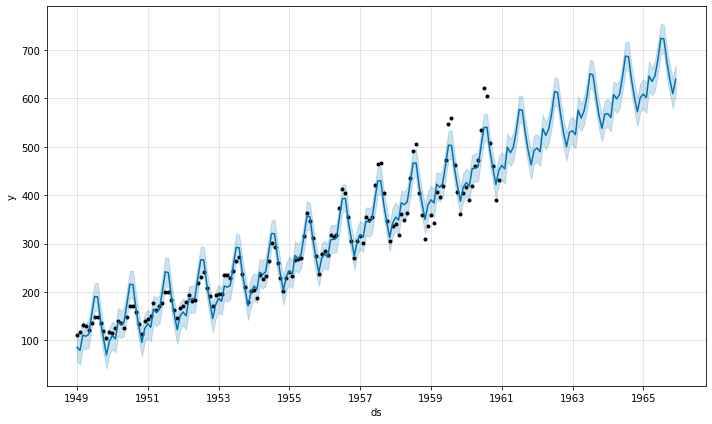
fig2 = m.plot_components(forecast)
Las siguientes imágenes muestran las tendencias y la estacionalidad (en un año) de los datos de la serie temporal. Podemos ver que hay una tendencia creciente, lo que significa que la cantidad de pasajeros aéreos ha aumentado con el tiempo. Si miramos el gráfico de estacionalidad, podemos ver que junio y julio es la época con más pasajeros en un año determinado.
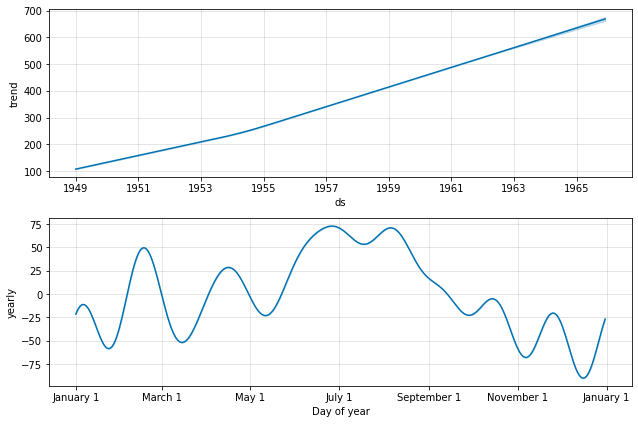
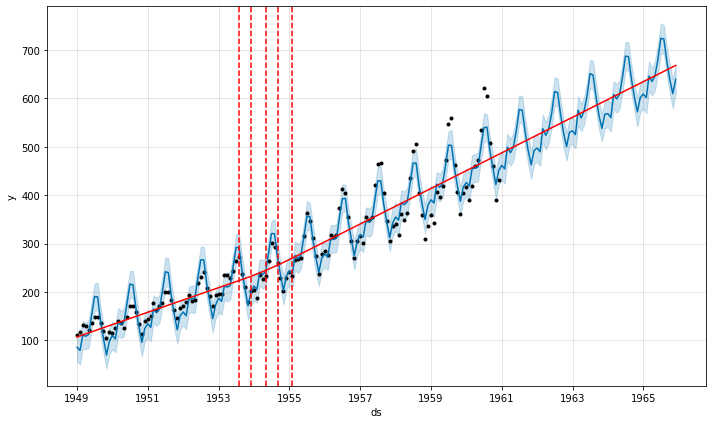
fig = m.plot(forecast) a = add_changepoints_to_plot(fig.gca(), m, forecast)
Agregue puntos de cambio para indicar el tiempo en rápidos crecimientos de tendencia. Las líneas rojas punteadas muestran el momento en que hubo un cambio rápido en la tendencia de los pasajeros.
Notas al pie:
Por lo tanto, hemos visto cómo podemos diseñar un modelo de predicción usando Facebook Prophet con solo unas pocas líneas de código que habría sido muy difícil de implementar utilizando solo los algoritmos tradicionales de aprendizaje automático y los conceptos matemáticos y estadísticos.
Publicación traducida automáticamente
Artículo escrito por rahulhegde97 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA