Apilamiento:
el apilamiento es una forma de ensamblar modelos de clasificación o regresión; consiste en estimadores de dos capas. La primera capa consta de todos los modelos de referencia que se utilizan para predecir los resultados en los conjuntos de datos de prueba. La segunda capa consta de Meta-Classifier o Regressor que toma todas las predicciones de los modelos de referencia como entrada y genera nuevas predicciones.
Arquitectura de apilamiento:
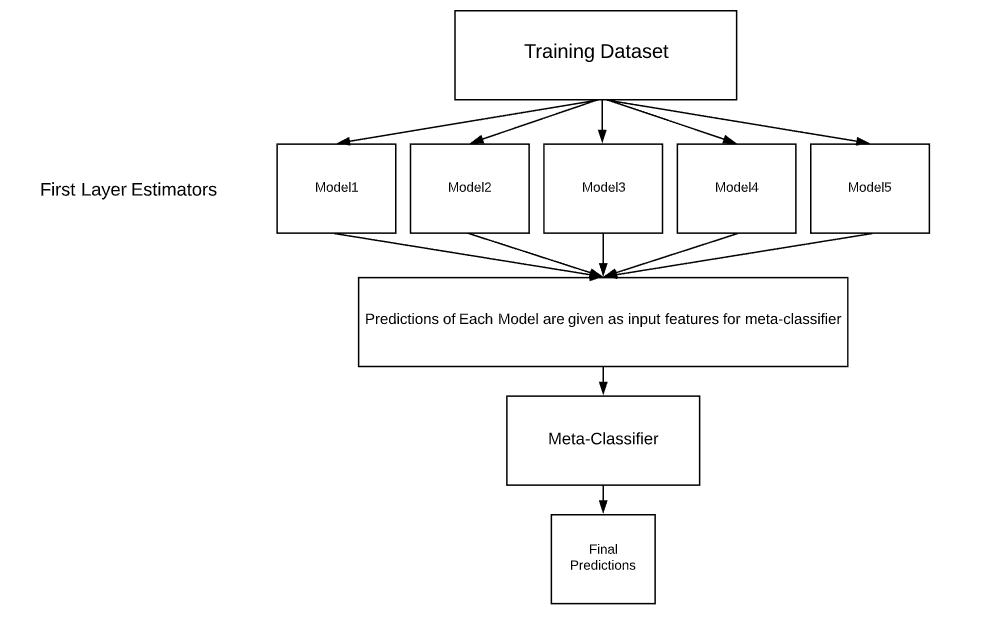
Arquitectura de apilamiento
mlxtend:
Mlxtend (extensiones de aprendizaje automático) es una biblioteca Python de herramientas útiles para las tareas diarias de ciencia de datos. Consta de muchas herramientas que son útiles para tareas de ciencia de datos y aprendizaje automático, por ejemplo:
- Selección de características
- Extracción de características
- Visualización
- Ensamblaje
y muchos más.
Este artículo explica cómo implementar Stacking Classifier en el conjunto de datos de clasificación.
¿Por qué apilar?
La mayoría de las competencias de ciencia de datos y aprendizaje automático se ganan mediante el uso de modelos apilados. Pueden mejorar la precisión existente que muestran los modelos individuales. Podemos obtener la mayoría de los modelos apilados eligiendo diversos algoritmos en la primera capa de arquitectura, ya que diferentes algoritmos capturan diferentes tendencias en los datos de entrenamiento al combinar ambos modelos para obtener resultados mejores y más precisos.
Instalación de librerías en el sistema:
pip install mlxtend
pip install pandas
pip install -U scikit-learn
Código: Importar bibliotecas requeridas:
python3
import pandas as pd import matplotlib.pyplot as plt from mlxtend.plotting import plot_confusion_matrix from mlxtend.classifier import StackingClassifier from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.naive_bayes import GaussianNB from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score
Código: cargando el conjunto de datos
python3
df = pd.read_csv('heart.csv') # loading the dataset
df.head() # viewing top 5 rows of dataset
Producción:
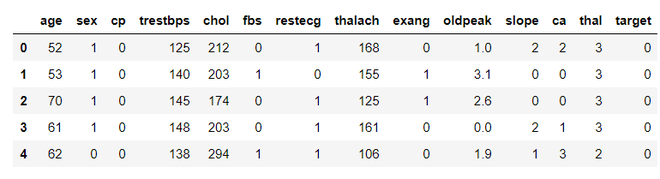
Código:
python3
# Creating X and y for training
X = df.drop('target', axis = 1)
y = df['target']
Código: división de datos en tren y prueba
python3
# 20 % training dataset is considered for testing X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
Código: estandarización de datos
python3
# initializing sc object sc = StandardScaler() # variables that needed to be transformed var_transform = ['thalach', 'age', 'trestbps', 'oldpeak', 'chol'] X_train[var_transform] = sc.fit_transform(X_train[var_transform]) # standardizing training data X_test[var_transform] = sc.transform(X_test[var_transform]) # standardizing test data print(X_train.head())
Producción:
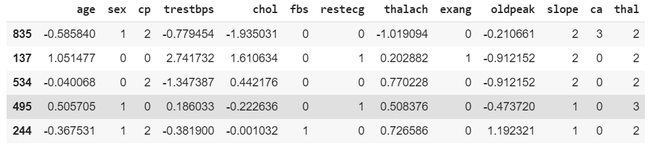
Código: Creación de estimadores de primera capa
python3
KNC = KNeighborsClassifier() # initialising KNeighbors Classifier NB = GaussianNB() # initialising Naive Bayes
Entrenemos y evaluemos con nuestros estimadores de primera capa para observar la diferencia en el rendimiento del modelo apilado y el modelo general
Código: Entrenamiento KNeighborsClassifier
python3
model_kNeighborsClassifier = KNC.fit(X_train, y_train) # fitting Training Set pred_knc = model_kNeighborsClassifier.predict(X_test) # Predicting on test dataset
Código: Evaluación de KNeighborsClassifier
python3
acc_knc = accuracy_score(y_test, pred_knc) # evaluating accuracy score
print('accuracy score of KNeighbors Classifier is:', acc_knc * 100)
Producción:

Código: Entrenamiento Naive Bayes Classifier
python3
model_NaiveBayes = NB.fit(X_train, y_train) pred_nb = model_NaiveBayes.predict(X_test)
Código: Evaluación del Clasificador Naive Bayes
python3
acc_nb = accuracy_score(y_test, pred_nb)
print('Accuracy of Naive Bayes Classifier:', acc_nb * 100)
Producción:

Código: Implementación del clasificador de apilamiento
python3
lr = LogisticRegression() # defining meta-classifier clf_stack = StackingClassifier(classifiers =[KNC, NB], meta_classifier = lr, use_probas = True, use_features_in_secondary = True)
- use_probas=True indica que el clasificador de apilamiento usa las probabilidades de predicción como entrada en lugar de usar clases de predicción.
- use_features_in_secondary=True indica que el clasificador de apilamiento no solo toma predicciones como entrada, sino que también usa características en el conjunto de datos para predecir nuevos datos.
Código: Clasificador de apilamiento de entrenamiento
python3
model_stack = clf_stack.fit(X_train, y_train) # training of stacked model pred_stack = model_stack.predict(X_test) # predictions on test data using stacked model
Código: Evaluación del clasificador de apilamiento
python3
acc_stack = accuracy_score(y_test, pred_stack) # evaluating accuracy
print('accuracy score of Stacked model:', acc_stack * 100)
Producción:

Nuestros dos modelos individuales obtienen una precisión de casi el 80 % y nuestro modelo apilado obtuvo una precisión de casi el 84 %. Al combinar dos modelos individuales, obtuvimos una mejora significativa en el rendimiento.
Código:
python3
model_stack = clf_stack.fit(X_train, y_train) # training of stacked model pred_stack = model_stack.predict(X_test) # predictions on test data using stacked model
Código: Evaluación del clasificador de apilamiento
python3
acc_stack = accuracy_score(y_test, pred_stack) # evaluating accuracy
print('accuracy score of Stacked model:', acc_stack * 100)
Producción:
Nuestros dos modelos individuales obtienen una precisión de casi el 80 % y nuestro modelo apilado obtuvo una precisión de casi el 84 %. Al combinar dos modelos individuales, obtuvimos una mejora significativa en el rendimiento.
Publicación traducida automáticamente
Artículo escrito por Koushik222 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA