En este artículo, discutiremos los datos de Analyze Covid-19 y los visualizaremos usando Plotly Express en Python. Este artículo trata sobre la creación de docenas de gráficos de barras, gráficos de líneas, gráficos de burbujas, diagramas de dispersión. La gráfica que se realizará en este proyecto será de excelente calidad. Envisioning COVID-19 utilizará principalmente Plotly Express para este proyecto. El análisis y la visualización permiten a las personas comprender escenarios complejos y hacer predicciones sobre el futuro a partir de la situación actual.
Este análisis resume el trabajo de modelado, simulación y análisis en torno al brote de COVID-19 en todo el mundo desde la perspectiva de la ciencia de datos y el análisis visual. Examina el impacto de las mejores prácticas y medidas preventivas en varios sectores y permite gestionar los brotes con los recursos sanitarios disponibles.
Herramientas y Tecnologías Utilizadas en el Proyecto: Google Colab (Tipo Runtime – GPU).
Requisitos para construir el proyecto:
- Conocimientos básicos de Python
- Comprensión básica de gráficos y tablas.
- Visualización de datos
- pandas
- entumecido
- matplotlib
- Expreso gráfico
- coropleta
- Nube de palabras
Implementación paso a paso
Paso 1: Importación de bibliotecas necesarias
La tarea es simple, una vez que la instalación de todas las bibliotecas requeridas sea exitosa, deben importarse al espacio de trabajo, ya que proporcionarán el soporte adicional para el análisis y la visualización.
Ejemplo: importar bibliotecas
Python3
# Data analysis and Manipulation import plotly.graph_objs as go import plotly.io as pio import plotly.express as px import pandas as pd # Data Visualization import matplotlib.pyplot as plt # Importing Plotly import plotly.offline as py py.init_notebook_mode(connected=True) # Initializing Plotly pio.renderers.default = 'colab'
Paso 2: Importación de los conjuntos de datos
Importación de tres conjuntos de datos en este proyecto
- covid : este conjunto de datos contiene País/Región, Continente, Población, TotalCases, NewCases, TotalDeaths, NewDeaths, TotalRecovered, NewRecovered, ActiveCases, Serious, Critical, Tot Cases/1M pop, Deaths/1M pop, TotalTests, Tests/1M pop, WHO Región, iso_alpha.
- covid_grouped : este conjunto de datos contiene Fecha (del 20-01-22 al 20-07-27), País/Región, Confirmado, Muertes, Recuperado, Activo, Casos nuevos, Muertes nuevas, Recuperado nuevo, Región de la OMS, iso_alpha.
- coviddeath : este conjunto de datos contiene ejemplos del mundo real de varias muertes por Covid-19 y las razones detrás de las muertes.
Para importar conjuntos de datos al espacio de trabajo, se puede usar el método pandas read_csv().
Sintaxis:
read_csv(ruta)
Ejemplo: importar conjuntos de datos
Python3
# Importing Dataset1
dataset1 = pd.read_csv("covid.csv")
dataset1.head() # returns first 5 rows
Producción:

Además, la información sobre el conjunto de datos que estamos utilizando nos ayudará a muestrearlo mejor para el análisis.
Ejemplo: obtener información del conjunto de datos
Python3
# Returns tuple of shape (Rows, columns) print(dataset1.shape) # Returns size of dataframe print(dataset1.size)
Producción:
(209, 17) 3553
Ejemplo: información del conjunto de datos
Python3
# Information about Dataset1 # return concise summary of dataframe dataset1.info()
Producción:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 209 entries, 0 to 208 Data columns (total 17 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Country/Region 209 non-null object 1 Continent 208 non-null object 2 Population 208 non-null float64 3 TotalCases 209 non-null int64 4 NewCases 4 non-null float64 5 TotalDeaths 188 non-null float64 6 NewDeaths 3 non-null float64 7 TotalRecovered 205 non-null float64 8 NewRecovered 3 non-null float64 9 ActiveCases 205 non-null float64 10 Serious,Critical 122 non-null float64 11 Tot Cases/1M pop 208 non-null float64 12 Deaths/1M pop 187 non-null float64 13 TotalTests 191 non-null float64 14 Tests/1M pop 191 non-null float64 15 WHO Region 184 non-null object 16 iso_alpha 209 non-null object dtypes: float64(12), int64(1), object(4) memory usage: 27.9+ KB
De manera similar, se pueden importar y explorar otros conjuntos de datos.
Ejemplo: Importando conjunto de datos
Python3
# Importing Dataset2
dataset2 = pd.read_csv("covid_grouped.csv")
dataset2.head() # return first 5 rows of dataset2
Producción:

Ejemplo: Obtener información del conjunto de datos
Python3
# Returns tuple of shape (Rows, columns) print(dataset2.shape) # Returns size of dataframe print(dataset2.size)
Producción:
(35156, 11) 386716
Ejemplo: información del conjunto de datos
Python3
# Information about Dataset2 dataset2.info() # return concise summary of dataframe
Producción:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 35156 entries, 0 to 35155 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Date 35156 non-null object 1 Country/Region 35156 non-null object 2 Confirmed 35156 non-null int64 3 Deaths 35156 non-null int64 4 Recovered 35156 non-null int64 5 Active 35156 non-null int64 6 New cases 35156 non-null int64 7 New deaths 35156 non-null int64 8 New recovered 35156 non-null int64 9 WHO Region 35156 non-null object 10 iso_alpha 35156 non-null object dtypes: int64(7), object(4) memory usage: 3.0+ MB
Paso 3: limpieza del conjunto de datos
La limpieza de datos es el proceso de alterar, modificar un conjunto de registros, corregir registros erróneos de la base de datos e identificar partes incompletas, incorrectas o irrelevantes de los datos, y luego eliminar los datos sucios.
Ejemplo: Obtención de columnas de conjuntos de datos
Python3
# Columns labels of a Dataset1 dataset1.columns
Producción:
Index([‘País/Región’, ‘Continente’, ‘Población’, ‘TotalCasos’, ‘NuevosCasos’, ‘TotalMuertes’, ‘NuevasMuertes’, ‘TotalRecuperado’, ‘NuevoRecuperado’, ‘CasosActivos’, ‘Grave,Crítico’ , ‘Tot Cases/1M pop’, ‘Deaths/1M pop’, ‘TotalTests’, ‘Pruebas/1M pop’, ‘WHO Region’, ‘iso_alpha’], dtype=’object’)
No necesitamos las columnas ‘NewCases’, ‘NewDeaths’, ‘NewRecovered’ ya que contienen valores NaN. Así que suelta estas columnas con la función drop() de pandas.
Sintaxis:
drop (nombre de las columnas)
Ejemplo: limpieza del marco de datos
Python3
# Drop NewCases, NewDeaths, NewRecovered rows from dataset1 dataset1.drop(['NewCases', 'NewDeaths', 'NewRecovered'], axis=1, inplace=True) # Select random set of values from dataset1 dataset1.sample(5)
Producción:

Vamos a crear una tabla a través de la función de tabla ya disponible en plotly express.
Ejemplo: Crear una tabla usando plotly express
Python3
# Import create_table Figure Factory from plotly.figure_factory import create_table colorscale = [[0, '#4d004c'], [.5, '#f2e5ff'], [1, '#ffffff']] table = create_table(dataset1.head(15), colorscale=colorscale) py.iplot(table)
Producción:

Paso 4: Gráficos de barras: comparaciones entre países infectados con COVID en términos de casos totales, muertes totales, recuperaciones totales y pruebas totales
Usando una línea de código, crearemos gráficos asombrosos usando Plotly Express. La visualización se puede hacer fácilmente moviendo el cursor en cualquier gráfico, podemos obtener el punto de presencia de la etiqueta directamente usando el cursor. Podemos visualizar y analizar el conjunto de datos con cada aspecto usando la relación entre las columnas.
Mire principalmente el país con respecto a un número total de casos solo por los 15 países principales y coloree los casos totales y los datos flotantes como ‘País/Región’, ‘Continente’.
Ejemplo: gráfico de barras
Python3
px.bar(dataset1.head(15), x = 'Country/Region', y = 'TotalCases',color = 'TotalCases', height = 500,hover_data = ['Country/Region', 'Continent'])
Producción:

Como el gráfico muestra claramente los datos de los 15 países principales, ahora tome nuevamente el país con respecto al número total de casos de los 15 países principales, coloree los datos de las muertes totales como ‘País/Región’, ‘Continente’ y analice la visualización
Ejemplo: gráfico de barras
Python3
px.bar(dataset1.head(15), x = 'Country/Region', y = 'TotalCases', color = 'TotalDeaths', height = 500, hover_data = ['Country/Region', 'Continent'])
Producción:

Analicemos coloreando el número total de casos recuperados
Ejemplo: gráfico de barras
Python3
px.bar(dataset1.head(15), x = 'Country/Region', y = 'TotalCases', color = 'TotalDeaths', height = 500, hover_data = ['Country/Region', 'Continent'])
Producción:

Visualice lo mismo nuevamente coloreando el número total de pruebas.
Ejemplo: gráfico de barras
Python3
px.bar(dataset1.head(15), x = 'Country/Region', y = 'TotalCases', color = 'TotalTests', height = 500, hover_data = ['Country/Region', 'Continent'])
Producción:

La visualización podría ser como la que hemos hecho con los 15 principales países con casos totales, muertes, recuperaciones y pruebas. Podemos analizar la trama mirándolos.
Vamos a crear un gráfico de orientación horizontal con el eje X como ‘TotalTests’ y el eje Y como ‘País/Región’ con el parámetro de paso orientación=”h” y colorear el gráfico por ‘TotalTests’.
Ejemplo: gráfico de barras
Python3
px.bar(dataset1.head(15), x = 'TotalTests', y = 'Country/Region', color = 'TotalTests',orientation ='h', height = 500, hover_data = ['Country/Region', 'Continent'])
Producción:

Veamos ‘TotalTests’ seguido de ‘Continent’ y coloreemos la gráfica con ‘Continent’.
Ejemplo: gráfico de barras
Python3
px.bar(dataset1.head(15), x = 'TotalTests', y = 'Continent', color = 'TotalTests',orientation ='h', height = 500, hover_data = ['Country/Region', 'Continent'])
Producción:
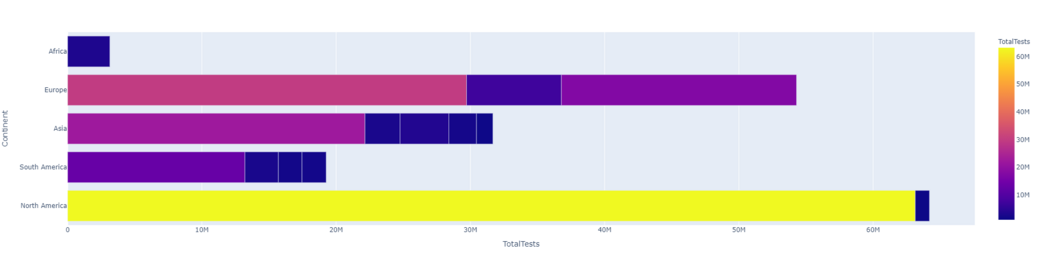
Total de pruebas y continentes (orientación horizontal)
Paso 5: Visualización de datos a través de gráficos de burbujas-Continent Wise
Vamos a crear un gráfico de dispersión y echar un vistazo a las estadísticas del continente, primero miremos el número total de casos por continente y tomemos los datos flotantes como ‘País/Región’, ‘Continente’.
Ejemplo: diagrama de dispersión
Python3
px.scatter(dataset1, x='Continent',y='TotalCases', hover_data=['Country/Region', 'Continent'], color='TotalCases', size='TotalCases', size_max=80)
Producción:

log_y= Cierto, el eje del histograma (no el parámetro devuelto) está en escala logarítmica. El parámetro de retorno (n, contenedores), es decir, los valores de los contenedores y los lados de los contenedores son los mismos para log=True y log=False. Esto significa que tanto n==n2 como bins==bins2 son verdaderos
Ejemplo: diagrama de dispersión
Python3
px.scatter(dataset1.head(57), x='Continent',y='TotalCases', hover_data=['Country/Region', 'Continent'], color='TotalCases', size='TotalCases', size_max=80, log_y=True)
Producción:

Ejemplo: diagrama de dispersión
Python3
px.scatter(dataset1.head(54), x='Continent',y='TotalTests', hover_data=['Country/Region', 'Continent'], color='TotalTests', size='TotalTests', size_max=80)
Producción:

Ejemplo: diagrama de dispersión
Python3
px.scatter(dataset1.head(50), x='Continent',y='TotalTests', hover_data=['Country/Region', 'Continent'], color='TotalTests', size='TotalTests', size_max=80, log_y=True)
Producción:

Paso 6: Visualización de datos a través de gráficos de burbujas-Country Wise
Echemos un vistazo a la visualización de datos por país, primero mire el continente con respecto al número total de muertes solo por los 50 países principales y coloree el número total de muertes y tome los datos flotantes como ‘País/Región’, ‘Continente’.
Ejemplo: gráfico de burbujas
Python3
px.scatter(dataset1.head(100), x='Country/Region', y='TotalCases', hover_data=['Country/Region', 'Continent'], color='TotalCases', size='TotalCases', size_max=80)
Producción:

Ahora, el país/región con respecto al número total de casos solo para los 30 países principales y coloree el número total de casos y tome los datos flotantes como ‘País/Región’, ‘Continente’.
Ejemplo : gráfico de burbujas
Python3
px.scatter(dataset1.head(30), x='Country/Region', y='TotalCases', hover_data=['Country/Region', 'Continent'], color='Country/Region', size='TotalCases', size_max=80, log_y=True)
Producción:

Ahora formatee la imagen del país/región en relación con el número total de muertes. Y haga lo mismo con los otros aspectos de COVID-19 del conjunto de datos 1.
Ejemplo: gráfico de burbujas
Python3
px.scatter(dataset1.head(10), x='Country/Region', y= 'TotalDeaths', hover_data=['Country/Region', 'Continent'], color='Country/Region', size= 'TotalDeaths', size_max=80)
Producción:

Ejemplo: gráfico de burbujas
Python3
px.scatter(dataset1.head(30), x='Country/Region', y= 'Tests/1M pop', hover_data=['Country/Region', 'Continent'], color='Country/Region', size= 'Tests/1M pop', size_max=80)
Producción:

Ejemplo: País/Región VS Pruebas/1M de habitantes (escala de color de Pruebas/1M de habitantes)
Python3
px.scatter(dataset1.head(30), x='Country/Region', y= 'Tests/1M pop', hover_data=['Country/Region', 'Continent'], color='Tests/1M pop', size= 'Tests/1M pop', size_max=80)
Producción:

Ejemplo: gráfico de burbujas
Python3
px.scatter(dataset1.head(30), x='TotalCases', y= 'TotalDeaths', hover_data=['Country/Region', 'Continent'], color='TotalDeaths', size= 'TotalDeaths', size_max=80)
Producción:

Del resultado se desprende claramente que tienen una relación lineal entre el número total de casos y el número total de muertes. Eso significa más casos, más muertes.
Ejemplo: gráfico de burbujas
Python3
px.scatter(dataset1.head(30), x='TotalCases', y= 'TotalDeaths', hover_data=['Country/Region', 'Continent'], color='TotalDeaths', size= 'TotalDeaths', size_max=80, log_x=True, log_y=True)
Producción:
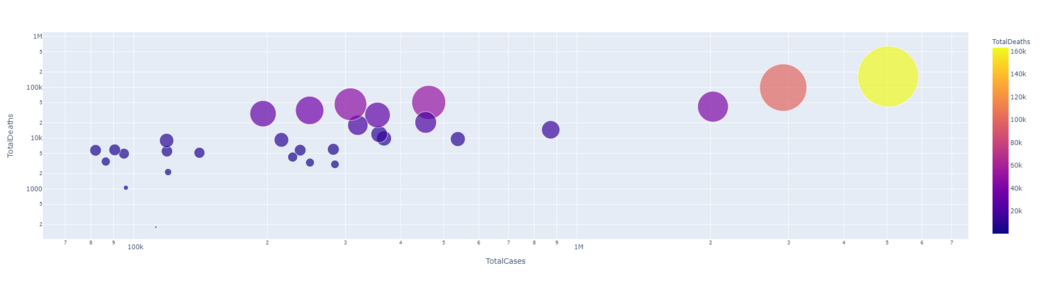
TotalCases VS TotalDeaths (con log_y=True)
Ejemplo: gráfico de burbujas
Python3
px.scatter(dataset1.head(30), x='TotalTests', y= 'TotalCases', hover_data=['Country/Region', 'Continent'], color='TotalTests', size= 'TotalTests', size_max=80, log_x=True, log_y=True)
Producción:
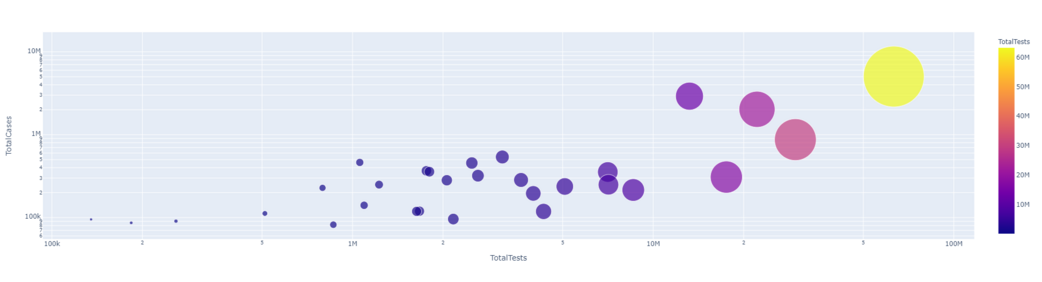
PruebasTotales VS CasosTotales
Paso 7: visualización avanzada de datos: gráficos de barras para todos los principales países infectados
En esta tarea, exploraremos los datos de covid-19 usando gráficos de barras y tablas y usaremos dataset2 ya que tiene una columna de fecha.
Ejemplo: gráfico de barras
Python3
px.bar(dataset2, x="Date", y="Confirmed", color="Confirmed", hover_data=["Confirmed", "Date", "Country/Region"], height=400)
Producción:

El gráfico anterior lo obtenemos como salida que incluye todos los países con respecto a los casos recuperados. podemos imaginar el crecimiento exponencial de los casos de corona por fecha. Podemos usar la función de registro para que esto sea más claro.
Ejemplo: gráfico de barras
Python3
px.bar(dataset2, x="Date", y="Confirmed", color="Confirmed", hover_data=["Confirmed", "Date", "Country/Region"],log_y=True, height=400)
Producción:

Imaginemos la muerte en lugar de la confirmación con el mismo y coloréelo por fecha.
Ejemplo: gráfico de barras
Python3
px.bar(dataset2, x="Date", y="Deaths", color="Deaths", hover_data=["Confirmed", "Date", "Country/Region"], log_y=False, height=400)
Producción:

Paso 8: Visualización de datos de COVID específicos de países: (Estados Unidos)
En esta tarea específica, analizaremos los datos del país de EE. UU.
Ejemplo: refinar el conjunto de datos para obtener solo datos de EE. UU.
Python3
df_US= dataset2.loc[dataset2["Country/Region"]=="US"]
Ahora tracemos y estudiemos la situación del covid en los Estados Unidos.
Ejemplo: gráfico de barras
Python3
px.bar(df_US, x="Date", y="Confirmed", color="Confirmed", height=400)
Producción:

Aquí podemos ver claramente cómo aumentaron los casos confirmados en Estados Unidos con respecto al tiempo (enero 2020 a julio 2020). Del mismo modo, podemos consultar lo mismo para casos recuperados, pruebas y muertes.
Ejemplo: gráfico de barras
Python3
px.bar(df_US,x="Date", y="Recovered", color="Recovered", height=400)
Producción:

Del mismo modo, podemos analizar los datos en todas las formas para generar el gráfico de líneas para el mismo.
Ejemplo : gráfico de líneas
Python3
px.line(df_US,x="Date", y="Recovered", height=400)
Producción:

Ejemplo : gráfico de líneas
Python3
px.line(df_US,x="Date", y="Deaths", height=400)
Producción:

Ejemplo : gráfico de líneas
Python3
px.line(df_US,x="Date", y="Confirmed", height=400)
Producción:

Ejemplo : gráfico de líneas
Python3
px.line(df_US,x="Date", y="New cases", height=400)
Producción:

Ahora vamos a crear gráficos de barras y estudiar la situación de EE. UU. usando eso.
Ejemplo: gráfico de barras
Python3
px.bar(df_US,x="Date", y="New cases", height=400)
Producción:

Del mismo modo, tracemos también un diagrama de líneas.
Ejemplo: diagrama de dispersión
Python3
px.scatter(df_US, x="Confirmed", y="Deaths", height=400)
Producción:

Paso 9: Visualización de Datos en términos de Mapas
Podemos usar la coropleta para visualizar los datos en términos de mapas, siendo los mapas la forma predominante de visualizar los datos. Dado que COVID-19 es un fenómeno global, lo analizamos y lo solucionamos en términos de mapas de pared. Proyección ortográfica, rectangular y natural de la tierra para visualizar los datos Con dataset2 para el propósito ya que tiene la columna Fechas. Examinará el crecimiento de Covid-19 (de enero a julio de 2020) y cómo el virus llegó a todo el mundo.
Choropleth es una asombrosa representación de datos en un mapa. Los mapas de coropletas proporcionan una manera fácil de visualizar cómo varía una medida a lo largo de un área geográfica.
El mapa de coropletas de Project Application in Real muestra áreas o regiones geográficas divididas que están coloreadas, sombreadas o modeladas en relación con una variable de datos.
Proyección Equi-rectangular:
Sintaxis: cloropleth()
parámetros:
- conjunto de datos
- ubicaciones= ISOALFA
- color
- hover_name
- color_continuous_scale= [RdYlGn, Blues, Viridis…]
- animation_frame= Fecha
Ejemplo: Crear mapa
Python3
px.choropleth(dataset2, locations="iso_alpha", color="Confirmed", hover_name="Country/Region", color_continuous_scale="Blues", animation_frame="Date")
Producción:
Esto crea una animación que contiene visualizaciones de enero a julio de 2020. Al reproducir esta animación, quedará más claro cómo se propagó el virus en todo el mundo. Cuanto más oscuro es el color, más altos son los casos confirmados.
Ejemplo: Crear mapa
Python3
px.choropleth(dataset2, locations='iso_alpha', color="Deaths", hover_name="Country/Region", color_continuous_scale="Viridis", animation_frame="Date" )
Producción:
Este código crea una animación de casos de muerte por fecha. Al reproducir esta animación se mostrará cómo aumentan las muertes en todo el mundo.
La proyección Natural Earth es una proyección de mapa pseudocilíndrica de compromiso para mapas del mundo.
Ejemplo: Proyección natural de la tierra
Python3
px.choropleth(dataset2, locations='iso_alpha', color="Recovered", hover_name="Country/Region", color_continuous_scale="RdYlGn", projection="natural earth", animation_frame="Date" )
Producción:
Al ejecutar la salida, las cosas comienzan a quedar más claras acerca de cómo cambia la tasa de recuperación con respecto a la fecha. Veamos también cómo se puede agregar una animación a un gráfico de barras. Podemos convertir el gráfico de barras en animación usando la columna Fechas que se encuentra en dataset2.
Ejemplo: animación de gráfico de barras
Python3
px.bar(dataset2, x="WHO Region", y="Confirmed", color="WHO Region", animation_frame="Date", hover_name="Country/Region")
Producción:
Al ejecutar la salida, la animación se ejecutará de enero a julio de 2020. Mostrará 6 gráficos de barras diferentes, cada continente tiene su propio color que representa los casos confirmados.
Paso 10: Visualiza el texto usando Word Cloud
Visualice las causas de muerte por covid-19, ya que covid-19 afecta a las personas de diferentes maneras, por lo tanto, cree una nube de palabras para visualizar la principal causa de muerte por covid-19. Para visualizar el texto, los pasos que se deben seguir son:
- Se utiliza para convertir elementos de datos de una array en una lista.
- Convierta la string en una sola string.
- Convierte la string en una nube de palabras
Conjunto de datos 3: este conjunto de datos contiene ejemplos del mundo real de la cantidad de muertes por Covid-19 y las razones detrás de las muertes.
Ejemplo: importar un conjunto de datos
Python3
dataset3= pd.read_csv("covid+death.csv")
dataset3.head()
Producción:

Ejemplo: información del conjunto de datos
Python3
dataset3.tail()
Producción:

Ejemplo: Obtener información del conjunto de datos
Python3
dataset3.groupby(["Condition"]).count()
Producción:
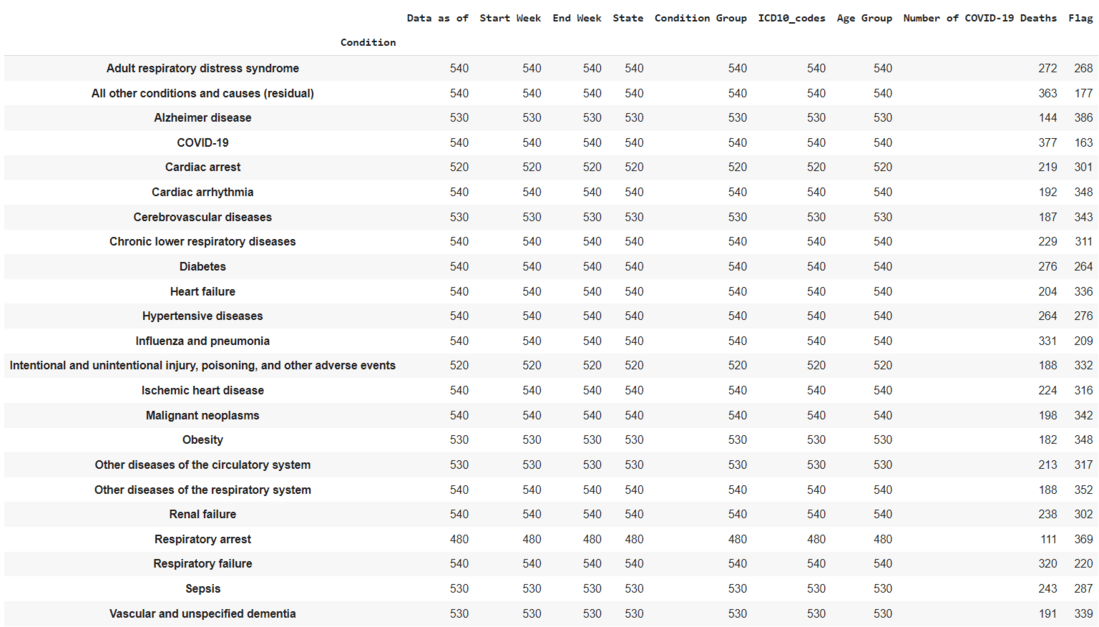
Condiciones
Ejemplo: creación de una nube de palabras
Python3
# import word cloud from wordcloud import WordCloud sentences = dataset3["Condition"].tolist() sentences_as_a_string = ' '.join(sentences) # Convert the string into WordCloud plt.figure(figsize=(20, 20)) plt.imshow(WordCloud().generate(sentences_as_a_string))
Producción:

De la salida, se puede ver claramente que la principal causa de muerte es la neumonía por influenza. Hemos convertido el grupo de condiciones a la lista y almacenado la lista en la variable «column_to_list». Aquí hemos convertido la lista en una sola string y la hemos almacenado en una variable llamada «column2_to_string» usando .join().
Ejemplo: creación de una nube de palabras
Python3
column2_tolist= dataset3["Condition Group"].tolist() # Convert the list to one single string column_to_string= " ".join(column2_tolist) # Convert the string into WordCloud plt.figure(figsize=(20,20)) plt.imshow(WordCloud().generate(column_to_string))
Producción:

Aquí, las enfermedades respiratorias son la principal causa de muerte, seguidas de las enfermedades circulatorias, que son las enfermedades cardiovasculares.
Publicación traducida automáticamente
Artículo escrito por tanushree7252 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA