El objetivo del aprendizaje contrastivo es aprender ese espacio de incrustación en el que las muestras similares están cerca unas de otras mientras que las diferentes están muy separadas. Asume un conjunto de oraciones emparejadas como  , donde xi y xi+ están relacionados semánticamente entre sí.
, donde xi y xi+ están relacionados semánticamente entre sí.
Sea  y
y  denote las representaciones de x_i y {
denote las representaciones de x_i y {  , para un mini lote con N pares, el objetivo de entrenamiento para
, para un mini lote con N pares, el objetivo de entrenamiento para  es:
es:

donde \tau es un hiperparámetro de temperatura y sim(  ) representa la similitud del coseno de la salida codificada que se puede generar usando un modelo de lenguaje previamente entrenado como BERT y RoBERTa
) representa la similitud del coseno de la salida codificada que se puede generar usando un modelo de lenguaje previamente entrenado como BERT y RoBERTa
Se puede aplicar tanto a entornos supervisados como no supervisados. En este artículo, discutiremos un área particular del aprendizaje contrastivo, es decir, el aumento de texto.
Aumento de texto:
El aprendizaje contrastivo en visión por computadora solo genera el aumento de imágenes. Es más desafiante construir aumento de texto que aumento de imagen porque necesitamos mantener el significado de la oración. Hay 3 métodos para aumentar las secuencias de texto:
Traducción inversa
En este enfoque, tratamos de generar las oraciones aumentadas a través de la retrotraducción. CERT (Representaciones de codificadores autosupervisados contrastivos de transformadores) es uno de esos artículos. En este documento, se utilizan muchos modelos de traducción para diferentes idiomas para aumentar el texto del texto de entrada, luego usamos estos aumentos para generar las muestras de texto, podemos usar diferentes marcos de bancos de memoria de aprendizaje contrastivo para generar incrustaciones de oraciones.
Ediciones léxicas:
Lexical Edits o EDA (Easy Data Augmentation) es un conjunto simple de operaciones para el aumento de texto. Toma una oración como entrada y aplica aleatoriamente una de las cuatro operaciones simples:
- Inserción aleatoria (RI): inserte un sinónimo de una palabra continua seleccionada al azar en la oración en una posición aleatoria.
- Intercambio aleatorio (RS): intercambia aleatoriamente dos palabras n veces.
- Eliminación aleatoria (RD): elimine aleatoriamente cada palabra de la oración con probabilidad p.
- Reemplazo de sinónimos (SR): elija aleatoriamente n palabras de la oración que no sean palabras de parada. Reemplace cada una de estas palabras con uno de sus sinónimos elegidos al azar.
Si bien estos métodos son simples y fáciles de implementar, el autor también admitió las limitaciones, es decir, logran una mejora de <1 % en conjuntos de datos pequeños y casi ninguna cuando se usa como un modelo preentrenado.
Corte y abandono:
Cortar:
En 2009, Shen et al, en Microsoft y los investigadores de la Universidad de Illinois propusieron un método que utiliza el corte para realizar el aumento de texto. Proponen 3 estrategias diferentes para el aumento de corte. Discutiremos estas estrategias una por una, pero consideremos que las oraciones se representan como la incrustación de L*d donde L es el número de características, d es la longitud de la oración
- Corte de funciones: elimina algunas funciones seleccionadas.
- Token Cutoff: elimina la información de algunos tokens seleccionados.
- Corte de tramo: elimina un fragmento continuo de texto.
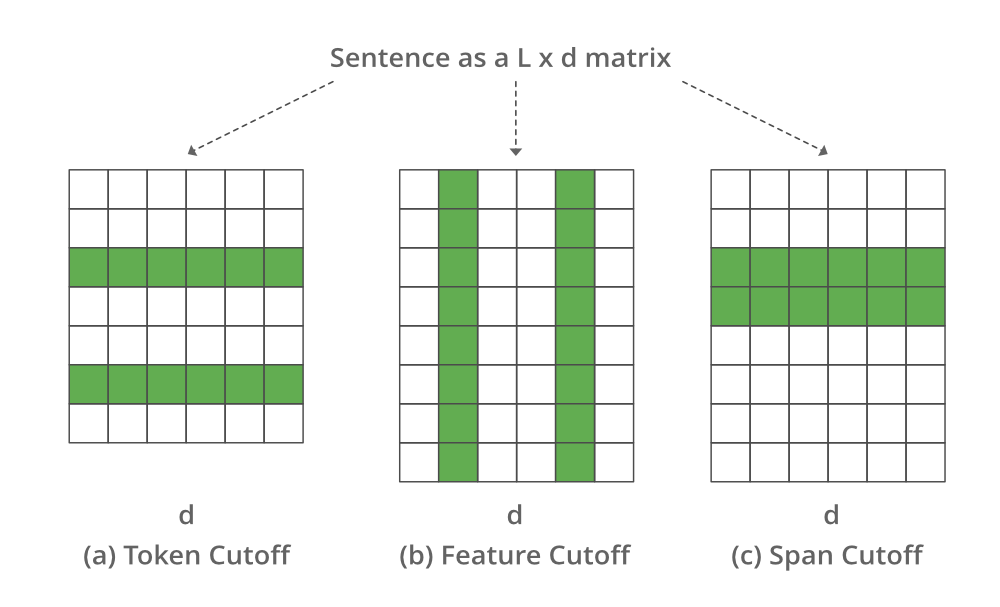
Imagen que representa diferentes puntos de corte
Para comparar la distribución de predicciones de diferentes aumentos, usamos una pérdida de divergencia KL adicional durante el entrenamiento.
Abandonar:
En 2021, los investigadores del grupo Stanford NLP proponen SimCSE. En el escenario no supervisado, aprende a predecir la oración en sí usando el ruido DropOut. En otras palabras, tratan el abandono como un aumento de datos para secuencias de texto.
En el enfoque anterior, tomamos una colección de oraciones {[x_i ]}_{i=1}^{m} y tratamos el par positivo como x_i^{+} = x_i. Durante el entrenamiento de Transformers, se aplica una máscara de abandono y probabilidades de atención en capas totalmente conectadas. Simplemente alimenta la misma entrada al codificador dos veces aplicando diferentes máscaras de abandono z, z 0 y, por lo tanto, la función objetivo de entrenamiento se puede definir como:
donde, h_i^{z_i} = f_\theta (x_i, z) es la salida y z es la máscara estándar para la deserción.
En un entorno supervisado, tratamos de aprovechar el conjunto de datos de Inferencia del lenguaje natural (NLI) para predecir si existe una vinculación (pares positivos) o una contradicción (pares negativos) entre un par de oraciones dado. Ampliamos el  El objetivo se puede definir como:
El objetivo se puede definir como:

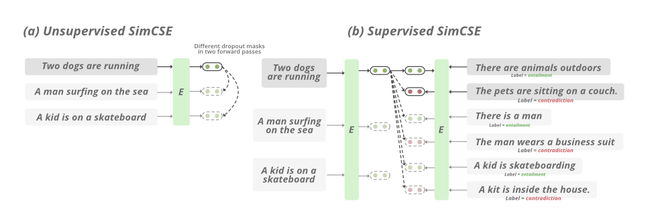
Funcionamiento de SimCSE
Implementación
- En esta implementación, tomamos algunas oraciones, luego aplicamos el tokenizador SimCSE para tokenizar la oración y el modelo para generar la incrustación de entradas, y luego calculamos la similitud del coseno entre ellas.
Python3
# Install PyTorch
! pip install torch==1.7.1+cu110 -f https://download.pytorch.org/whl/torch_stable.html
# clone the repo
!git clone https://github.com/princeton-nlp/SimCSE
# install the requirements
! pip install -r /content/SimCSE/requirements.txt
# imports
import torch
from scipy.spatial.distance import cosine
from transformers import AutoModel, AutoTokenizer
# Import the pretrained models and tokenizer, this will also download and import th
tokenizer = AutoTokenizer.from_pretrained("princeton-nlp/sup-simcse-bert-base-uncased")
model = AutoModel.from_pretrained("princeton-nlp/sup-simcse-bert-base-uncased")
# input sentence
texts = [
"I am writing an article",
"Writing an article on Machine learning",
"I am not writing.",
"the article on machine learning is already written"
]
# tokenize the input
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
# generate the embeddings
with torch.no_grad():
embeddings = model(**inputs, output_hidden_states=True,
return_dict=True).pooler_output
# the shape of embedding (# input, 768)
embeddings.shape
# print cosine similarity b/w the sentences
for i in range(len(texts)):
for j in range(len(texts)):
if (i != j):
cosine_sim = 1 - cosine(embeddings[i], embeddings[j])
print("Cosine similarity between \"%s\" and \"%s\" is: %.3f" % (texts[i], texts[j], cosine_sim))
La similitud de coseno entre «Estoy escribiendo un artículo» y «Escribiendo un artículo sobre aprendizaje automático» es: 0.515
La similitud de coseno entre «Estoy escribiendo un artículo» y «No estoy escribiendo». es: 0,517
La similitud de coseno entre “Estoy escribiendo un artículo” y “el artículo sobre aprendizaje automático ya está escrito” es: 0,441 La
similitud de coseno entre “Escribo un artículo sobre aprendizaje automático” y “Estoy escribiendo un artículo” es: 0,515
Coseno similitud entre «Escribir un artículo sobre aprendizaje automático» y «No estoy escribiendo». es: 0,188
La similitud de coseno entre «Escribo un artículo sobre aprendizaje automático» y «el artículo sobre aprendizaje automático ya está escrito» es: 0,807
La similitud de coseno entre «No estoy escribiendo». y “Estoy escribiendo un artículo” es: 0.517
Semejanza de coseno entre «No estoy escribiendo». y “Escribir un artículo sobre aprendizaje automático” es: 0,188
Similitud de coseno entre “No estoy escribiendo”. y “el artículo sobre aprendizaje automático ya está escrito” es: 0,141
La similitud de coseno entre “el artículo sobre aprendizaje automático ya está escrito” y “Estoy escribiendo un artículo” es: 0,441 La
similitud de coseno entre “el artículo sobre aprendizaje automático ya está escrito ” y “Escribiendo un artículo sobre aprendizaje automático” es: 0.807
Similitud de coseno entre “el artículo sobre aprendizaje automático ya está escrito” y “No estoy escribiendo”. es: 0.141
- En el ejemplo anterior, solo comparamos la similitud del coseno de las oraciones. Para conocer más detalles sobre la capacitación, consulte los detalles de la capacitación en el repositorio oficial .