La visualización de datos es la presentación de datos en formato gráfico. Ayuda a las personas a comprender la importancia de los datos al resumir y presentar una gran cantidad de datos en un formato simple y fácil de entender y ayuda a comunicar la información de manera clara y efectiva.
Considere este conjunto de datos dado para el cual trazaremos diferentes gráficos: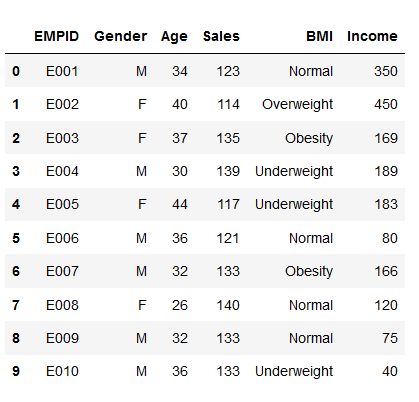
1. Histograma:
El histograma representa la frecuencia de ocurrencia de fenómenos específicos que se encuentran dentro de un rango específico de valores y están dispuestos en intervalos fijos y consecutivos.
En el siguiente código, el histograma se traza para Age, Income, Sales. Entonces, estas gráficas en la salida muestran la frecuencia de cada valor único para cada atributo.
# import pandas and matplotlib import pandas as pd import matplotlib.pyplot as plt # create 2D array of table given above data = [['E001', 'M', 34, 123, 'Normal', 350], ['E002', 'F', 40, 114, 'Overweight', 450], ['E003', 'F', 37, 135, 'Obesity', 169], ['E004', 'M', 30, 139, 'Underweight', 189], ['E005', 'F', 44, 117, 'Underweight', 183], ['E006', 'M', 36, 121, 'Normal', 80], ['E007', 'M', 32, 133, 'Obesity', 166], ['E008', 'F', 26, 140, 'Normal', 120], ['E009', 'M', 32, 133, 'Normal', 75], ['E010', 'M', 36, 133, 'Underweight', 40] ] # dataframe created with # the above data array df = pd.DataFrame(data, columns = ['EMPID', 'Gender', 'Age', 'Sales', 'BMI', 'Income'] ) # create histogram for numeric data df.hist() # show plot plt.show()
Salida: 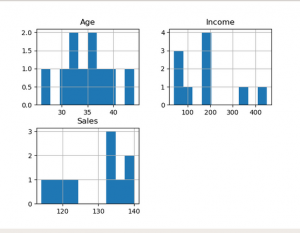
2. Gráfico de columnas:
un gráfico de columnas se utiliza para mostrar una comparación entre diferentes atributos, o puede mostrar una comparación de elementos a lo largo del tiempo.
# Dataframe of previous code is used here
# Plot the bar chart for numeric values
# a comparison will be shown between
# all 3 age, income, sales
df.plot.bar()
# plot between 2 attributes
plt.bar(df['Age'], df['Sales'])
plt.xlabel("Age")
plt.ylabel("Sales")
plt.show()
Salida: 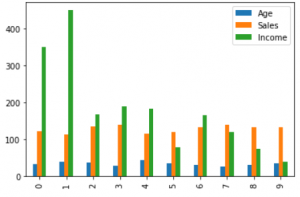
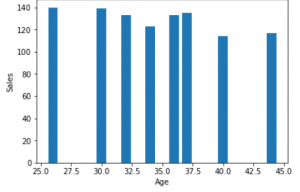
3. Gráfico de diagrama de caja:
Un diagrama de caja es una representación gráfica de datos estadísticos basada en el minimum, first quartile, median, third quartile, and maximum. El término «diagrama de caja» proviene del hecho de que el gráfico se ve como un rectángulo con líneas que se extienden desde la parte superior e inferior. Debido a las líneas que se extienden, este tipo de gráfico a veces se denomina diagrama de caja y bigotes. Para el cuantil y la mediana, consulte este cuantil y la mediana .
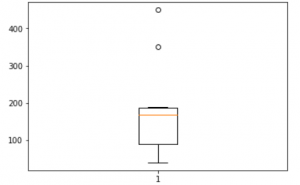
# For each numeric attribute of dataframe df.plot.box() # individual attribute box plot plt.boxplot(df['Income']) plt.show()
Salida: 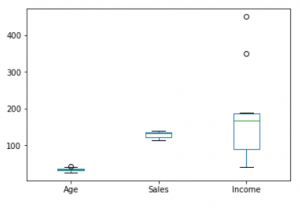
4. Gráfico circular:
un gráfico circular muestra un número estático y cómo las categorías representan parte de un todo, la composición de algo. Un gráfico circular representa números en porcentajes, y la suma total de todos los segmentos debe ser igual al 100 %.
plt.pie(df['Age'], labels = {"A", "B", "C",
"D", "E", "F",
"G", "H", "I", "J"},
autopct ='% 1.1f %%', shadow = True)
plt.show()
plt.pie(df['Income'], labels = {"A", "B", "C",
"D", "E", "F",
"G", "H", "I", "J"},
autopct ='% 1.1f %%', shadow = True)
plt.show()
plt.pie(df['Sales'], labels = {"A", "B", "C",
"D", "E", "F",
"G", "H", "I", "J"},
autopct ='% 1.1f %%', shadow = True)
plt.show()
Salida: 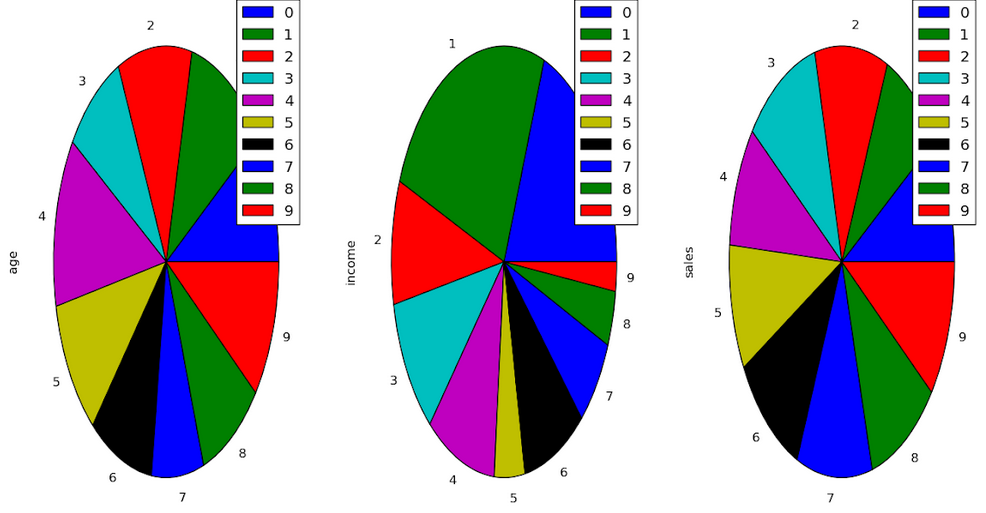
5. Gráfico de dispersión:
un gráfico de dispersión muestra la relación entre dos variables diferentes y puede revelar las tendencias de distribución. Debe usarse cuando hay muchos puntos de datos diferentes y desea resaltar similitudes en el conjunto de datos. Esto es útil cuando se buscan valores atípicos y para comprender la distribución de sus datos.
# scatter plot between income and age plt.scatter(df['income'], df['age']) plt.show() # scatter plot between income and sales plt.scatter(df['income'], df['sales']) plt.show() # scatter plot between sales and age plt.scatter(df['sales'], df['age']) plt.show()
Producción :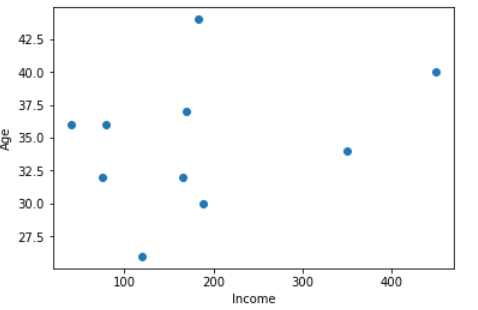
Publicación traducida automáticamente
Artículo escrito por Mohityadav y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA