El croquis Count-min es una estructura de datos probabilísticos . El croquis Count-Min es una técnica simple para resumir grandes cantidades de datos de frecuencia. El algoritmo de bosquejo Count-min habla de realizar un seguimiento del recuento de cosas. es decir, cuántas veces está presente un elemento en el conjunto. Encontrar el recuento de un elemento se puede lograr fácilmente en Java utilizando HashTable o Map . Probando MultiSet como una alternativa al boceto Count-min Intentemos implementar esta estructura de datos usando MultiSet con el siguiente código fuente e intentemos encontrar problemas con este enfoque.
java
// Java program to try MultiSet as an
// alternative to Count-min sketch
import com.google.common.collect.HashMultiset;
import com.google.common.collect.Multiset;
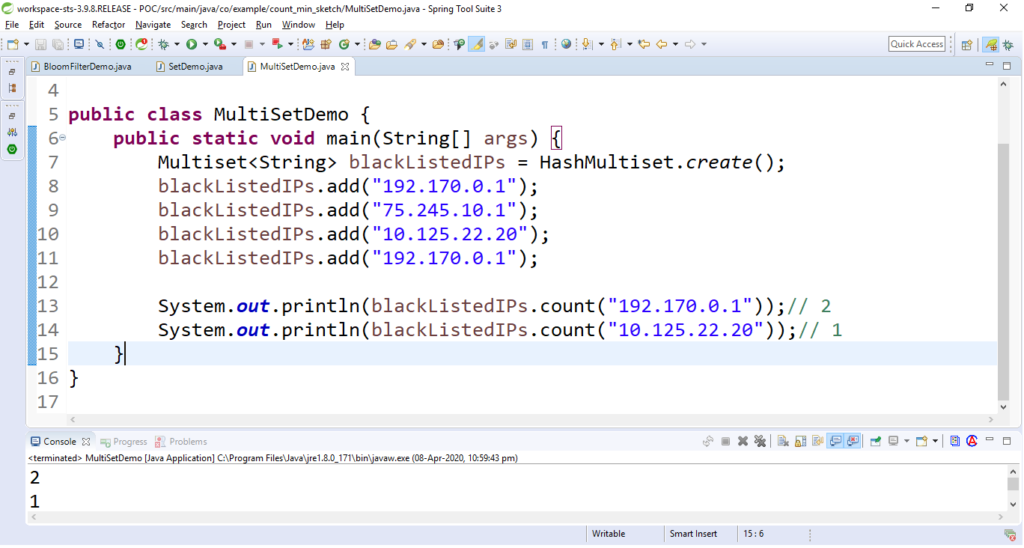
public class MultiSetDemo {
public static void main(String[] args)
{
Multiset<String> blackListedIPs
= HashMultiset.create();
blackListedIPs.add("192.170.0.1");
blackListedIPs.add("75.245.10.1");
blackListedIPs.add("10.125.22.20");
blackListedIPs.add("192.170.0.1");
System.out.println(blackListedIPs
.count("192.170.0.1"));
System.out.println(blackListedIPs
.count("10.125.22.20"));
}
}
Producción:
Comprender el problema de usar MultiSet
Ahora veamos el tiempo y el espacio consumidos con este tipo de enfoque.
---------------------------------------------- |Number of UUIDs Insertion Time(ms) | ---------------------------------------------- |10 <25 | |100 <25 | |1, 000 30 | |10, 000 257 | |100, 000 1200 | |1, 000, 000 4244 | ----------------------------------------------
Echemos un vistazo a la memoria (espacio) consumida:
---------------------------------------------- |Number of UUIDs JVM heap used(MB) | ---------------------------------------------- |10 <2 | |100 <2 | |1, 000 3 | |10, 000 9 | |100, 000 39 | |1, 000, 000 234 | -----------------------------------------------
Podemos entender fácilmente que a medida que crecen los datos, el enfoque anterior consume mucha memoria y tiempo para procesar los datos. Esto se puede optimizar si usamos el algoritmo de croquis count-min .
¿Qué es Count-min sketch y cómo funciona?
El enfoque de croquis Count-min fue propuesto por Graham Cormode y S. Muthukrishnan . en el artículo de aproximación de datos con el croquis count-min publicado en 2011/12. El esquema Count-min se utiliza para contar la frecuencia de los eventos en los datos de transmisión. Al igual que el filtro Bloom , el algoritmo de croquis Count-min también funciona con códigos hash. Utiliza múltiples funciones hash para mapear estas frecuencias en la array (Considere dibujar aquí una array bidimensionalo array ).
Veamos el siguiente ejemplo paso a paso.
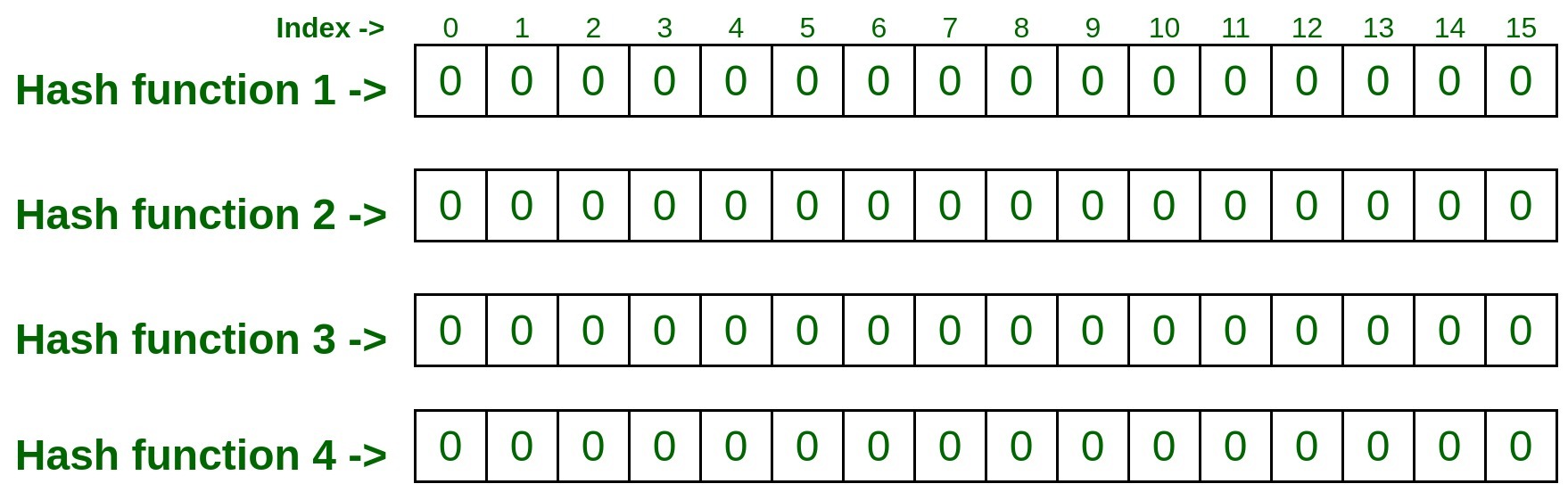
- Considere la siguiente array 2D con 4 filas y 16 columnas, también el número de filas es igual al número de funciones hash. Eso significa que estamos tomando cuatro funciones hash para nuestro ejemplo. Inicializar/marcar cada celda de la array con cero.
Nota: Cuanto más preciso sea el resultado que desee, mayor será el número de funciones hash que se utilizarán.
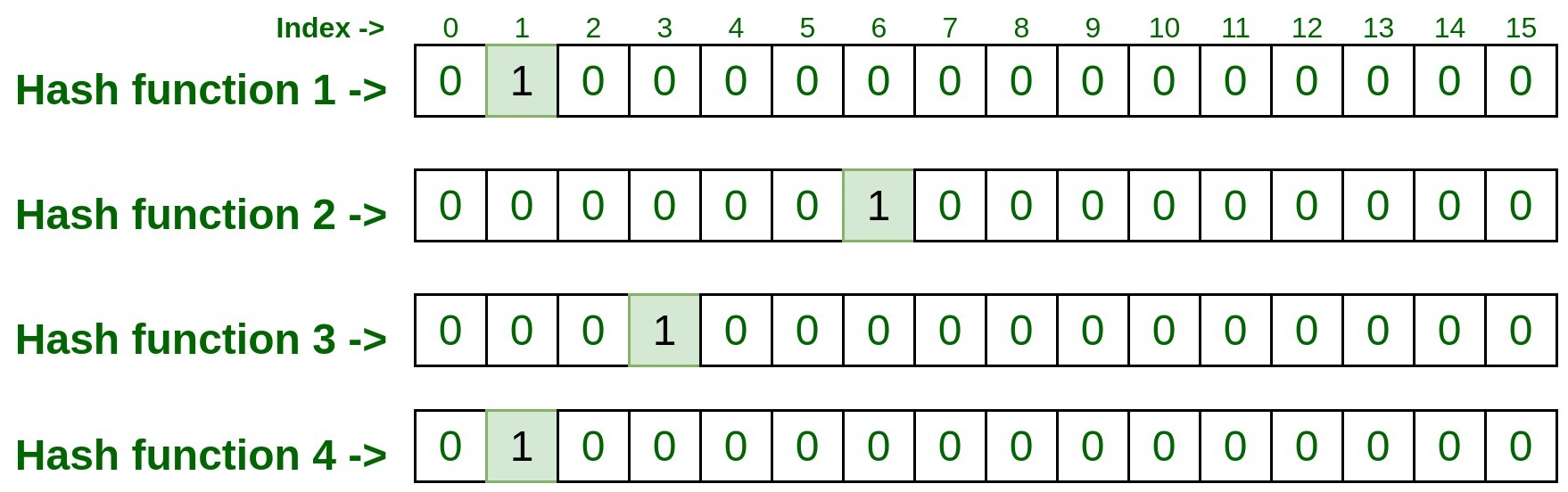
- Ahora vamos a agregarle algún elemento. Para hacerlo, debemos pasar ese elemento con las cuatro funciones hash, lo que puede resultar de la siguiente manera.
Input : 192.170.0.1
hashFunction1(192.170.0.1): 1 hashFunction2(192.170.0.1): 6 hashFunction3(192.170.0.1): 3 hashFunction4(192.170.0.1): 1
- Ahora visite los índices recuperados arriba por las cuatro funciones hash y márquelos como 1.
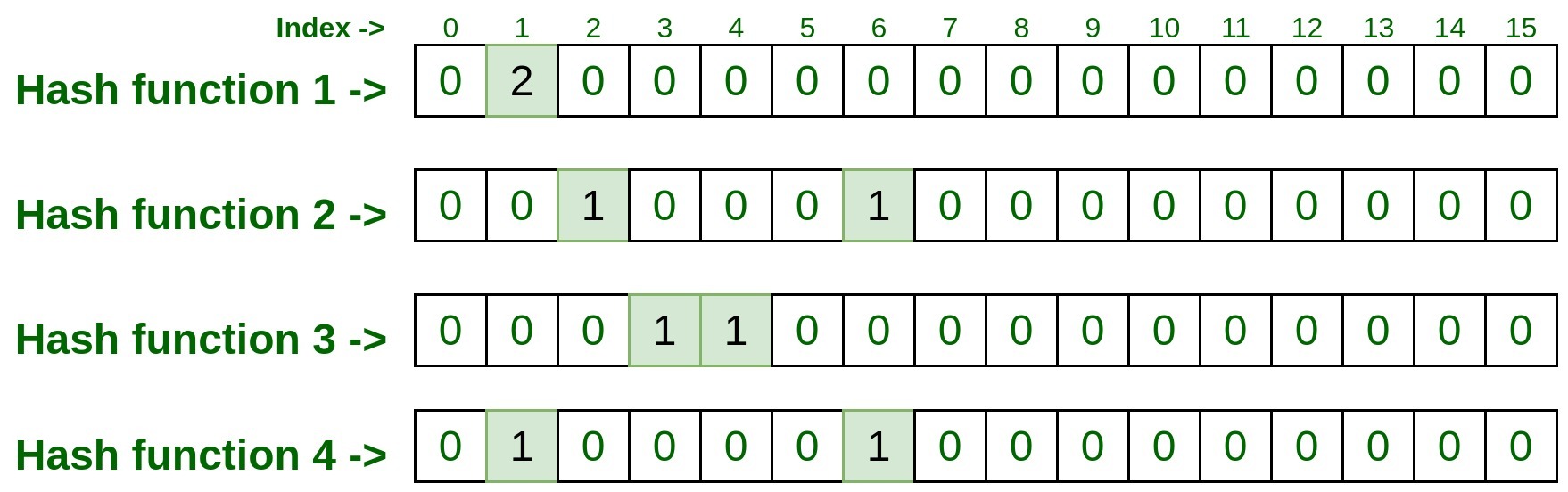
- Del mismo modo, procese la segunda entrada pasándola a las cuatro funciones hash.
Input : 75.245.10.1
hashFunction1(75.245.10.1): 1 hashFunction2(75.245.10.1): 2 hashFunction3(75.245.10.1): 4 hashFunction4(75.245.10.1): 6
- Ahora, tome estos índices y visite la array, si el índice dado ya se ha marcado como 1. Esto se llama colisión, lo que significa que el índice de esa fila ya estaba marcado por algunas entradas anteriores y, en este caso, solo incremente el valor del índice. por 1. En nuestro caso, dado que ya hemos marcado el índice 1 de la fila 1, es decir, hashFunction1() como 1 por la entrada anterior, entonces esta vez se incrementará en 1 y ahora esta entrada de celda será 2, pero para el resto de el índice de filas de descanso será 0, ya que no hubo colisión.
- Procesemos la siguiente entrada
Input : 10.125.22.20
hashFunction1(10.125.22.20): 3 hashFunction2(10.125.22.20): 4 hashFunction3(10.125.22.20): 1 hashFunction4(10.125.22.20): 6
- Vamos a representarlo en la array, recuerde incrementar el conteo en 1 si ya existe alguna entrada.
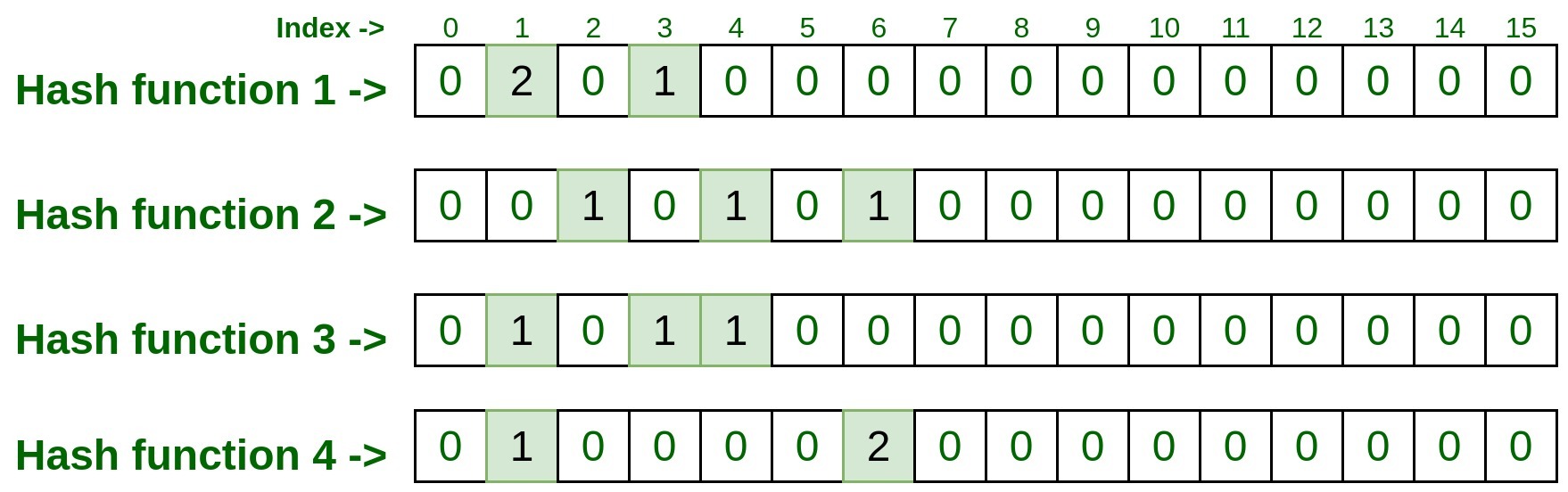
- Del mismo modo, procese la siguiente entrada.
Input : 192.170.0.1
hashFunction1(192.170.0.1): 1 hashFunction2(192.170.0.1): 6 hashFunction3(192.170.0.1): 3 hashFunction4(192.170.0.1): 1
- Echemos un vistazo a la representación matricial.
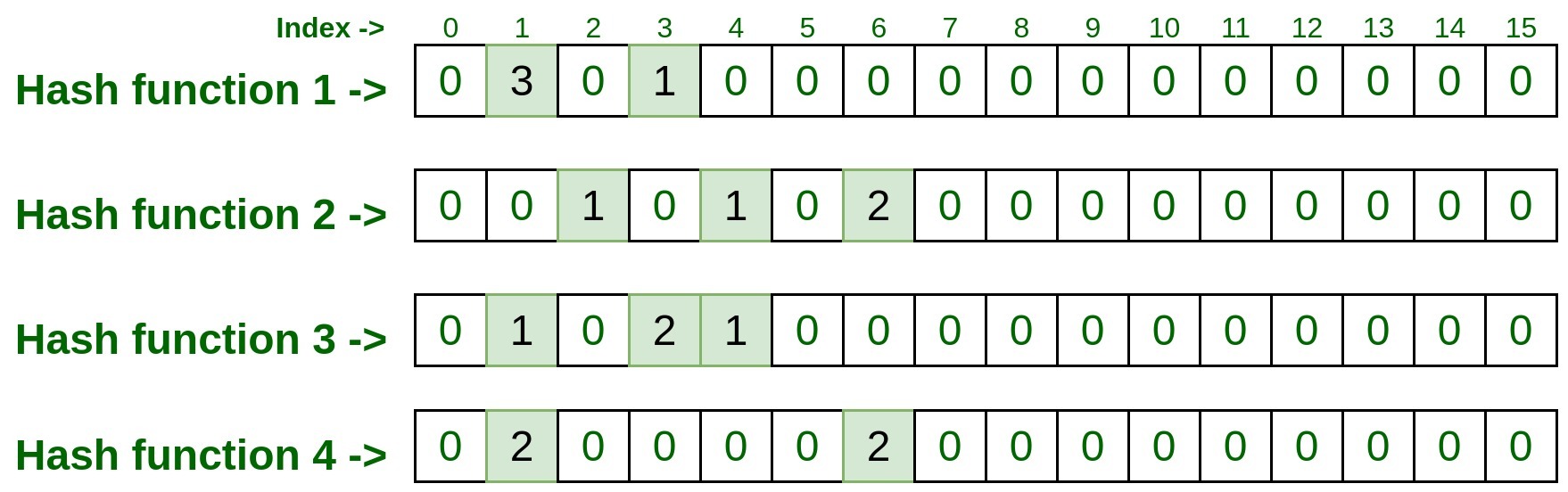
Ahora probemos algún elemento y verifiquemos cuántas veces están presentes.
Test Input #1: 192.170.0.1
- Pase la entrada anterior a las cuatro funciones hash y tome los números de índice generados por las funciones hash.
hashFunction1(192.170.0.1): 1 hashFunction2(192.170.0.1): 6 hashFunction3(192.170.0.1): 3 hashFunction4(192.170.0.1): 1
- Ahora visite cada índice y tome nota de la entrada presente en ese índice
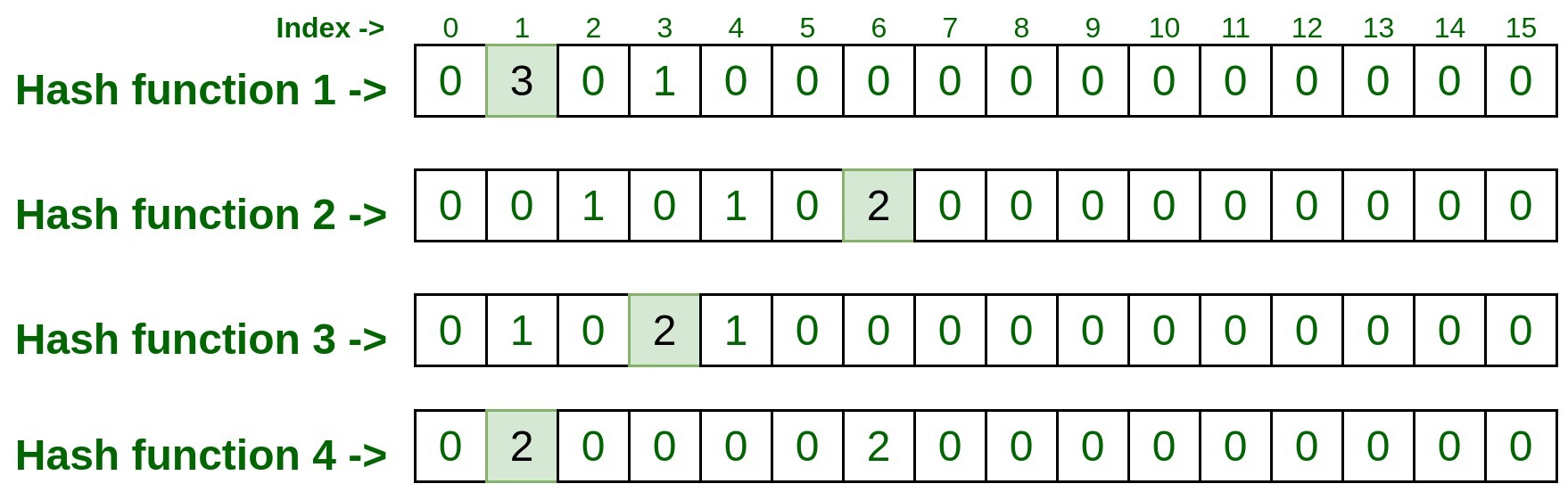
- Entonces, la entrada final en cada índice fue 3, 2, 2, 2 . Ahora tome la cuenta mínima entre estas entradas y ese es el resultado. Entonces min(3, 2, 2, 2) es 2, eso significa que la entrada de prueba anterior se procesa dos veces en la lista anterior.
Test Input #1: 10.125.22.20
- Pase la entrada anterior a las cuatro funciones hash y tome los números de índice generados por las funciones hash.
hashFunction1(10.125.22.20): 3 hashFunction2(10.125.22.20): 4 hashFunction3(10.125.22.20): 1 hashFunction4(10.125.22.20): 6
- Ahora visite cada índice y tome nota de la entrada presente en ese índice
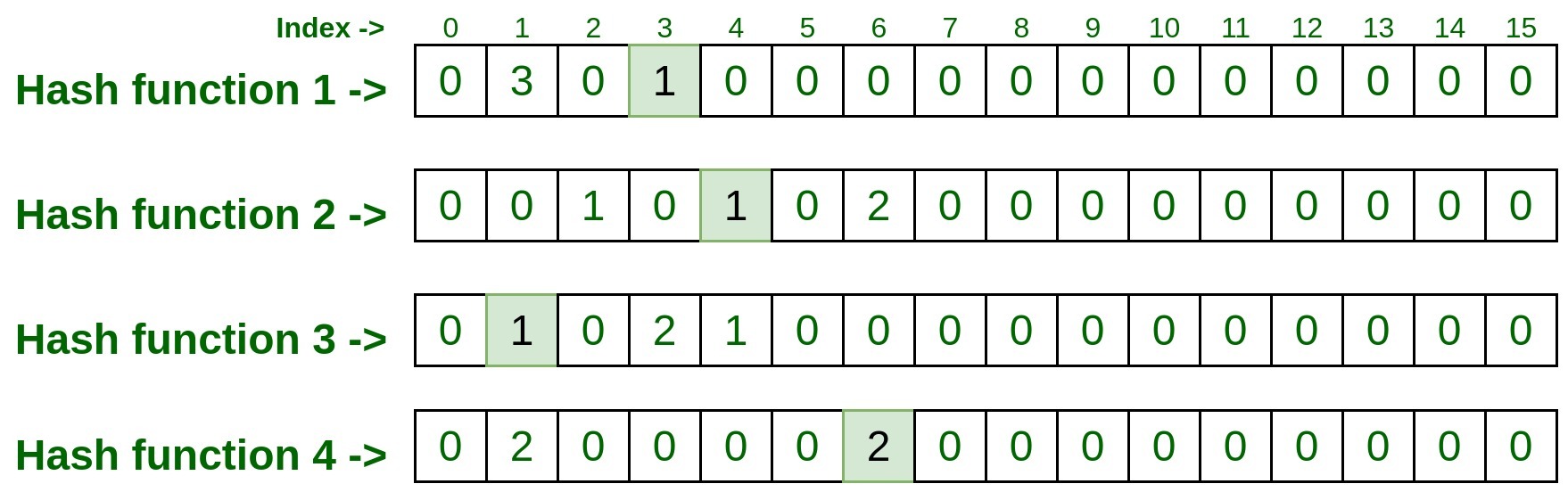
- Entonces, la entrada final en cada índice fue 1, 1, 1, 2 . Ahora tome la cuenta mínima entre estas entradas y ese es el resultado. Entonces min(1, 1, 1, 2) es 1, eso significa que la entrada de prueba anterior se procesa solo una vez en la lista anterior.
Problema con el boceto Count-min y su solución:
¿Qué pasa si uno o más elementos obtienen los mismos valores hash y luego todos se incrementan? Entonces, en ese caso, el valor habría aumentado debido a la colisión hash . Por lo tanto, a veces (en casos muy raros), el esquema Count-min sobrecuenta las frecuencias debido a las funciones hash. Entonces, mientras más función hash tomemos, habrá menos colisión. Cuantas menos funciones hash tomemos habrá una alta probabilidad de colisión . Por lo tanto, siempre se recomienda tomar más funciones hash.
Aplicaciones del croquis Count-min:
- Detección comprimida
- Redes
- PNL
- Procesamiento de flujo
- Seguimiento de frecuencia
- Extensión: Pesados
- Extensión: consulta de rango
Implementación del boceto Count-min usando la biblioteca Guava en Java:
podemos implementar el boceto Count-min usando la biblioteca Java proporcionada por Guava. A continuación se muestra la implementación paso a paso:
- Utilice debajo de la dependencia maven.
XML
<dependency> <groupId>com.clearspring.analytics</groupId> <artifactId>stream</artifactId> <version>2.9.5</version> </dependency>
- El código Java detallado es el siguiente:
Java
import com.clearspring.analytics
.stream.frequency.CountMinSketch;
public class CountMinSketchDemo {
public static void main(String[] args)
{
CountMinSketch countMinSketch
= new CountMinSketch(
// epsilon
0.001,
// delta
0.99,
// seed
1);
countMinSketch.add("75.245.10.1", 1);
countMinSketch.add("10.125.22.20", 1);
countMinSketch.add("192.170.0.1", 2);
System.out.println(
countMinSketch
.estimateCount(
"192.170.0.1"));
System.out.println(
countMinSketch
.estimateCount(
"999.999.99.99"));
}
}
- El ejemplo anterior toma tres argumentos en el constructor que son
- 0.001 = the epsilon i.e., error rate - 0.99 = the delta i.e., confidence or accuracy rate - 1 = the seed
- Ahora echemos un vistazo al tiempo y espacio consumidos con este enfoque.
----------------------------------------------------------------------------- |Number of UUIDs | Multiset Insertion Time(ms) | CMS Insertion Time(ms) | ----------------------------------------------------------------------------- |10 <25 35 | |100 <25 30 | |1, 000 30 69 | |10, 000 257 246 | |100, 000 1200 970 | |1, 000, 000 4244 4419 | -----------------------------------------------------------------------------
- Ahora, echemos un vistazo a la memoria consumida:
-------------------------------------------------------------------------- |Number of UUIDs | Multiset JVM heap used(MB) | CMS JVM heap used(MB) | -------------------------------------------------------------------------- |10 <2 N/A | |100 <2 N/A | |1, 000 3 N/A | |10, 000 9 N/A | |100, 000 39 N/A | |1, 000, 000 234 N/A | ---------------------------------------------------------------------------
- Sugerencias:
------------------------------------------------------------------------------------- |Epsilon | Delta | width/Row (hash functions)| Depth/column| CMS JVM heap used(MB) | ------------------------------------------------------------------------------------- |0.1 |0.99 | 7 | 20 | 0.009 | |0.01 |0.999 | 10 | 100 | 0.02 | |0.001 |0.9999 | 14 | 2000 | 0.2 | |0.0001 |0.99999 | 17 | 20000 | 2 | --------------------------------------------------------------------------------------
Conclusión:
Hemos observado que el esquema Count-min es una buena opción en una situación en la que tenemos que procesar un gran conjunto de datos con un bajo consumo de memoria . También vimos que el resultado más preciso que queremos es aumentar la cantidad de funciones hash (filas/ancho).
Publicación traducida automáticamente
Artículo escrito por asadaliasad y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA