Un valor atípico es un objeto que se desvía significativamente del resto de los objetos. Pueden ser causados por error de medición o de ejecución. El análisis de datos de valores atípicos se conoce como análisis de valores atípicos o minería de valores atípicos.
¿Por qué análisis de valores atípicos?
La mayoría de los métodos de minería de datos descartan el ruido de los valores atípicos o las excepciones; sin embargo, en algunas aplicaciones, como la detección de fraudes, los eventos raros pueden ser más interesantes que los que ocurren con mayor frecuencia y, por lo tanto, el análisis de los valores atípicos se vuelve importante en tal caso.
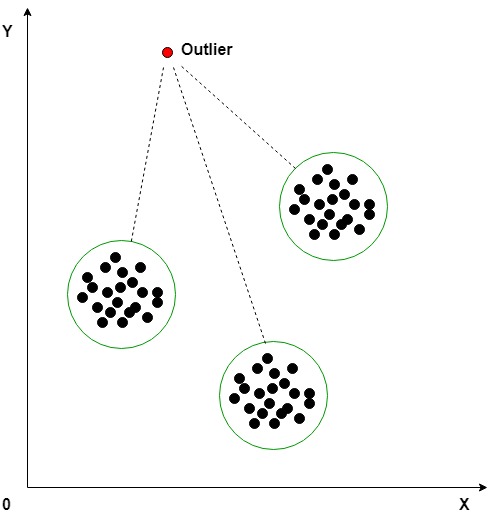
Detección de valores atípicos:
Detección de valores atípicos basada en agrupamiento usando la distancia al grupo más cercano:
En la técnica de agrupamiento de K-Means, cada grupo tiene un valor medio. Los objetos pertenecen al grupo cuyo valor medio es el más cercano. Para identificar el valor atípico, primero debemos inicializar el valor del umbral de modo que cualquier distancia de cualquier punto de datos mayor que él desde su grupo más cercano lo identifique como un valor atípico para nuestro propósito. Luego necesitamos encontrar la distancia de los datos de prueba a la media de cada grupo. Ahora, si la distancia entre los datos de prueba y el grupo más cercano es mayor que el valor de umbral, clasificaremos los datos de prueba como atípicos.
Algoritmo:
- Calcular la media de cada grupo
- Inicialice el valor del umbral
- Calcule la distancia de los datos de prueba de cada media de grupo
- Encuentre el clúster más cercano a los datos de prueba
- Si (Distancia > Umbral) entonces, Valor atípico