El lenguaje de programación Python proporciona los siguientes tipos de bucles para manejar los requisitos de bucle.
Sintaxis:
while expression:
statement(s)
En Python, todas las declaraciones sangradas por la misma cantidad de espacios de caracteres después de una construcción de programación se consideran parte de un solo bloque de código. Python usa la sangría como su método de agrupar declaraciones.
# prints Hello Geek 3 Times
count = 0
while (count < 3):
count = count+1
print("Hello Geek")
Producción:
Hello Geek Hello Geek Hello Geek
Vea esto para ver un ejemplo en el que se usa while loop para iteradores. Como se menciona en el artículo, no se recomienda usar while loop para iteradores en python.
En Python, no existe un estilo de C para el ciclo, es decir, for (i=0; i
Sintaxis:
Se puede usar para iterar sobre iteradores y un rango.
Producción:
Podemos usar for in loop para iteradores definidos por el usuario. Vea esto por ejemplo.
La sintaxis para una instrucción de ciclo while anidado en el lenguaje de programación Python es la siguiente:
Una nota final sobre el anidamiento de bucles es que podemos poner cualquier tipo de bucle dentro de cualquier otro tipo de bucle. Por ejemplo, un bucle for puede estar dentro de un bucle while o viceversa.
Producción:
Sentencia Continue
Devuelve el control al inicio del ciclo.
Producción:
Break Statement
Saca el control del bucle
Producción:
Instrucción de paso
Usamos la instrucción de paso para escribir bucles vacíos. Pass también se usa para declaraciones de control, funciones y clases vacías.
Producción:
Ejercicio:
Cómo imprimir una lista en orden inverso (del último al primer elemento) usando los bucles while y for in.
TensorFlow es una biblioteca de software de código abierto para la programación de flujo de datos en una variedad de tareas. Es una biblioteca matemática simbólica y también se utiliza para aplicaciones de aprendizaje automático, como redes neuronales. TensorFlow de código abierto de Google en noviembre de 2015. Desde entonces, TensorFlow se ha convertido en el repositorio de aprendizaje automático con más estrellas en Github. (https://github.com/tensorflow/tensorflow)
¿Por qué TensorFlow? La popularidad de TensorFlow se debe a muchas cosas, pero principalmente al concepto de gráficos computacionales, la diferenciación automática y la adaptabilidad de la estructura de la API de Python de Tensorflow. Esto hace que la resolución de problemas reales con TensorFlow sea accesible para la mayoría de los programadores.
El motor Tensorflow de Google tiene una forma única de resolver problemas. Esta forma única permite resolver problemas de aprendizaje automático de manera muy eficiente. Cubriremos los pasos básicos para comprender cómo funciona Tensorflow.
¿Qué es Tensor en Tensorflow?
TensorFlow, como su nombre lo indica, es un marco para definir y ejecutar cálculos que involucran tensores. Un tensor es una generalización de vectores y arrays a dimensiones potencialmente más altas. Internamente, TensorFlow representa los tensores como arrays n-dimensionales de tipos de datos base. Cada elemento del tensor tiene el mismo tipo de datos y el tipo de datos siempre se conoce. La forma (es decir, el número de dimensiones que tiene y el tamaño de cada dimensión) podría conocerse solo parcialmente. La mayoría de las operaciones producen tensores de formas completamente conocidas si las formas de sus entradas también son completamente conocidas, pero en algunos casos solo es posible encontrar la forma de un tensor en el momento de la ejecución del gráfico.
Esquemas generales del algoritmo TensorFlow
Aquí presentaremos el flujo general de los algoritmos Tensorflow.
- Importar o generar datos
Todos nuestros algoritmos de aprendizaje automático dependerán de los datos. En la práctica, generaremos datos o utilizaremos una fuente externa de datos. A veces es mejor confiar en los datos generados porque querremos saber el resultado esperado. Y también tensorflow viene precargado con conjuntos de datos famosos como MNIST, CIFAR-10, etc.
- Transformar y normalizar datos
Por lo general, los datos no tienen la dimensión o el tipo correctos que esperan nuestros algoritmos de Tensorflow. Tendremos que transformar nuestros datos antes de poder usarlos. La mayoría de los algoritmos también esperan datos normalizados. Tensorflow tiene funciones integradas que pueden normalizar los datos por ti.
data = tf.nn.batch_norm_with_global_normalization(...)
- Establecer parámetros de algoritmo
Nuestros algoritmos suelen tener un conjunto de parámetros que mantenemos constantes durante todo el procedimiento. Por ejemplo, puede ser el número de iteraciones, la tasa de aprendizaje u otros parámetros fijos de nuestra elección. Se considera una buena forma inicializarlos juntos para que el lector o usuario pueda encontrarlos fácilmente.
learning_rate = 0.001 iterations = 1000
- Inicializar variables y marcadores de posición
Tensorflow depende de que le digamos qué puede y qué no puede modificar. Tensorflow modificará las variables durante la optimización para minimizar una función de pérdida. Para lograr esto, ingresamos datos a través de marcadores de posición. Necesitamos inicializar ambos, variables y marcadores de posición con tamaño y tipo, para que Tensorflow sepa qué esperar.
a_var = tf.constant(42) x_input = tf.placeholder(tf.float32, [None, input_size]) y_input = tf.placeholder(tf.fload32, [None, num_classes])
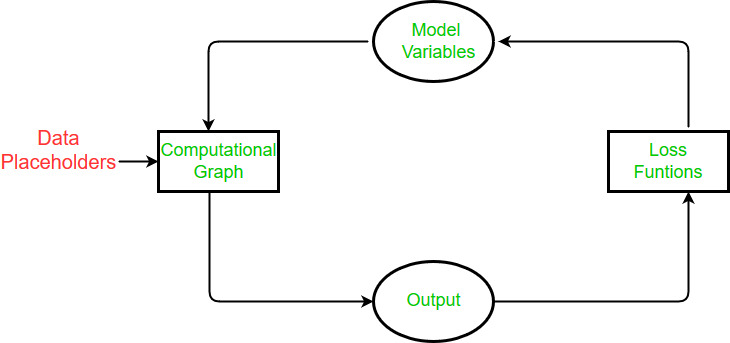
- Definir la estructura del modelo
Después de tener los datos e inicializar nuestras variables y marcadores de posición, tenemos que definir el modelo. Esto se hace mediante la construcción de un gráfico computacional. Le decimos a Tensorflow qué operaciones se deben realizar en las variables y marcadores de posición para llegar a las predicciones de nuestro modelo.
y_pred = tf.add(tf.mul(x_input, weight_matrix), b_matrix)
- Declarar las funciones de pérdida
Después de definir el modelo, debemos poder evaluar la salida. Aquí es donde declaramos la función de pérdida. La función de pérdida es muy importante ya que nos dice qué tan lejos están nuestras predicciones de los valores reales.
loss = tf.reduce_mean(tf.square(y_actual – y_pred))
- Inicializar y entrenar el modelo.
Ahora que tenemos todo en su lugar, creamos una instancia o nuestro gráfico e ingresamos los datos a través de los marcadores de posición y dejamos que Tensorflow cambie las variables para predecir mejor nuestros datos de entrenamiento. Aquí hay una forma de inicializar el gráfico computacional.
with tf.Session(graph=graph) as session: ... session.run(...) ...
Tenga en cuenta que también podemos iniciar nuestro gráfico con
session = tf.Session(graph=graph) session.run(…)
- Evaluar el modelo (Opcional)
Una vez que hemos construido y entrenado el modelo, debemos evaluar el modelo observando qué tan bien funciona con nuevos datos a través de algunos criterios específicos.
- Predecir nuevos resultados (Opcional)
También es importante saber cómo hacer predicciones sobre datos nuevos e invisibles. Podemos hacer esto con todos nuestros modelos, una vez que los hayamos entrenado.
Resumen
En Tensorflow, tenemos que configurar los datos, las variables, los marcadores de posición y el modelo antes de decirle al programa que entrene y cambie las variables para mejorar las predicciones. Tensorflow logra esto a través del gráfico computacional. Le decimos que minimice una función de pérdida y Tensorflow lo hace modificando las variables en el modelo. Tensorflow sabe cómo modificar las variables porque realiza un seguimiento de los cálculos en el modelo y calcula automáticamente los gradientes para cada variable. Debido a esto, podemos ver lo fácil que puede ser hacer cambios y probar diferentes fuentes de datos.
En general, los algoritmos están diseñados para ser cíclicos en TensorFlow. Configuramos este ciclo como un gráfico computacional y (1) ingresamos datos a través de los marcadores de posición, (2) calculamos la salida del gráfico computacional, (3) comparamos la salida con la salida deseada con una función de pérdida, (4) modificamos las variables del modelo de acuerdo con la retropropagación automática, y finalmente (5) repetir el proceso hasta que se cumpla un criterio de parada.
Ahora comienza la sesión práctica con tensorflow e implementando tensores usándolo.
Primero, necesitamos importar las bibliotecas requeridas.
Luego para iniciar la sesión de gráficos
Ahora viene la parte principal, es decir, crear tensores.
TensorFlow tiene una función integrada para crear tensores para usar en variables. Por ejemplo, podemos crear un tensor lleno de ceros de forma predefinida usando la función tf.zeros() de la siguiente manera.
Podemos evaluar tensores llamando a un método run() en nuestra sesión.
Los algoritmos de TensorFlow necesitan saber qué objetos son variables y cuáles son constantes. Así que creamos una variable usando la función TensorFlow tf.Variable(). Tenga en cuenta que no puede ejecutar sess.run(my_var), esto daría como resultado un error. Debido a que TensorFlow opera con gráficos computacionales, debemos crear una operación de inicialización de variables para evaluar las variables. Para este script, podemos inicializar una variable a la vez llamando al método de variable my_var.initializer.
Producción:
Ahora vamos a crear nuestra variable para manejar las dimensiones de tener una forma específica y luego inicializar las variables con todo ‘1’ o ‘0’
Ahora evalúe los valores de ellos, podemos ejecutar métodos de inicialización en nuestras variables nuevamente.
Producción:
Y esta lista continuará. El resto será para que estudies, sigue este jupyter notebook por mí para obtener más información sobre los tensores desde aquí .
Visualización de la creación de variables en TensorBoard
Para visualizar la creación de variables en Tensorboard, restableceremos el gráfico computacional y crearemos una operación de inicialización global.
Ahora ejecute el siguiente comando en cmd.
Y nos dirá la URL en la que podemos navegar nuestro navegador para ver Tensorboard, para lograr sus gráficos de pérdidas.
Código para crear todo tipo de tensores y evaluarlos.
Producción:
Link de referencia:
Los booleanos son conceptos simples y fáciles de usar que existen en todos los lenguajes de programación. Un valor booleano representa una idea de «verdadero» o «falso». Al escribir un algoritmo o cualquier programa, a menudo hay situaciones en las que queremos ejecutar un código diferente en diferentes situaciones. Los valores booleanos ayudan a nuestro código a hacer eso de manera fácil y efectiva. Más a menudo, se devuelve un valor booleano como resultado de algún tipo de operaciones de comparación.
Hay dos palabras clave booleanas:
Operadores verdaderos y falsos: los operadores son símbolos especiales en Python que se utilizan para realizar cálculos aritméticos o lógicos. Los valores sobre los que se va a realizar la operación se denominan operandos, mientras que la operación se indica mediante el operador (p. ej., +, -, /, *, %, etc.)
Operadores de comparación
Los operadores de comparación se utilizan para comparar valores. Devuelve True o False después de calcular la condición.
| Operador | Sentido | Ejemplo |
|---|---|---|
| > | Mayor que: verdadero si el operando izquierdo es mayor que el derecho | x > y |
| < | Menor que: verdadero si el operando izquierdo es menor que el derecho\\\ | x < y |
| == | Igual a: verdadero si ambos operandos son iguales | x == y |
| != | No es igual a: verdadero si los operandos no son iguales | x != y |
| >= | Mayor o igual que: verdadero si el operando izquierdo es mayor o igual que el derecho | x >= y |
| <= | Menor o igual que: verdadero si el operando izquierdo es menor o igual que el derecho | x <= y |
Operadores logicos
Hay tres operadores lógicos: y, o, no
| Operador | Sentido | Ejemplo |
|---|---|---|
| y | Verdadero si ambos operandos son verdaderos | X y Y |
| o | Verdadero si cualquiera de los operandos es verdadero | x o y |
| no | Verdadero si el operando es falso. | no x |
Mesa de la verdad
Una tabla de verdad es una pequeña tabla que nos permite dar los resultados de los operadores lógicos.
y Tabla: Toma dos operandos.
| a | b | a y B |
|---|---|---|
| Falso | Falso | Falso |
| Falso | Verdadero | Falso |
| Verdadero | Falso | Falso |
| Verdadero | Verdadero | Verdadero |
o Tabla: Toma dos operandos.
| a | b | a o B |
|---|---|---|
| Falso | Falso | Falso |
| Falso | Verdadero | Verdadero |
| Verdadero | Falso | Verdadero |
| Verdadero | Verdadero | Verdadero |
not Table : Toma solo un operando.
| a | No un |
|---|---|
| Falso | Verdadero |
| Verdadero | Falso |
Ejemplo 1: Comprobar si una lista está vacía o no. Pasaremos la lista en la función bool(). Cuando la lista está vacía, se devuelve False y si la lista no está vacía, se devuelve True.
Producción :
Ejemplo 2: Imprimiendo un rango de números usando el ciclo while, el ciclo while se ejecutará hasta que la condición sea Verdadera.
Producción :
Ejemplo 3: con la ayuda de boolean, podemos enlazar nuestro programa.
Producción :
Ejemplo 4: Comprueba el mayor de dos números con la ayuda de condicionales. Con la ayuda de boolean podemos comparar los resultados y ejecutar en consecuencia
Producción :
HandCalcs es una biblioteca en Python para hacer cálculos automáticamente en Latex, pero de una manera que imita cómo podría formatearse la ecuación cuando se escribe a mano, escribe la fórmula matemática, respaldada por sustituciones numéricas, y luego la salida. Dado que HandCalcs indica el reemplazo numérico, las ecuaciones se vuelven mucho más fáciles de verificar y verificar manualmente.
Instalación
Ejecute el siguiente comando pip en la terminal.
La biblioteca HandCalcs en Python está diseñada para usarse en Jupyter Notebook o Jupyter Lab como magia celular.
Para utilizar la función de representación de la biblioteca HandCalcs, importe el módulo ejecutando import handcalcs.render , después de eso, simplemente use %%render en la parte superior de la celda en la que se representarán las ecuaciones o variables con HandCalcs.
Ejemplo 1: Suma de 2 números
Producción:
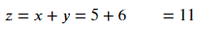
Ejemplo 2: Cálculo de la tan de una expresión.
Producción:
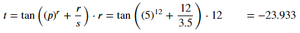
Ejemplo 3: Ecuación cuadrática con raíz cuadrada.
Producción:
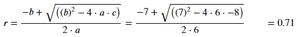
Etiquetas de comentarios
Mediante el uso de comentarios, HandCalcs llega a algunas conclusiones sobre cómo debe estructurarse la ecuación. Solo se puede utilizar un único comentario por celda.
Se pueden crear tres tipos de personalizaciones utilizando las etiquetas de comentario # en la parte superior de la celda:
1. # Parámetros: La estructura de visualización de las variables o parámetros se puede controlar usando la etiqueta # Parámetro, esta etiqueta se utiliza para clasificar la estructura de visualización en visualización vertical u visualización horizontal.
Ejemplo: Sin el comentario # Parámetro, todas las ecuaciones se mostrarán verticalmente
Producción:
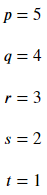
Ejemplo: esta vez se utiliza el comentario de parámetro #.
Producción:
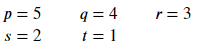
2. # Largo y # Corto: Como la etiqueta de comentario de # Parámetro se usa para controlar la estructura de visualización de las variables de la misma manera, las etiquetas de comentario # Largo y # Corto controlan la estructura de visualización de las ecuaciones, # Largo y # Corto se usan para mostrar ecuaciones vertical y horizontalmente respectivamente.
Ejemplo: Mostrar las ecuaciones horizontalmente usando # Short.
Producción:
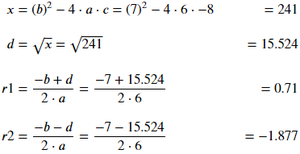
Ejemplo: Mostrar las ecuaciones verticalmente usando # Long.
Producción:
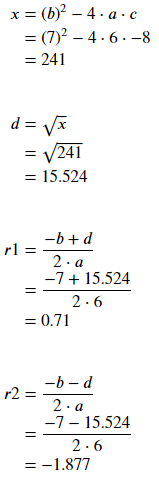
3. # Simbólico: El objetivo principal de la biblioteca HandCalcs es hacer la ecuación completa usando la sustitución numérica. Esto hace que la ecuación sea fácil de rastrear y validar. Sin embargo, puede haber situaciones en las que las ecuaciones se representen simbólicamente, la etiqueta de comentario # Symbolic cab representa simbólicamente ecuaciones de Latex.
Ejemplo:
Producción:
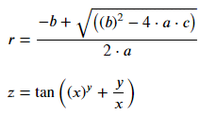
En este programa, necesitamos contar el número de vocales presentes en una string y mostrar esas vocales. Esto se puede hacer usando varios métodos. En este artículo, repasaremos algunos de los métodos populares para hacer esto de manera eficiente.
Ejemplos:
Contar vocales: String Way
En este método, almacenaremos todas las vocales en una string y luego seleccionaremos cada carácter de la string consultada y verificaremos si está en la string de vocales o no. La string de vocales consta de todas las vocales con ambos casos ya que no estamos ignorando los casos aquí. Si se encuentra la vocal, el conteo se incrementa y se almacena en una lista y finalmente se imprime.
Producción:
Contar vocales: Dictionary Way
Esto también realiza la misma tarea pero de una manera diferente. En este método, formamos un diccionario con las vocales y las incrementamos cuando encontramos una vocal. En este método, usamos el método case fold para ignorar los casos, después de lo cual formamos un diccionario de vocales con la clave como vocal. Esta es una forma mejor y más eficiente de verificar y encontrar el número de cada vocal presente en una string.
Producción:
Contando vocales: forma regular
También podemos utilizar este método para realizar esta tarea. Podemos usar la expresión regular para realizar esta tarea. Usamos el método re.findall() para encontrar todas las vocales en la lista de creación de strings con ellas. Usamos len on list para encontrar el total de vocales en una string.
Producción:
Una de las principales desventajas de cualquier técnica de agrupamiento es que es difícil evaluar su desempeño. Para abordar este problema, se desarrolló la métrica de V-Measure .
El cálculo de la medida V primero requiere el cálculo de dos términos:-
- Homogeneidad: una agrupación perfectamente homogénea es aquella en la que cada agrupación tiene puntos de datos que pertenecen a la misma etiqueta de clase. La homogeneidad describe la cercanía del algoritmo de agrupamiento a esta perfección.
- Completitud: una agrupación perfectamente completa es aquella en la que todos los puntos de datos que pertenecen a la misma clase se agrupan en el mismo grupo. La completitud describe la cercanía del algoritmo de agrupamiento a esta perfección.
Homogeneidad trivial: es el caso cuando el número de conglomerados es igual al número de puntos de datos y cada punto está exactamente en un conglomerado. Es el caso extremo cuando la homogeneidad es máxima mientras que la integridad es mínima.

Completitud trivial: es el caso cuando todos los puntos de datos se agrupan en un solo grupo. Es el caso extremo cuando la homogeneidad es mínima y la completitud es máxima.
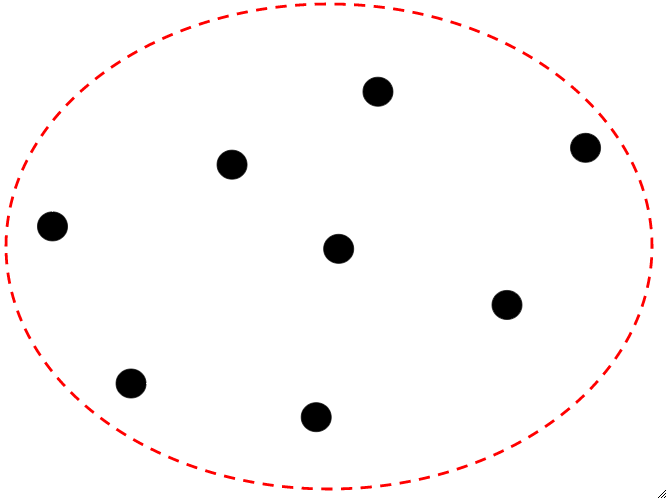
Suponga que cada punto de datos en los diagramas anteriores es de la etiqueta de clase diferente para Homogeneidad trivial y Completitud trivial.
Nota: El término homogéneo es diferente de completitud en el sentido de que, al hablar de homogeneidad, el concepto base es el del grupo respectivo, que verificamos si en cada grupo, cada punto de datos es de la misma etiqueta de clase. Al hablar de integridad, el concepto base es la etiqueta de clase respectiva que verificamos si los puntos de datos de cada etiqueta de clase están en el mismo grupo.
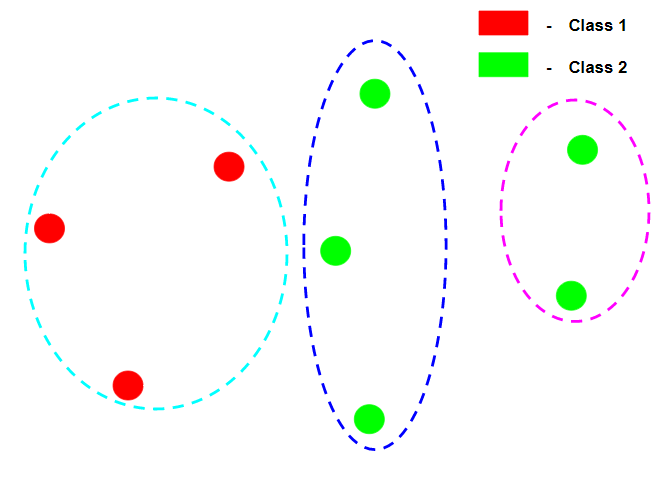
En el diagrama anterior, el agrupamiento es perfectamente homogéneo ya que en cada grupo los puntos de datos de son de la misma etiqueta de clase pero no está completo porque no todos los puntos de datos de la misma etiqueta de clase pertenecen a la misma etiqueta de clase.
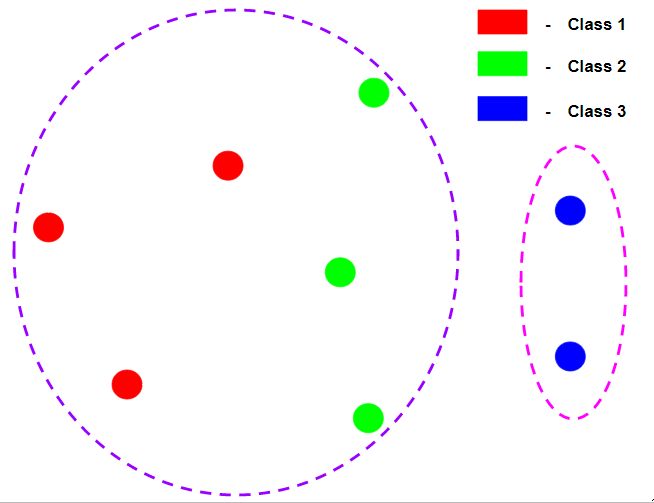
En el diagrama anterior, el agrupamiento está perfectamente completo porque todos los puntos de datos de la misma etiqueta de clase pertenecen al mismo grupo, pero no es homogéneo porque el primer grupo contiene puntos de datos de muchas etiquetas de clase.
Supongamos que hay N muestras de datos, C etiquetas de clase diferentes, K grupos y  una cantidad de puntos de datos que pertenecen a la clase c y al grupo k. Entonces la homogeneidad h viene dada por lo siguiente:
una cantidad de puntos de datos que pertenecen a la clase c y al grupo k. Entonces la homogeneidad h viene dada por lo siguiente:

dónde

y

La completitud c viene dada por lo siguiente:

dónde

y

Por lo tanto, la medida V ponderada  viene dada por lo siguiente:
viene dada por lo siguiente:

El factor  se puede ajustar para favorecer la homogeneidad o la integridad del algoritmo de agrupación.
se puede ajustar para favorecer la homogeneidad o la integridad del algoritmo de agrupación.
La principal ventaja de esta métrica de evaluación es que es independiente de la cantidad de etiquetas de clase, la cantidad de agrupaciones, el tamaño de los datos y el algoritmo de agrupamiento utilizado y es una métrica muy confiable.
El siguiente código demostrará cómo calcular la medida V de un algoritmo de agrupamiento. Los datos utilizados son la Detección de fraude con tarjetas de crédito que se pueden descargar desde Kaggle . El algoritmo de agrupamiento utilizado es la inferencia bayesiana variacional para el modelo de mezcla gaussiana .
Paso 1: Importación de las bibliotecas requeridas
Paso 2: Cargar y Limpiar los datos
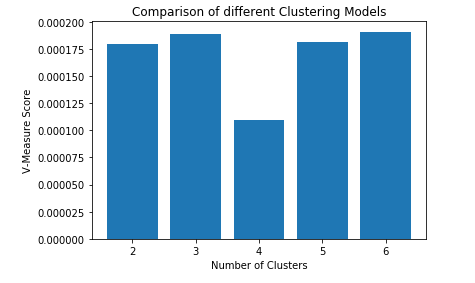
Paso 3: construir diferentes modelos de agrupamiento y comparar sus puntajes de V-Measure
En este paso, se construirán 5 modelos de agrupación en clústeres de K-Means diferentes y cada modelo agrupará los datos en una cantidad diferente de clústeres.
a) n_clusters = 2
b) n_clusters = 3
c) n_clusters = 4
d) n_clusters = 5
e) n_clusters = 6
Paso 4: Visualización de los resultados y comparación de los rendimientos
En este artículo veremos cómo podemos obtener el texto de un estado/tweet. Un tweet solo puede tener un máximo de 280 caracteres. El atributo de texto del objeto Estado nos proporciona el texto del estado.
Identificación del texto del estado en la GUI:
En el estado mencionado anteriormente, el texto del estado es:
Para obtener el texto del estado, tenemos que hacer lo siguiente:
- Identifique el ID de estado del estado de la GUI.
- Obtenga el objeto Estado del estado mediante el
get_status()método con el Id. de estado. Si queremos obtener el texto completo, pase otro parámetrotweet_mode = "extended".- De este objeto, obtenga el atributo de texto presente en él. Si queremos obtener el texto completo, busca el atributo full_text.
Ejemplo 1: Considere el siguiente estado:
Usaremos el ID de estado para obtener el estado. El ID de estado del estado mencionado anteriormente es 1272771459249844224.
Producción :
Ejemplo 2: Considere el siguiente estado:
Usaremos el ID de estado para obtener el estado. El ID de estado del estado mencionado anteriormente es 1272479136133627905. Esta vez buscaremos el texto completo del estado. Mientras usa el get_status()método, también pase tweet_mode = "extended"como parámetro. Luego obtenga el texto completo usando el atributo full_text.
Producción :
Los ejes en todos los gráficos que usan Matplotlib son lineales por defecto, el método yscale () de la biblioteca matplotlib.pyplot se puede usar para cambiar la escala del eje y a logarítmica.
El método yscale() toma un solo valor como parámetro que es el tipo de conversión de la escala, para convertir los ejes y a escala logarítmica le pasamos la palabra clave “log” o la clase matplotlib.scale.LogScale al método yscale.
Sintaxis: matplotlib.pyplot.yscale(valor, **kwargs)
Parámetros:
- Valor = { “lineal”, “log”, “symlog”, “logit”, … }
- **kwargs = Se aceptan diferentes argumentos de palabras clave, según la escala (matplotlib.scale.LinearScale, LogScale, SymmetricalLogScale, LogitScale)
Devoluciones : Convierte los ejes y al tipo de escala dado. (Aquí usamos el tipo de escala «log»)
Ejemplo de escala lineal:
Producción:
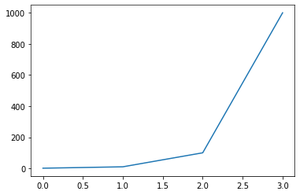
Escala lineal
Ejemplo de escala logarítmica:
Producción:

Eje y logarítmico
C: C es un lenguaje de programación estructurado, de nivel medio y de propósito general que fue desarrollado en Bell Laboratories entre 1972 y 1973 por Dennis Ritchie. Fue construido como base para el desarrollo del sistema operativo UNIX. Al ser un lenguaje de nivel medio, C carece de las funciones integradas que son características de los lenguajes de alto nivel, pero proporciona todos los componentes básicos que necesitan los desarrolladores. C sigue el enfoque orientado a la estructura, es decir, el enfoque de arriba hacia abajo que fragmenta un programa en funciones más pequeñas.
Lo que hace que C sea único es que está optimizado para tareas de administración de memoria de bajo nivel que se escribieron previamente en lenguaje ensamblador (el código sigue el formato hexadecimal que puede acceder directamente a las ubicaciones de memoria). Esta es precisamente la razón por la que C se usa en la construcción de arquitecturas de sistemas operativos. Incluso hoy en día, tanto los derivados de UNIX como los de Linux dependen en gran medida de C para muchas funciones.
Python: Python es un lenguaje de programación de alto nivel y propósito general que fue desarrollado por Guido Rossum en 1989. Lo que hace que Python sea asombroso es su sintaxis simple que es casi similar al idioma inglés y su capacidad de escritura dinámica. La sintaxis sencilla permite una fácil lectura del código.
Además, al ser un lenguaje interpretado, Python es un lenguaje ideal para secuencias de comandos y desarrollo rápido de aplicaciones en la mayoría de las plataformas y es muy popular entre los desarrolladores. Los lenguajes de secuencias de comandos incorporan funcionalidades interactivas y dinámicas a través de aplicaciones basadas en web.

| Métricas | C | Python |
|---|---|---|
| Introducción | C es un lenguaje de programación computacional procedimental de propósito general. | Python es un lenguaje de programación interpretado, de alto nivel y de propósito general. |
| Velocidad | Los programas compilados se ejecutan más rápido en comparación con los programas interpretados. | Los programas interpretados se ejecutan más lentamente en comparación con los programas compilados. |
| Uso | La sintaxis del programa es más difícil que Python. | Es más fácil escribir un código en Python ya que el número de líneas es comparativamente menor. |
| Declaración de variables | En C, el tipo de una variable debe declararse cuando se crea, y solo se le deben asignar valores de ese tipo. | No es necesario declarar el tipo de variable. Las variables no están tipificadas en Python. Una variable determinada se puede atascar en valores de diferentes tipos en diferentes momentos durante la ejecución del programa |
| Depuración de errores | En C, la depuración de errores es difícil ya que es un lenguaje dependiente del compilador. Esto significa que toma todo el código fuente, lo compila y luego muestra todos los errores. | La depuración de errores es simple. Esto significa que solo toma una instrucción a la vez y compila y ejecuta simultáneamente. Los errores se muestran instantáneamente y la ejecución se detiene en esa instrucción. |
| Mecanismo de cambio de nombre de función | C no admite el mecanismo de cambio de nombre de función. Esto significa que la misma función no puede ser utilizada por dos nombres diferentes. | Admite el mecanismo de cambio de nombre de función, es decir, la misma función puede ser utilizada por dos nombres diferentes. |
| Complejidad | La sintaxis de un programa en C es más difícil que la de Python. | La sintaxis de los programas de Python es fácil de aprender, escribir y leer. |
| Gestión de la memoria | En C, el programador tiene que administrar la memoria por su cuenta. | Python utiliza un recolector de basura automático para la gestión de la memoria. |
| Aplicaciones | C se usa generalmente para aplicaciones relacionadas con el hardware. | Python es un lenguaje de programación de propósito general. |
| Funciones integradas | C tiene un número limitado de funciones integradas. | Python tiene una gran biblioteca de funciones integradas. |
| Implementación de estructuras de datos | La implementación de estructuras de datos requiere que sus funciones se implementen explícitamente | Facilita la implementación de estructuras de datos con funciones integradas de inserción y adición. |
| Punteros | Los punteros están disponibles en C. | No hay funcionalidad de punteros disponible en Python. |
Conclusión
Surge una pregunta difícil sobre cuándo usar Python y cuándo usar C. Los lenguajes C vs Python son similares pero tienen muchas diferencias clave. Estos lenguajes son lenguajes útiles para desarrollar diversas aplicaciones. La diferencia entre C y Python es que Python es un lenguaje multiparadigma y C es un lenguaje de programación estructurado. Python es un lenguaje de propósito general que se utiliza para el aprendizaje automático, el procesamiento del lenguaje natural, el desarrollo web y muchos más. C se utiliza principalmente para el desarrollo de aplicaciones relacionadas con el hardware, como sistemas operativos, controladores de red. En el competitivo mercado actual, no basta con dominar un solo lenguaje de programación. Para ser un programador versátil y competente, debe dominar varios idiomas.
Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
El método de Pandas str.len() se utiliza para determinar la longitud de cada string en una serie de Pandas. Este método es solo para series de strings.
Dado que este es un método de string, .str debe tener el prefijo cada vez antes de llamar a este método. De lo contrario, dará un error.
Sintaxis: Serie.str.len()
Tipo de retorno: Serie de valores enteros. Los valores NULL también pueden estar presentes dependiendo de la serie de llamadas.
Para descargar el CSV utilizado en el código, haga clic aquí.
En los siguientes ejemplos, el marco de datos utilizado contiene datos de algunos jugadores de la NBA. La imagen del marco de datos antes de cualquier operación se adjunta a continuación.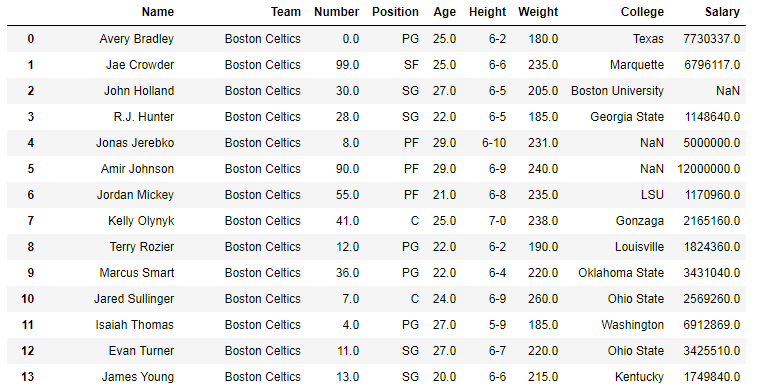
Ejemplo #1: Cálculo de la longitud de la serie de strings (dtype=str)
En este ejemplo, la longitud de la string de la columna Nombre se calcula utilizando el método str.len(). El dtype de la serie ya es una string. Por lo tanto, no hay necesidad de conversión de tipos de datos. Antes de realizar cualquier operación, se eliminan las filas nulas para evitar errores.
Salida:
como se muestra en la imagen de salida, se devuelve la longitud de cada string en la columna de nombre. 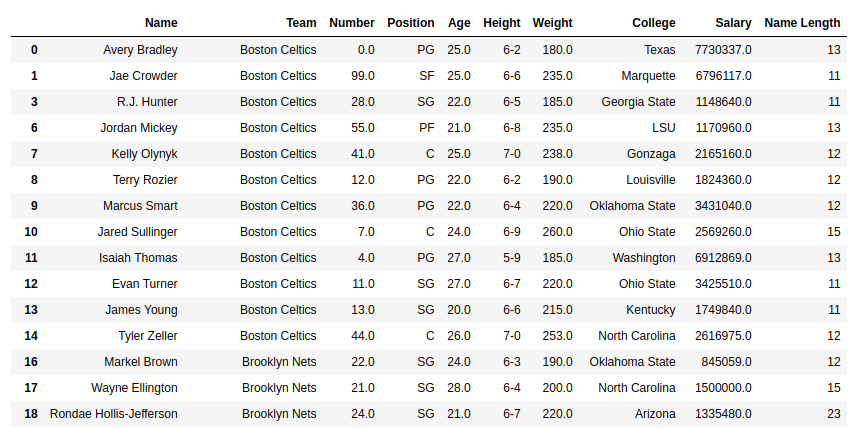
Nota:
- Este método no cuenta la longitud de las series enteras o flotantes. Dará un error ya que no es una serie de strings. La serie debe convertirse primero (se muestra en el siguiente ejemplo)
- No hay ningún parámetro para manejar valores nulos. Un valor nulo también devolvería un valor nulo en la string de salida.
Ejemplo #2:
En este ejemplo, la longitud de la columna de salario se calcula usando el método str.len(). Dado que la serie se importa como float64 dtype, primero se convierte en string mediante el método .astype().
Salida:
como se muestra en la salida, la longitud de la serie int o float solo se puede calcular convirtiéndola en string dtype.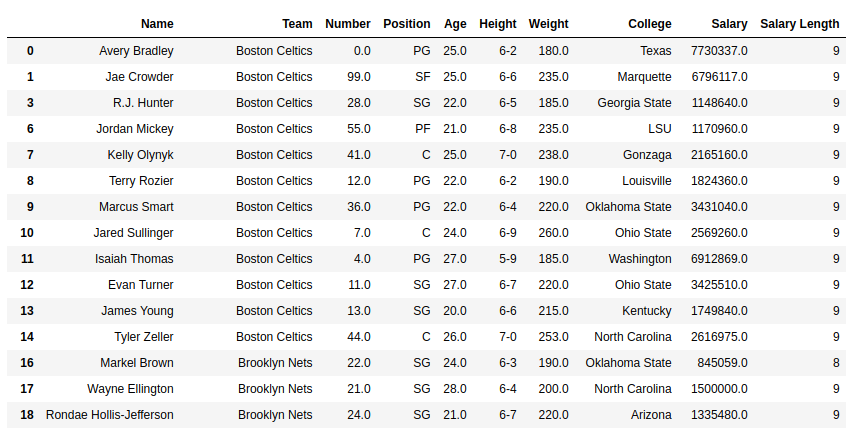
Insertar una fila en Pandas DataFrame es un proceso muy sencillo y ya hemos discutido enfoques sobre cómo insertar filas al comienzo de Dataframe . Ahora, analicemos las formas en que podemos insertar una fila en cualquier posición en el marco de datos que tenga un índice basado en enteros.
Solución #1: No existe ninguna función incorporada en pandas que nos ayude a insertar una fila en cualquier posición específica en el marco de datos dado. Entonces, vamos a escribir nuestra propia función personalizada para lograr el resultado.
Nota: insertar filas entre filas en Pandas Dataframe es una operación ineficiente y el usuario debe evitarla.
Producción :
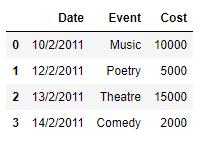
Ahora escribiremos una función personalizada para insertar una fila en cualquier posición dada en el marco de datos.
Producción :
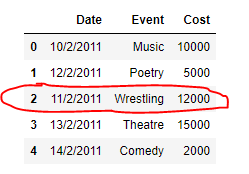
En caso de que el número de fila dado no sea válido, digamos que el número total de filas en el marco de datos es 100, entonces el valor máximo de número de fila puede ser 101, es decir, agregar la fila en el último marco de datos. Cualquier número mayor que 101 dará un mensaje de error .
Ejemplo #2: Otra función personalizada que usará la función Pandas.concat() para insertar una fila en cualquier posición dada en el marco de datos.
Producción :
Una función personalizada para insertar una fila en cualquier posición dada en el marco de datos.
Producción :
El módulo Python de Selenium está diseñado para realizar pruebas automatizadas con Python. Los enlaces de Selenium Python proporcionan una API simple para escribir pruebas funcionales/de aceptación utilizando Selenium WebDriver. Para abrir una página web usando Selenium Python, consulte – Navegación de enlaces usando el método get – Selenium Python . El simple hecho de poder ir a lugares no es terriblemente útil. Lo que realmente nos gustaría hacer es interactuar con las páginas o, más específicamente, con los elementos HTML dentro de una página. Existen múltiples estrategias para encontrar un elemento usando Selenium, verifique – Estrategias de localización
Este artículo gira en torno a cómo usar el screenshotmétodo en Selenium. screenshotEl método se utiliza para guardar una captura de pantalla del elemento actual en un archivo PNG. Devuelve falso si hay algún IOError, de lo contrario devuelve True.
Args: nombre de
archivo : la ruta completa en la que desea guardar su captura de pantalla. Esto debería terminar con una extensión .png.
Ejemplo –
Para encontrar un elemento, uno necesita usar una de las estrategias de localización, por ejemplo,
Además, para encontrar múltiples elementos, podemos usar:
Ahora uno puede hacer clic en una captura de pantalla de este campo con
¿Cómo usar el método del elemento de captura de pantalla en Selenium Python?
Intentemos obtener el encabezado de geeksforgeeks y luego hagamos clic en su captura de pantalla.
Programa –
Producción-
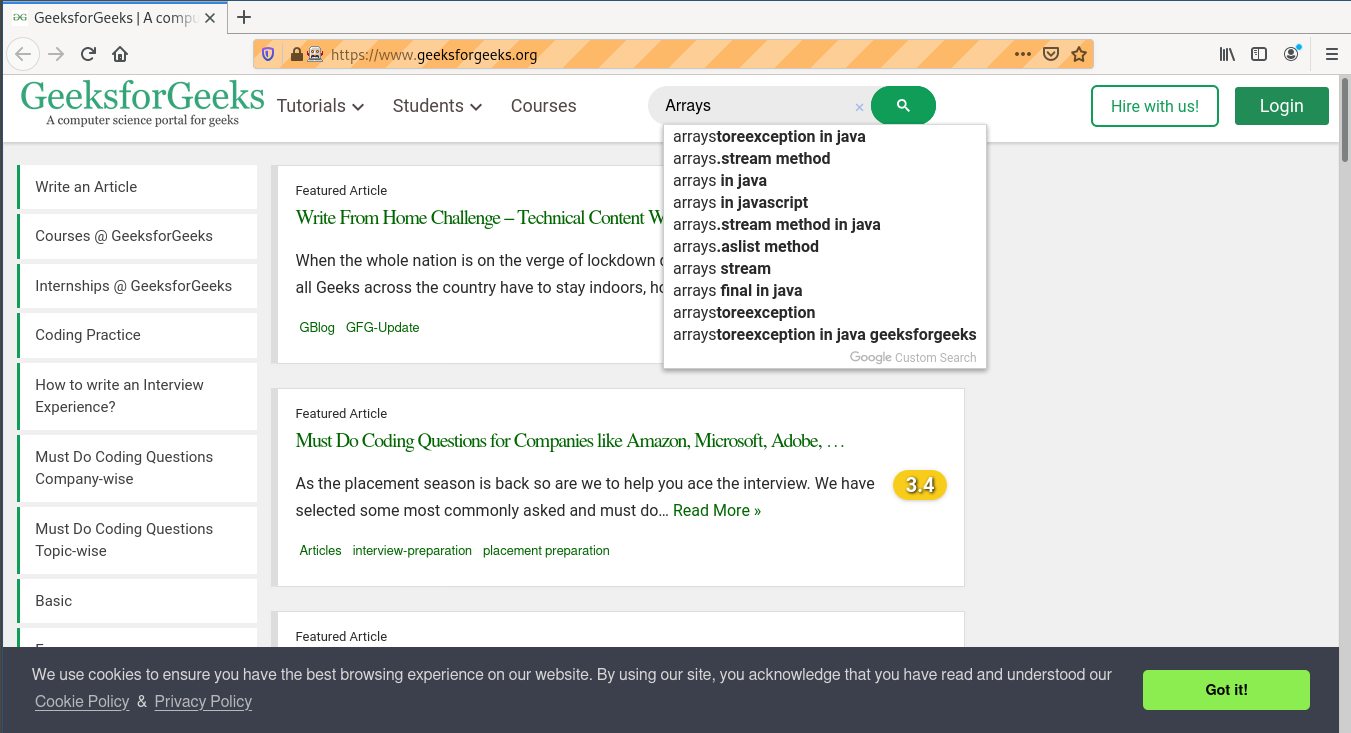
Captura de pantalla –
¿Escribir código en un comentario? Utilice ide.geeksforgeeks.org , genere un enlace y compártalo aquí.
Antes de comenzar con cómo instalar pip para Python en macOS, primero veamos la introducción básica a Python.
Python es un lenguaje de programación de alto nivel y propósito general ampliamente utilizado. Python es un lenguaje de programación que le permite trabajar rápidamente e integrar sistemas de manera más eficiente. PIP es un sistema de administración de paquetes que se utiliza para instalar y administrar paquetes/bibliotecas de software escritos en Python. Estos archivos se almacenan en un gran «repositorio en línea» denominado Python Package Index (PyPI). pip usa PyPI como la fuente predeterminada para los paquetes y sus dependencias. En este artículo, veremos cómo instalar PIP en una Mac. Usando pip puede instalar cualquier paquete usando la siguiente sintaxis:
Sintaxis de pip
Descarga e instala Pip en macOS
pip se puede descargar e instalar usando la línea de comando siguiendo los siguientes pasos:
Paso 1: descargue el archivo get-pip.py (https://bootstrap.pypa.io/get-pip.py) y guárdelo en el mismo directorio donde está instalado Python. o Use el siguiente comando para descargar pip directamente
Paso 2: ahora ejecute el archivo descargado usando el siguiente comando
Paso 3: espera el proceso de instalación.
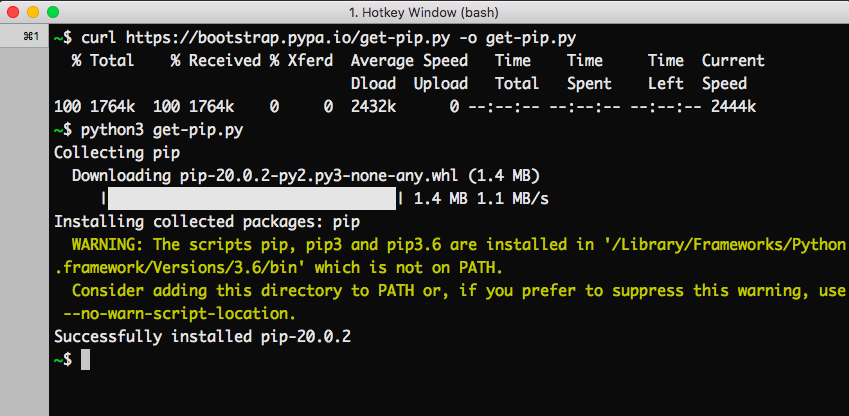
¡Voila! pip ahora está instalado en su sistema.
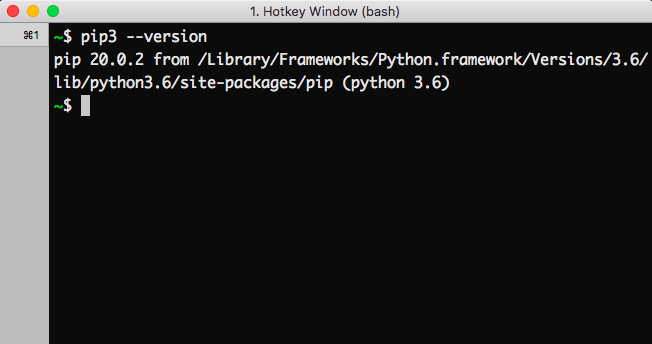
Verificación del proceso de Instalación
Uno puede verificar fácilmente si el pip se ha instalado correctamente al realizar una verificación de versión en el mismo. Simplemente vaya a la línea de comando y ejecute el siguiente comando:
Cómo actualizar PIP en una Mac
Puede usar el siguiente comando en su terminal para actualizar su pip.
Cómo instalar una versión específica de pip
Para instalar una versión específica, puede ingresar el siguiente número de versión para instalar la versión específica.
Cómo desinstalar cualquier instalación anterior de pip
Puede usar uno de los comandos para desinstalar el comando pip según su sistema.
En este artículo veremos cómo podemos verificar si el cuadro de número tiene un atributo dado o no, los atributos son básicamente las cualidades del cuadro de número, algunos atributos son similares a las banderas del cuadro de número. Hay muchos atributos disponibles para el cuadro de número como WA_AcceptDrops, WA_AlwaysShowToolTips, etc.
Para hacer esto, usamos testAttributeel método con el objeto de cuadro de número.
Sintaxis: spin_box.testAttribute((Qt.WA_Disabled)
Argumento: toma el objeto QWidget Attribute como argumento
Return : Devuelve bool
A continuación se muestra la implementación.
Producción :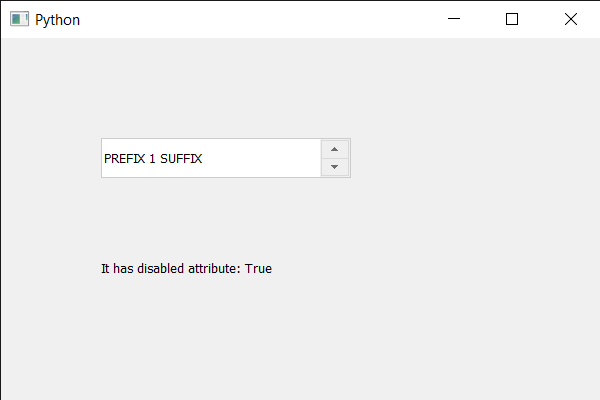
Un marco de datos es una estructura de datos bidimensional que tiene múltiples filas y columnas. En un marco de datos, los datos se alinean solo en forma de filas y columnas. Un marco de datos puede realizar operaciones tanto aritméticas como condicionales. Tiene tamaño mutable.
Módulos necesarios:
concat() Producción:

Código #2: DataFrames Merge
Pandas proporciona una sola función, merge(), como punto de entrada para todas las operaciones estándar de combinación de bases de datos entre objetos DataFrame.
Producción:
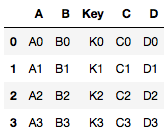
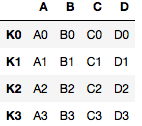
Código n.º 3: unión de tramas de datos
Producción:
Una función es un conjunto de sentencias que toman entradas, hacen algún cálculo específico y producen salidas. La idea es juntar algunas tareas comunes o repetidas y crear una función para que, en lugar de escribir el mismo código una y otra vez para diferentes entradas, podamos llamar a la función.
Las funciones que vienen fácilmente con Python se denominan funciones integradas. Python proporciona funciones integradas como print(), etc., pero también podemos crear sus propias funciones. Estas funciones se conocen como funciones definidas por el usuario .
Tabla de contenidos
Funciones definidas por el usuario
Todas las funciones escritas por cualquiera de nosotros entran en la categoría de funciones definidas por el usuario. A continuación se muestran los pasos para escribir funciones definidas por el usuario en Python.
- En Python, la palabra clave def se usa para declarar funciones definidas por el usuario.
- Un bloque de instrucciones con sangría sigue al nombre de la función y los argumentos que contienen el cuerpo de la función.
Sintaxis:
Ejemplo:
Producción:
Función parametrizada
La función puede tomar argumentos, también llamados parámetros, como entrada dentro de los paréntesis de apertura y cierre, justo después del nombre de la función seguido de dos puntos.
Sintaxis:
Ejemplo:
Producción:
Argumentos predeterminados
Un argumento predeterminado es un parámetro que asume un valor predeterminado si no se proporciona un valor en la llamada de función para ese argumento. El siguiente ejemplo ilustra los argumentos predeterminados.
Ejemplo:
Producción:
Nota: Para obtener más información sobre los argumentos predeterminados, haga clic aquí .
Argumentos de palabras clave
La idea es permitir que la persona que llama especifique el nombre del argumento con valores para que la persona que llama no necesite recordar el orden de los parámetros.
Ejemplo:
Producción:
Argumentos de longitud variable
Podemos tener un número de argumentos tanto normal como de palabra clave variable.
- La sintaxis especial *args en las definiciones de funciones en Python se usa para pasar un número variable de argumentos a una función. Se utiliza para pasar una lista de argumentos de longitud variable sin palabras clave.
- La sintaxis especial **kwargs en las definiciones de funciones en python se usa para pasar una lista de argumentos de longitud variable con palabras clave. Usamos el nombre kwargs con la estrella doble. La razón es que la estrella doble nos permite pasar argumentos de palabras clave (y cualquier número de ellos).
Ejemplo:
Producción:
Nota: Para obtener más información sobre los argumentos de longitud variable, haga clic aquí .
¿Pasar por referencia o pasar por valor?
Una cosa importante a tener en cuenta es que en Python cada nombre de variable es una referencia. Cuando pasamos una variable a una función, se crea una nueva referencia al objeto. El paso de parámetros en Python es el mismo que el paso de referencias en Java. Para confirmar, la función id() integrada de Python se usa en el siguiente ejemplo.
Ejemplo:
Value passed: 12 id: 11094656 Value received: 12 id: 11094656
Producción:
Si el valor de la variable anterior se cambia dentro de una función, creará una variable diferente como un número que es inmutable. Sin embargo, si un objeto de lista mutable se modifica dentro de la función, los cambios también se reflejan fuera de la función.
Ejemplo:
Producción:
Función con valor de retorno
A veces, es posible que necesitemos que el resultado de la función se use en un proceso posterior. Por lo tanto, una función también debe devolver un valor cuando finaliza su ejecución. Esto se puede lograr mediante una declaración de devolución.
Se utiliza una declaración de retorno para finalizar la ejecución de la llamada de función y «devuelve» el resultado (el valor de la expresión que sigue a la palabra clave de retorno) a la persona que llama. Las sentencias posteriores a las sentencias de retorno no se ejecutan. Si la declaración de devolución no tiene ninguna expresión, se devuelve el valor especial Ninguno.
Sintaxis:
Ejemplo:
Producción:
Dadas dos listas de listas, escriba un programa Python para encontrar la intersección entre las dos listas dadas.
Ejemplos:
Enfoque #1: Ingenuo (Lista de comprensión)
El enfoque de fuerza bruta o ingenuo para encontrar la intersección de la lista de listas es usar la comprensión de listas o simplemente un bucle for .
[['a', 'c'], ['d', 'e']]
Enfoque n. ° 2: usar Establecer intersection()
Este es un método eficiente en comparación con el enfoque ingenuo. Primero convertimos ambas listas de listas en listas de tuplas usando map() porque los conjuntos de Python son compatibles con tuplas, no con listas. Luego, simplemente encontramos Establecer intersection() de ambas listas.
[['d', 'e'], ['a', 'c']]
Python es un lenguaje de programación orientado a objetos, todo en Python está relacionado con objetos, métodos y propiedades. Una clase es un plano definido por el usuario o un prototipo, que podemos usar para crear los objetos de una clase. La clase se define utilizando la palabra clave class.
ejemplo de clase
En primer lugar, debemos comprender el método integrado __init__() para comprender el significado de las clases. Cada vez que se inicia la clase, siempre se ejecuta un método llamado __init__(). Se usa un método __init__() para asignar los valores a las propiedades del objeto o para realizar el otro método que se requiere para completar cuando se crea el objeto.
Ejemplo: clase con método __init__()
Producción:
Clase interna en Python
Una clase definida en otra clase se conoce como clase interna o clase anidada. Si un objeto se crea utilizando una clase secundaria significa una clase interna, entonces el objeto también puede ser utilizado por la clase principal o la clase raíz. Una clase principal puede tener una o más clases internas, pero generalmente se evitan las clases internas.
Podemos hacer que nuestro código esté aún más orientado a objetos usando una clase interna. Un solo objeto de la clase puede contener múltiples subobjetos. Podemos usar múltiples subobjetos para darle una buena estructura a nuestro programa.
Ejemplo:
- Primero, creamos una clase y luego el constructor de la clase.
- Después de crear una clase, crearemos otra clase dentro de esa clase, la clase dentro de otra clase se llamará clase interna.
Producción:
¿Por qué clase interna?
Para la agrupación de dos o más clases. Supongamos que tenemos dos clases remoto y batería. Cada control remoto necesita una batería, pero no se utilizará una batería sin control remoto. Entonces, hacemos de la batería una clase interna para el control remoto. Nos ayuda a ahorrar código. Con la ayuda de la clase interna o la clase anidada, podemos ocultar la clase interna del mundo exterior. Por lo tanto, Ocultar el código es otra buena característica de la clase interna. Al usar la clase interna, podemos comprender fácilmente las clases porque las clases están estrechamente relacionadas. No necesitamos buscar clases en todo el código, están todas casi juntas. Aunque las clases internas o anidadas no se usan ampliamente en Python, será una mejor característica para implementar el código porque es fácil de organizar cuando usamos una clase interna o una clase anidada.
Sintaxis:
Los tipos de clases internas son los siguientes:
- Clase interna múltiple
- Clase interna multinivel
Clase interna múltiple
La clase contiene una o más clases internas conocidas como múltiples clases internas. Podemos tener múltiples clases internas en una clase, es fácil implementar múltiples clases internas.
Ejemplo: clase interna múltiple
Producción:
Clase interna multinivel
La clase contiene una clase interna y esa clase interna nuevamente contiene otra clase interna, esta jerarquía se conoce como la clase interna multinivel.
Ejemplo: clase interna multinivel
Producción:
Esta es una clase externa Esta es una clase interna Esta es una clase interna de clase interna significa clase interna multinivel
En este artículo, aprenderemos un diagrama de dispersión simple con Altair usando python. Altair es una de las últimas bibliotecas de visualización de datos interactivos en python. Altair se basa en vega y vegalite : una gramática de gráficos interactivos. Aquí importaremos la biblioteca de Altair para usarla. Y luego cargaremos los datos meteorológicos de Seattle desde vega_dataset .
Enfoque paso a paso:
- Importar módulos.
- Asigne un conjunto de datos y conviértalo en un marco de datos.
- Mostrar conjunto de datos.
Producción:
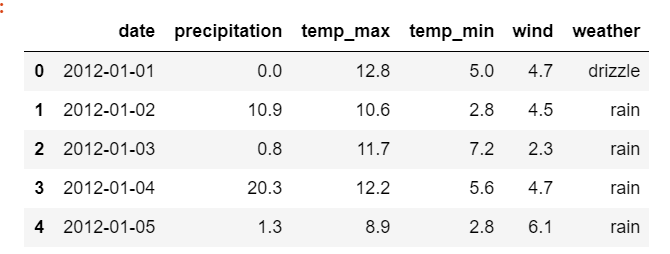
- Ahora hagamos el diagrama de dispersión usando la biblioteca de Altair . Para esto, usamos la función Chart() en Altair para cargar los datos y luego usamos la función mark_point() para hacer un diagrama de dispersión. Luego usamos los ejes X e Y de la estética para codificar() la función. Por lo tanto, obtenemos el diagrama de dispersión simple de dos variables como se muestra a continuación:
Producción:
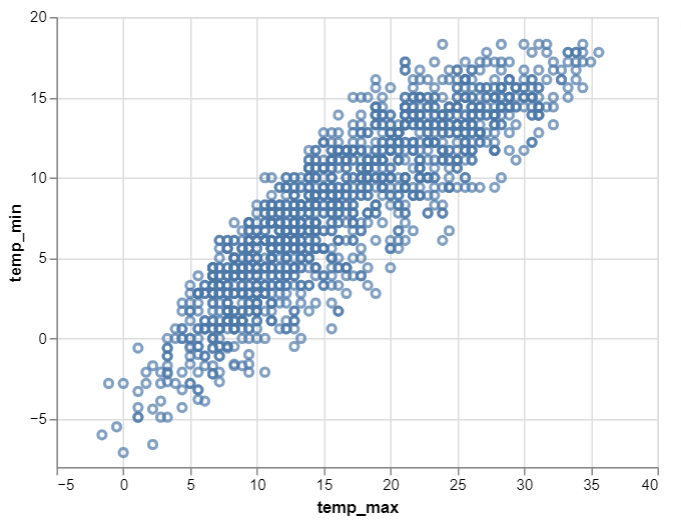
A continuación se muestra el programa completo basado en el enfoque anterior:
Producción:
MongoDB es una base de datos NoSql que se puede utilizar para almacenar datos requeridos por diferentes aplicaciones. Python se puede utilizar para acceder a las bases de datos de MongoDB. Python requiere un controlador para acceder a las bases de datos. PyMongo permite interactuar con la base de datos MongoDB desde aplicaciones Python. El paquete pymongo actúa como un controlador de Python nativo para MongoDB. Pymongo proporciona comandos que se pueden usar en aplicaciones de Python para realizar la acción requerida en MongoDB. MongoDB ofrece tres métodos para insertar registros o documentos en la base de datos que son los siguientes:
- insert() : se utiliza para insertar un documento o documentos en una colección. Si la colección no existe, insert() creará la colección y luego insertará los documentos especificados.
Sintaxis
db.collection.insert(<documento o conjunto de documentos>,
{
writeConcern: <documento>,
ordenado: <booleano>
}
)
Parámetro
- <documento>: El documento o registro que se va a almacenar en la base de datos
- escribir preocupación: opcional.
- ordenado: Opcional. Se puede establecer en verdadero o falso.
Ejemplo:
Producción:

- insertOne() : se utiliza para insertar un solo documento o registro en la base de datos. Si la colección no existe, entonces el método insertOne() crea la colección primero y luego inserta el documento especificado.
Sintaxis
db.collection.insertOne(<documento>,
{
writeConcern: <documento>
}
)
Parámetro
- <documento> El documento o registro que se almacenará en la base de datos
- escribir preocupación: opcional.
Valor de retorno: Devuelve el _id del documento insertado en la base de datos.
Nota: El comando de Pymongo para insertOne() es insert_one()
Ejemplo:
Producción:

- insertarMuchos()
Sintaxis
db.collection.insertMany([ <documento 1>, <documento 2>, … ],
{
writeConcern: <documento>,
ordenado: <booleano>
}
)
Parámetro
- <documentos> El documento o registro que se almacenará en la base de datos .
- escribir preocupación: opcional.
- ordenado: Opcional. Se puede establecer en verdadero o falso.
Valor de retorno: Devuelve los _ids de los documentos insertados en la base de datos.
Nota: El comando de Pymongo para insertMany() es insert_many()
Ejemplo:
Producción:
 .math-table { borde-colapso: colapsar; ancho: 100%; } .math-table td { borde: 1px sólido #5fb962; alineación de texto: izquierda! importante; relleno: 8px; } .math-table th { borde: 1px sólido #5fb962; relleno: 8px; } .math-table tr>th{ color de fondo: #c6ebd9; alineación vertical: medio; } .math-table tr:nth-child(odd) { background-color: #ffffff; }
.math-table { borde-colapso: colapsar; ancho: 100%; } .math-table td { borde: 1px sólido #5fb962; alineación de texto: izquierda! importante; relleno: 8px; } .math-table th { borde: 1px sólido #5fb962; relleno: 8px; } .math-table tr>th{ color de fondo: #c6ebd9; alineación vertical: medio; } .math-table tr:nth-child(odd) { background-color: #ffffff; }
| insertar() | insertOne() | insertarMuchos() |
|---|---|---|
| El comando equivalente de Pymongo es insert() | El comando equivalente de Pymongo es insert_one() | El comando equivalente de Pymongo es insert_many() |
| En desuso en las versiones más nuevas del motor mongo | Utilizado en versiones más nuevas del motor mongo | Utilizado en versiones más nuevas del motor mongo |
| lanza WriteResult.writeConcernError y WriteResult.writeError para errores de preocupación de escritura y no escritura respectivamente | lanza una excepción writeError o writeConcernError. | lanza una excepción BulkWriteError. |
| compatible con db.colección.explicar() | no compatible con db.collection.explain() | no compatible con db.collection.explain() |
| Si order se establece en true y algún documento informa de un error, los documentos restantes no se insertan. Si order se establece en false, los documentos restantes se insertan incluso si se produce un error. | Si se informa un error para el documento, no se inserta en la base de datos. | Si order se establece en true y algún documento informa de un error, los documentos restantes no se insertan. Si order se establece en false, los documentos restantes se insertan incluso si se produce un error. |
| devuelve un objeto que contiene el estado de la operación. | devuelve el insert_id del documento insertado | devuelve los insert_ids de los documentos insertados |
En este artículo, veremos cómo podemos establecer el color de fondo en la parte de edición de línea del cuadro combinado cuando se pasa el mouse sobre él, la parte de edición de línea del cuadro combinado es en la que se muestra el texto y se edita.
Para agregar color de fondo a la parte de edición de línea del cuadro combinado cuando se pasa el mouse sobre él, haga lo siguiente:
1. Cree un cuadro combinado
2. Cree un widget de edición de línea
3. Cambie el color de fondo del widget de edición de línea para pasar el mouse sobre él
4. Agregue el widget de edición de línea al cuadro combinado
Sintaxis:
A continuación se muestra la implementación:
Producción :
El módulo OS en Python proporciona funciones para interactuar con el sistema operativo. OS viene bajo los módulos de utilidad estándar de Python. Este módulo proporciona una forma portátil de usar la funcionalidad dependiente del sistema operativo.
os.read()El método en Python se usa para leer como máximo n bytes del archivo asociado con el descriptor de archivo dado.
Si se ha llegado al final del archivo mientras se leen los bytes del descriptor de archivo dado, el os.read()método devolverá un objeto de bytes vacío para todos los bytes que quedan por leer.
Un descriptor de archivo es un valor entero pequeño que corresponde a un archivo que ha sido abierto por el proceso actual. Se utiliza para realizar varias operaciones de E/S de nivel inferior como lectura, escritura, envío, etc.
Nota : os.read()el método está diseñado para operaciones de bajo nivel y debe aplicarse a un descriptor de archivo como lo devuelve el método os.open()o .os.pipe()
Sintaxis: os.read(fd, n)
Parámetro:
fd : un descriptor de archivo que representa el archivo que se va a leer.
n : un valor entero que indica el número de bytes que se leerán del archivo asociado con el descriptor de archivo dado fd.Tipo de devolución: este método devuelve una string de bytes que representa los bytes leídos del archivo asociado con el descriptor de archivo fd.
Considere el siguiente texto como el contenido del archivo llamado Python_intro.txt .
Python es un lenguaje de programación de alto nivel y propósito general ampliamente utilizado. Inicialmente fue diseñado por Guido van Rossum en 1991 y desarrollado por Python Software Foundation. Fue desarrollado principalmente para enfatizar la legibilidad del código y su sintaxis permite a los programadores expresar conceptos en menos líneas de código. Python es un lenguaje de programación que le permite trabajar rápidamente e integrar sistemas de manera más eficiente.
b'Python is a widely used general-purpose, high leve'
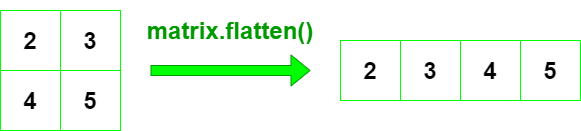
Analicemos cómo aplanar una array usando NumPy en Python. Usando la función ndarray.flatten() podemos aplanar una array a una dimensión en python.
Sintaxis: numpy_array.flatten(order=’C’)
- orden: ‘C’ significa aplanar en fila principal. ‘F’ significa aplanar en columna principal. ‘A’ significa aplanar en orden de columna principal si a es Fortran contiguo en la memoria, orden de fila principal de lo contrario. K’ significa aplanar a en el orden en que aparecen los elementos en la memoria. El valor predeterminado es ‘C’.
Retorno: Array 1-D aplanada
Ejemplo 1:
Producción:
Ejemplo 2:
Producción:
Ejemplo 3:
Producción:
Este artículo analiza los conceptos básicos de la regresión lineal y su implementación en el lenguaje de programación Python.
La regresión lineal es un método estadístico para modelar relaciones entre una variable dependiente con un conjunto dado de variables independientes.

Nota: En este artículo, nos referimos a las variables dependientes como respuestas y a las variables independientes como características para simplificar.
Para proporcionar una comprensión básica de la regresión lineal, comenzamos con la versión más básica de la regresión lineal, es decir, la regresión lineal simple .
Regresión lineal simple
La regresión lineal simple es un enfoque para predecir una respuesta usando una característica única .
Se supone que las dos variables están linealmente relacionadas. Por lo tanto, tratamos de encontrar una función lineal que prediga el valor de respuesta (y) con la mayor precisión posible como función de la característica o variable independiente (x).
Consideremos un conjunto de datos donde tenemos un valor de respuesta y para cada característica x:

Para generalizar, definimos:
x como vector de características , es decir, x = [x_1, x_2, …., x_n],
y como vector de respuesta , es decir, y = [y_1, y_2, …., y_n]
para n observaciones (en el ejemplo anterior , n=10).
Un diagrama de dispersión del conjunto de datos anterior se parece a: –
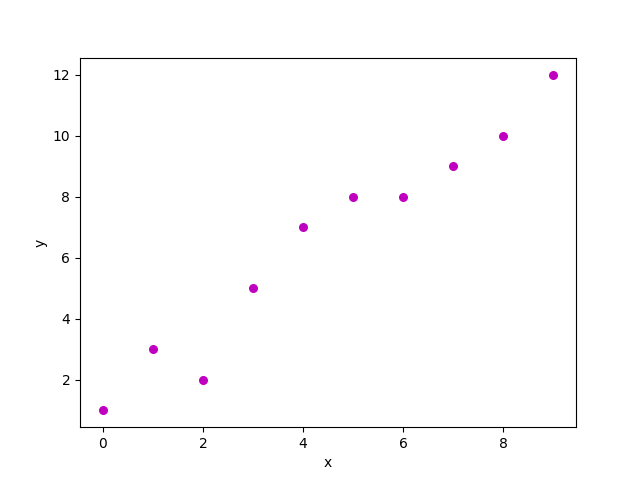
Ahora, la tarea es encontrar una línea que encaje mejor en el diagrama de dispersión anterior para que podamos predecir la respuesta para cualquier valor de característica nueva. (es decir, un valor de x no presente en un conjunto de datos)
Esta línea se llama línea de regresión .
La ecuación de la línea de regresión se representa como:
Aquí,
- h(x_i) representa el valor de respuesta pronosticado para la i -ésima observación.
- b_0 y b_1 son coeficientes de regresión y representan la intersección y y la pendiente de la línea de regresión, respectivamente.
Para crear nuestro modelo, debemos “aprender” o estimar los valores de los coeficientes de regresión b_0 y b_1. Y una vez que hayamos estimado estos coeficientes, ¡podemos usar el modelo para predecir las respuestas!
En este artículo, vamos a utilizar el principio de los mínimos cuadrados .
Ahora considere: 
Aquí, e_i es un error residual en i-ésima observación.
Por lo tanto, nuestro objetivo es minimizar el error residual total.
Definimos el error al cuadrado o función de costo, J como: ¡ 
y nuestra tarea es encontrar el valor de b_0 y b_1 para el cual J(b_0,b_1) es mínimo!
Sin entrar en detalles matemáticos, presentamos el resultado aquí: 

donde SS_xy es la suma de las desviaciones cruzadas de y y x: 
y SS_xx es la suma de las desviaciones al cuadrado de x: 
Nota: La derivación completa para encontrar estimaciones de mínimos cuadrados en regresión lineal simple se puede encontrar aquí .
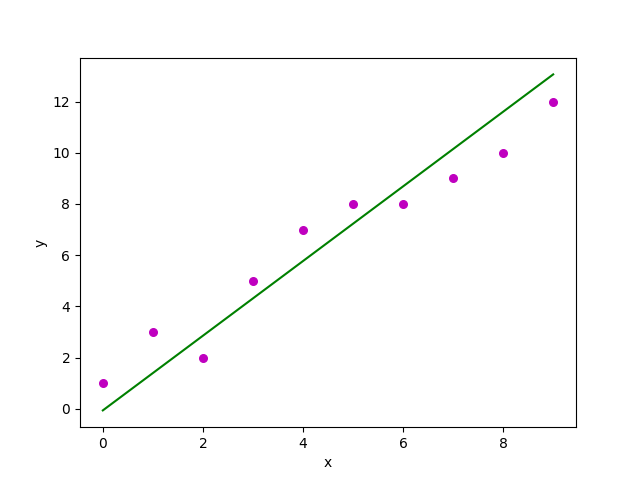
Código: implementación de Python de la técnica anterior en nuestro pequeño conjunto de datos
Producción:
Y el gráfico obtenido se ve así:
Regresión lineal múltiple
La regresión lineal múltiple intenta modelar la relación entre dos o más características y una respuesta ajustando una ecuación lineal a los datos observados.
Claramente, no es más que una extensión de la regresión lineal simple.
Considere un conjunto de datos con características p (o variables independientes) y una respuesta (o variable dependiente).
Además, el conjunto de datos contiene n filas/observaciones.
Definimos:
X ( array de características ) = una array de tamaño n X p donde x_{ij} denota los valores de j-ésima característica para la i-ésima observación.
Entonces, 
y
( vector de respuesta ) = un vector de tamaño ndonde y_{i} denota el valor de la respuesta para la i-ésima observación. 
La línea de regresión para características p se representa como: 
donde h(x_i) es el valor de respuesta pronosticado para i-ésima observación y b_0, b_1, …, b_p son los coeficientes de regresión .
Además, podemos escribir: 
donde e_i representa el error residual en la i-ésima observación.
Podemos generalizar nuestro modelo lineal un poco más representando la array de características X como: 
Así que ahora, el modelo lineal se puede expresar en términos de arrays como: 
donde, 
y 
Ahora, determinamos una estimación de b , es decir, b’ usando elMétodo de los mínimos cuadrados .
Como ya se explicó, el método de los mínimos cuadrados tiende a determinar b’ para el cual se minimiza el error residual total.
Presentamos el resultado directamente aquí: 
donde ‘ representa la transpuesta de la array mientras que -1 representa la array inversa.
Conociendo las estimaciones de mínimos cuadrados, b’, el modelo de regresión lineal múltiple ahora se puede estimar como: 
donde y’ es el vector de respuesta estimado .
Nota: La derivación completa para obtener estimaciones de mínimos cuadrados en regresión lineal múltiple se puede encontrar aquí .
Código: implementación de Python de múltiples técnicas de regresión lineal en el conjunto de datos de precios de viviendas de Boston utilizando Scikit-learn.
Producción:
y el diagrama de error residual se ve así:
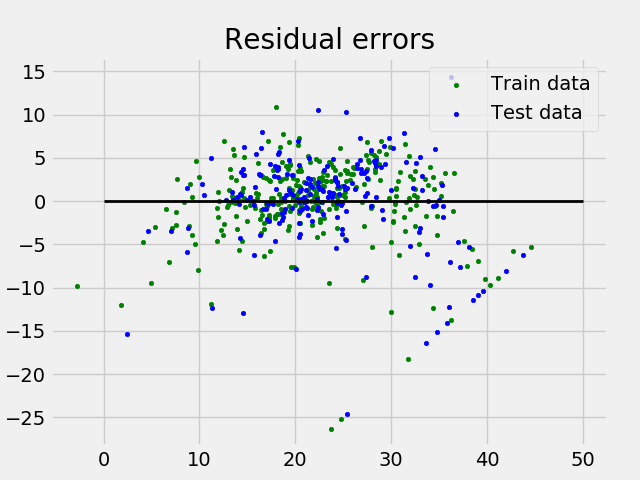
En el ejemplo anterior, determinamos la puntuación de precisión utilizando la puntuación de varianza explicada .
Definimos:
puntuación_de_varianza_explicada = 1 – Var{y – y’}/Var{y}
donde y’ es el resultado objetivo estimado, y el resultado objetivo correspondiente (correcto) y Var es la varianza, el cuadrado de la desviación estándar.
La mejor puntuación posible es 1,0, los valores más bajos son peores.
Suposiciones:
A continuación se presentan las suposiciones básicas que hace un modelo de regresión lineal con respecto a un conjunto de datos en el que se aplica:
- Relación lineal : la relación entre la respuesta y las variables de característica debe ser lineal. La suposición de linealidad se puede probar usando diagramas de dispersión. Como se muestra a continuación, la primera figura representa variables linealmente relacionadas, mientras que las variables en la segunda y tercera figura probablemente no sean lineales. Entonces, la primera figura dará mejores predicciones usando regresión lineal.

- Poca o ninguna multicolinealidad : se supone que hay poca o ninguna multicolinealidad en los datos. La multicolinealidad ocurre cuando las características (o variables independientes) no son independientes entre sí.
- Poca o ninguna autocorrelación : otra suposición es que hay poca o ninguna autocorrelación en los datos. La autocorrelación ocurre cuando los errores residuales no son independientes entre sí. Puede consultar aquí para obtener más información sobre este tema.
- Homocedasticidad : la homocedasticidad describe una situación en la que el término de error (es decir, el «ruido» o perturbación aleatoria en la relación entre las variables independientes y la variable dependiente) es el mismo en todos los valores de las variables independientes. Como se muestra a continuación, la figura 1 tiene homocedasticidad mientras que la figura 2 tiene heterocedasticidad.

Al llegar al final de este artículo, analizamos algunas aplicaciones de la regresión lineal a continuación.
Aplicaciones:
- Líneas de tendencia: una línea de tendencia representa la variación de los datos cuantitativos con el paso del tiempo (como el PIB, los precios del petróleo, etc.). Estas tendencias suelen seguir una relación lineal. Por lo tanto, la regresión lineal se puede aplicar para predecir valores futuros. Sin embargo, este método adolece de una falta de validez científica en los casos en que otros cambios potenciales pueden afectar los datos.
- Economía: La regresión lineal es la herramienta empírica predominante en economía. Por ejemplo, se utiliza para predecir el gasto del consumidor, el gasto de inversión fija, la inversión en inventarios, las compras de exportaciones de un país, el gasto en importaciones, la demanda para mantener activos líquidos, la demanda laboral y la oferta laboral.
- Finanzas: el modelo de activos de precio de capital utiliza la regresión lineal para analizar y cuantificar los riesgos sistemáticos de una inversión.
4. Biología: la regresión lineal se usa para modelar relaciones causales entre parámetros en sistemas biológicos.
Referencias:
El famoso algoritmo de Dijkstra se puede usar en una variedad de contextos, incluso como un medio para encontrar la ruta más corta entre dos enrutadores, también conocido como enrutamiento de estado de enlace . Este artículo explica una simulación del algoritmo de Dijkstra en la que los Nodes (enrutadores) son terminales.
Una vez que se calcula la ruta más corta entre dos Nodes (terminales), la ruta más corta en sí misma se envía como un mensaje a cada terminal en su ruta en secuencia, hasta que se alcanza la terminal de destino. Cada vez que el mensaje ha atravesado un Node, su terminal muestra el recorrido. De esta manera, es posible ver y simular el paso de un mensaje a través de una ruta calculada más corta.
El procedimiento para ejecutar el siguiente código es el siguiente:
- Ejecutar el código del controlador
- Antes de proporcionar cualquier entrada al código del controlador, ejecute los códigos del enrutador router1.py, router2.py, etc. en terminales/pestañas separadas.
- Ahora proporcione la entrada al código del controlador en forma de una array G, en la que cualquier entrada
G[i, j]es la distancia desde el Node i al Node j. La array debe ser simétrica. Si i=j, entoncesD[i, j]=0como la distancia entre un Node y sí mismo se considera que es nada. Si no hay conexión directa entre dos Nodes, entoncesD[i, j]=999(el equivalente de infinito).- Especifique los Nodes de origen y destino, donde los Nodes varían de 0 a 3 y representan los terminales 1 a 4 respectivamente.
Esta implementación especifica cuatro Nodes, pero esto se puede extender fácilmente a N Nodes con N terminales y números de puerto que representan los procesos que se ejecutan en ellos, respectivamente.
Considere el siguiente ejemplo de una red de cuatro Nodes, con las distancias entre ellos especificadas y los Nodes numerados del 0 al 3 de izquierda a derecha:

Distancias entre terminales
Para esta red, la array G con entradas G[i, j] como se especifica arriba sería:
Esta array tendría que introducirse en el código del controlador. El algoritmo de Dijkstra se utiliza para encontrar el camino más corto entre el origen y el destino. Se envía una lista que contiene la ruta restante a cada Node en ruta hacia el destino final.
La implementación en Python se especifica a continuación.
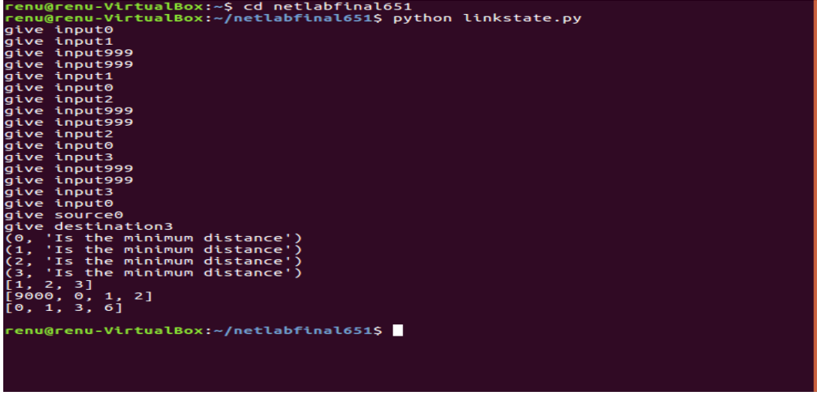
Salida Dijkstra
Salida terminal –
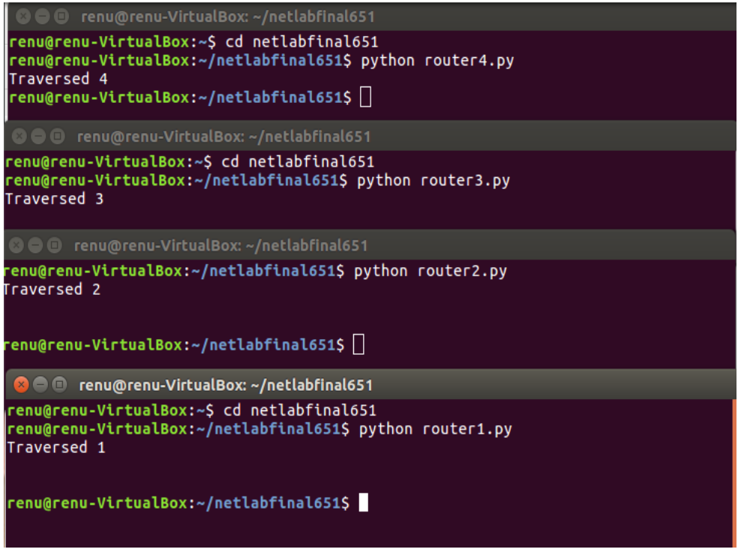
Salida terminal
¿Escribir código en un comentario? Utilice ide.geeksforgeeks.org , genere un enlace y compártalo aquí.
Aprenderás sobre el Reconocimiento automático de matrículas. Usaremos el motor de reconocimiento óptico de caracteres (OCR Engine) Tesseract OCR para reconocer automáticamente el texto en las placas de matrícula del vehículo.
Python-tesseract:
Py-tesseract es una herramienta de reconocimiento óptico de caracteres (OCR) para python. Es decir, reconocerá y “leerá” el texto incrustado en las imágenes. Python-tesseract es un contenedor para el motor Tesseract-OCR de Google. También se usa como secuencia de comandos individual, ya que puede leer todo tipo de imágenes como jpeg, png, gif, bmp, tiff, etc. Además, si se usa como secuencia de comandos, Python-tesseract imprimirá el texto reconocido en lugar de escribirlo en un archivo. Tiene la capacidad de reconocer más de 100 idiomas.
Instalación:
OpenCV:
OpenCV es una biblioteca de visión por computadora de código abierto. La biblioteca tiene más de 2500 algoritmos optimizados. Estos algoritmos se utilizan a menudo para buscar y reconocer rostros, identificar objetos, reconocer escenarios y generar marcadores para superponer imágenes mediante realidad aumentada, etc.
Instalación:
Nota: asegúrese de haber instalado correctamente los módulos pytesseract y OpenCV-python
Nota: debe tener el conjunto de datos listo y todas las imágenes deben ser como se muestra a continuación en las técnicas de procesamiento de imágenes para un mejor rendimiento; La carpeta del conjunto de datos debe estar en la misma carpeta en la que está escribiendo este código Python o tendrá que especificar la ruta al conjunto de datos manualmente donde sea necesario.
Nota: el nombre de los archivos de imagen debe ser el número exacto en la imagen de la matrícula respectiva. ejemplo: si tiene una matrícula con el número «FTY349U», nombre el archivo de imagen como «FTY349U.jpg».
Código: Realice OCR utilizando Tesseract Engine en matrículas
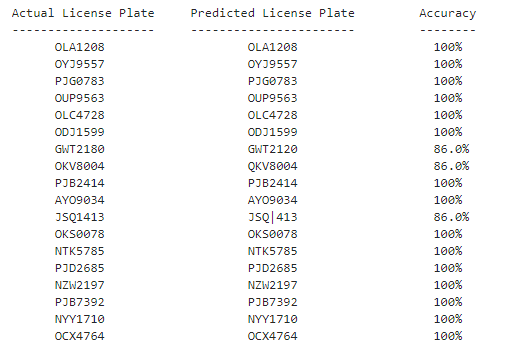
Ahora tenemos las placas pronosticadas pero no hemos visto cuál es la predicción, así que para ver los datos y la predicción hacemos un poco de visualización como se muestra a continuación. también estamos calculando la precisión de la predicción sin utilizar ninguna función integrada.
Producción:
Código: Técnicas de procesamiento de imágenes
Producción:
- Redimensionamiento de imagen:
Cambie el tamaño del archivo de imagen por un factor de 2x en las direcciones horizontal y vertical usando cv2.resize
resize_test_license_plate=cv2.resize(test_license_plate,None, fx=2, fy=2,interpolation=cv2.INTER_CUBIC) - Conversión a escala de grises: A continuación, convertimos nuestro archivo de imagen redimensionado a escala de grises para optimizar la detección y reducir drásticamente la cantidad de colores presentes en la imagen, lo que ayudará en la detección de matrículas fácilmente.
grayscale_resize_test_license_plate=cv2.cvtColor(resize_test_license_plate, cv2.COLOR_BGR2GRAY) - Eliminar el ruido de la imagen:
Gaussian Blur es una técnica para eliminar el ruido de las imágenes. hace que los bordes sean más claros y suaves, lo que a su vez hace que los caracteres sean más legibles.gaussian_blur_license_plate=cv2.GaussianBlur(grayscale_resize_test_license_plate, (5,5),0)Ahora, pase el archivo de matrícula transformado al motor Tesseract OCR y vea el resultado previsto.
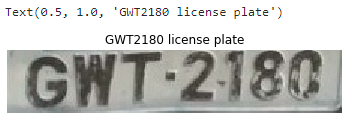
new_predicted_result_GWT2180=pytesseract.image_to_string(gaussian_blur_license_plate, lang='eng',config='--oem 3 -l eng --psm 6 -c tessedit_char_whitelist = ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789')filter_new_predicted_result_GWT2180="".join(new_predicted_result_GWT2180.split()).replace(":", "").replace("-", "")print(filter_new_predicted_result_GWT2180)Producción:
GWT2180
Del mismo modo, realice este procesamiento de imagen para todas las demás matrículas que no obtuvieron el 100 % de precisión. Finalmente, el modelo de detección de matrículas está listo.
Analizar datos del mundo real es algo difícil porque debemos tener en cuenta varias cosas. Además de obtener los datos útiles de grandes conjuntos de datos, también es muy importante mantener los datos en el formato requerido.
Uno podría encontrarse con una situación en la que necesitamos poner en minúsculas cada letra en cualquier columna específica en un marco de datos dado. Veamos cómo poner en minúsculas los nombres de las columnas en el marco de datos de Pandas.
Vamos a crear un marco de datos a partir del dictado de listas.
Producción: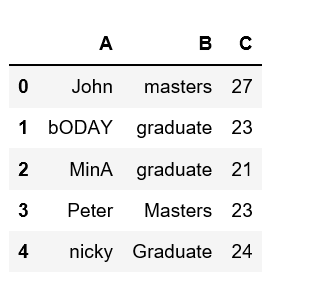
Hay ciertos métodos que podemos cambiar/modificar el caso de la columna en el marco de datos de pandas. Veamos cómo podemos poner en minúsculas los nombres de las columnas en el marco de datos de Pandas usando el lower()método.
Método 1:
Salida: 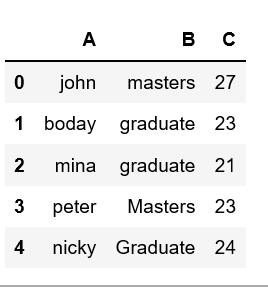
Método #2:
Producción:
Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
La función de Pandas dataframe.melt()desvía un DataFrame de formato ancho a formato largo, dejando opcionalmente las variables de identificador establecidas. Esta función es útil para enviar mensajes a un DataFrame en un formato donde una o más columnas son variables de identificador (id_vars), mientras que todas las demás columnas, consideradas variables medidas (value_vars), están «sin pivotar» en el eje de fila, dejando solo dos no identificadores. columnas, ‘variable’ y ‘valor’.
Sintaxis: DataFrame.melt(id_vars=Ninguno, value_vars=Ninguno, var_name=Ninguno, value_name=’value’, col_level=Ninguno)
Parámetros:
marco: DataFrame
id_vars: Columna(s) para usar como identificador de variables
value_vars: Columna(s) des-pivotar. Si no se especifica, usa todas las columnas que no están configuradas como id_vars.
var_name : Nombre a usar para la columna ‘variable’. Si es Ninguno, usa marco.columnas.nombre o ‘variable’.
value_name: nombre que se usará para la columna ‘valor’
col_level: si las columnas son un índice múltiple, use este nivel para derretir.Devuelve: DataFrame en un formato donde una o más columnas son variables de identificación
Ejemplo #1: Utilice melt()la función para establecer la columna «A» como variable de identificación y la columna «B» como variable de valor.
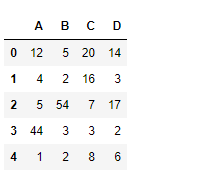
Usemos la dataframe.melt()función para establecer la columna «A» como variable de identificación y la columna «B» como variable de valor.
Salida: 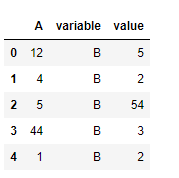
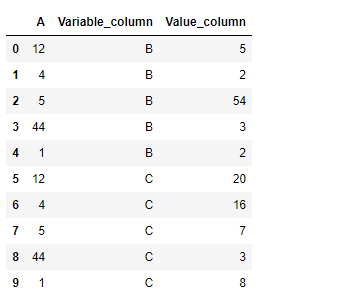
Ejemplo n.º 2: use melt()la función para establecer la columna «A» como variable de identificación y las columnas «B» y «C» como variable de valor. También personalice los nombres de la columna de valor y variable.
Usemos la dataframe.melt()función para establecer la columna «A» como variable de identificación y las columnas «B» y «C» como la variable de valor.
Producción :
Se proporciona una lista anidada. La tarea es imprimir la suma de esta lista usando recursividad. Una lista anidada es una lista cuyos elementos también pueden ser una lista.
Ejemplos:
Recursión: En recursión, una función se llama a sí misma repetidamente. Esta técnica se usa generalmente cuando un problema se puede dividir en subproblemas más pequeños de la misma forma.
Implementación:
Iterar a través de la lista y cada vez que encontremos que un elemento de la lista también es una lista, eso significa que tenemos que hacer la misma tarea de encontrar la suma con esta lista de elementos (que también se puede anidar). Así que hemos encontrado un subproblema y podemos llamar a la misma función para realizar esta tarea y simplemente cambiar el argumento a esta sublista. Y cuando el elemento no es una lista, simplemente agregue su valor a la variable total global.
28
Complejidad temporal: O(N), donde N es el número total de elementos de la lista.
Espacio Auxiliar: O(1)
KNN es un algoritmo de aprendizaje automático que se usa tanto para problemas de clasificación (usando KNearestClassifier) como de regresión (usando KNearestRegressor). En el algoritmo KNN, K es el hiperparámetro . Elegir el valor correcto de K importa. Se dice que un modelo de aprendizaje automático tiene una complejidad de modelo alta si el modelo construido tiene un sesgo bajo y una varianza alta.
Lo sabemos,
- Alto sesgo y baja varianza = modelo de ajuste insuficiente.
- Sesgo bajo y varianza alta = modelo sobreajustado. [ Modelo de alta complejidad indicado ].
- Low Bias y Low Variance = Modelo de mejor ajuste. [Esto es preferible].
- Alta precisión de entrenamiento y Baja precisión de la prueba (precisión fuera de la muestra) = Varianza alta = Modelo sobreajustado = Más complejidad del modelo.
- Precisión de entrenamiento baja y precisión de prueba baja (precisión fuera de la muestra) = sesgo alto = modelo de ajuste insuficiente.
Código: Para comprender cómo el valor K en el algoritmo KNN afecta la complejidad del modelo.
Producción:
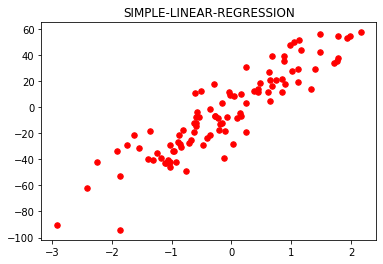
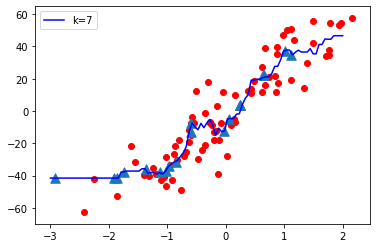
Ahora vamos a variar el valor de K (Hiperparámetro) de Bajo a Alto y observemos la complejidad del modelo
K = 1
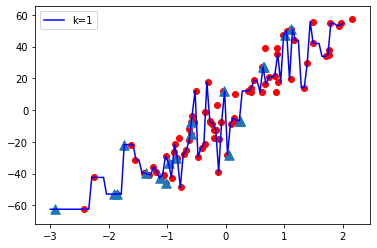
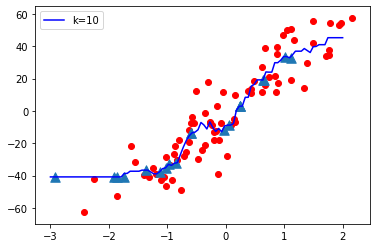
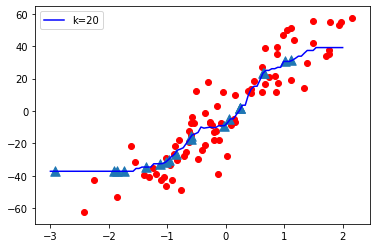
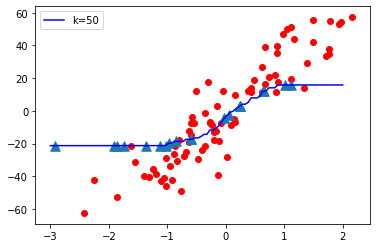
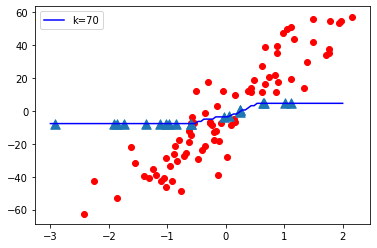
Observaciones:
- Cuando el valor de K es pequeño, es decir, K=1, la complejidad del modelo es alta (sobreajuste o alta varianza).
- Cuando el valor de K es muy grande, es decir, K = 70, la complejidad del modelo disminuye (ajuste insuficiente o alto sesgo).
Conclusión:
A medida que el valor K se vuelve pequeño, la complejidad del modelo aumenta y, a medida que el valor K se vuelve grande, la complejidad del modelo disminuye.
Código: Consideremos la siguiente trama
Producción:
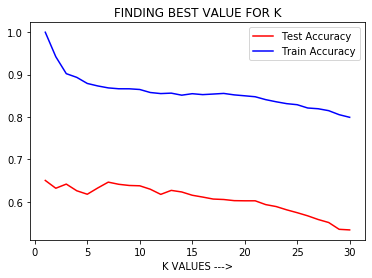
Observación:
del gráfico anterior, podemos concluir que cuando K es pequeño, es decir, K=1, la precisión del entrenamiento es alta pero la precisión de la prueba es baja, lo que significa que el modelo se ajusta en exceso (varianza alta o complejidad del modelo alta ). Cuando el valor de K es grande, es decir, K = 50, la precisión del entrenamiento es baja y la precisión de la prueba es baja, lo que significa que el modelo no se ajusta bien (sesgo alto o complejidad del modelo baja).
Por lo tanto , es necesario ajustar los hiperparámetros , es decir, para seleccionar el mejor valor de K en el algoritmo KNN para el cual el modelo tiene un sesgo bajo y una varianza baja y da como resultado un buen modelo con una precisión alta fuera de la muestra.
Podemos usar GridSearchCV o RandomSearchCv para encontrar el mejor valor del hiperparámetro K.
En este artículo, vamos a discutir cómo diseñar un filtro Butterworth digital de paso alto usando Python. El filtro Butterworth es un tipo de filtro de procesamiento de señal diseñado para tener una respuesta de frecuencia lo más plana posible en la banda de paso. Tomemos las siguientes especificaciones para diseñar el filtro y observar la respuesta de magnitud, fase e impulso del filtro digital Butterworth.
¿Qué es un filtro de paso alto?
Un filtro de paso alto es un filtro electrónico que deja pasar señales con una frecuencia superior a una determinada frecuencia de corte y atenúa las señales con frecuencias inferiores a la frecuencia de corte. La atenuación para cada frecuencia depende del diseño del filtro.
Diferencia entre un filtro de paso alto digital y un filtro de paso bajo digital:
La diferencia más llamativa está en la respuesta de amplitud de los filtros, podemos observar claramente que en el caso del filtro de paso alto, el filtro pasa señales con una frecuencia superior a una determinada frecuencia de corte y atenúa las señales con frecuencias inferiores a la frecuencia de corte, mientras que en el caso del filtro de paso bajo, el filtro deja pasar señales con una frecuencia inferior a una determinada frecuencia de corte y atenúa todas las señales con frecuencias superiores al valor de corte especificado.
Las especificaciones son las siguientes:
- Tasa de muestreo de 3,5 kHz
- Frecuencia de borde de banda de paso de 1050 Hz
- Frecuencia de borde de banda de parada de 600Hz
- Ondulación de banda de paso de 1 dB
- Atenuación mínima de la banda de parada de 50 dB
Graficaremos la respuesta de magnitud, fase e impulso del filtro.
Enfoque paso a paso:
Paso 1: Importación de todas las bibliotecas necesarias.
Paso 2: Definir variables con las especificaciones dadas del filtro.
Paso 3: construir el filtro usando el método signal.buttord() .
Producción:

Paso 4: Trazado de la Respuesta de Magnitud.
Producción:
Paso 5: Representación gráfica de la respuesta al impulso.
Producción:
Paso 6: Trazado de la respuesta de fase.
Producción:
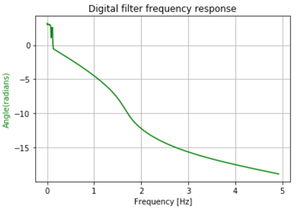
A continuación se muestra el programa completo basado en el enfoque anterior:
Producción:
Dada una Lista, realice un reordenamiento para obtener elementos similares en secuencia.
Entrada : test_list = [4, 7, 5, 4, 1, 4, 1, 6, 7, 5]
Salida : [4, 4, 4, 7, 7, 5, 5, 1, 1, 6]
Explicación : Todos los elementos similares se asignan para ser consecutivos.Entrada : test_list = [4, 7, 5, 1, 4, 1, 6, 7, 5]
Salida : [4, 4, 7, 7, 5, 5, 1, 1, 6]
Explicación : Todos los elementos similares son asignado para ser consecutivo.
Método #1: Usando Counter() + loop + items()
En esto, realizamos la tarea de calcular la frecuencia usando Counter(), y loop y items() se usan para reordenar elementos de acuerdo con el conteo y las frecuencias de acceso, respectivamente.
Producción:
Método #2: Usando Counter() + elements()
En este, realizamos la tarea de reordenar las frecuencias contadas usando elements(), brindando una solución concisa.
Producción:
La multiplicación de arrays es una parte integral de la computación científica. Se vuelve complicado cuando el tamaño de la array es enorme. Una de las formas de calcular fácilmente el producto de dos arrays es utilizar los métodos proporcionados por PyTorch. Este artículo cubre cómo realizar la multiplicación de arrays usando PyTorch.
PyTorch y tensores:
Es un paquete que se puede utilizar para proyectos de aprendizaje profundo basados en redes neuronales. Es una biblioteca de código abierto desarrollada por el equipo de investigación de IA de Facebook. Puede reemplazar a NumPy con su poder de GPU. Una de las clases importantes proporcionadas por esta biblioteca es Tensor . No es más que las arrays n-dimensionales proporcionadas por el paquete NumPy. Hay tantos métodos en PyTorch que se pueden aplicar a Tensor, lo que hace que los cálculos sean más rápidos y fáciles. El tensor solo puede contener elementos del mismo tipo de datos.
Multiplicación de arrays con PyTorch:
Los métodos en PyTorch esperan que las entradas sean un Tensor y los que están disponibles con PyTorch y Tensor para la multiplicación de arrays son:
- antorcha.mm().
- antorcha.matmul().
- antorcha.bmm()
- operador @.
antorcha.mm():
Este método calcula la multiplicación de arrays tomando un Tensor m×n y un Tensor n×p . Puede tratar solo con arrays bidimensionales y no con arrays unidimensionales. Esta función no es compatible con la transmisión. La transmisión no es más que la forma en que se tratan los Tensores cuando sus formas son diferentes. El Tensor más pequeño se transmite para adaptarse a la forma del Tensor más ancho o más grande para las operaciones. La sintaxis de la función se da a continuación.
antorcha.mm(Tensor_1, Tensor_2, salida=Ninguno)
Los parámetros son dos tensores y el tercero es un argumento opcional. Allí se puede dar otro tensor para contener los valores de salida.
Ejemplo-1: Arrays de la misma dimensión
Aquí ambas entradas son de las mismas dimensiones. Así, la salida también será de la misma dimensión.
Producción:
Ejemplo 2: Arrays de diferente dimensión
Aquí tensor_1 tiene una dimensión de 2×2, tensor_2 tiene una dimensión de 2×3. Entonces la salida será de 2×3.
Producción:
antorcha.matmul():
Este método permite el cálculo de la multiplicación de dos arrays vectoriales (arrays unidimensionales), arrays 2D y también mixtas. Este método también es compatible con las operaciones por lotes y de difusión. En función de las dimensiones de las arrays de entrada se decide la operación a realizar. La sintaxis general se da a continuación.
antorcha.matmul(Tensor_1, Tensor_2, fuera=Ninguno)
La siguiente tabla enumera las diversas dimensiones posibles de los argumentos y las operaciones basadas en ellos.
|
argumento_1 |
argumento_2 |
Acción tomada |
| unidimensional | unidimensional | El producto escalar se calcula |
| bidimensional | bidimensional | Se realiza la multiplicación general de arrays. |
| unidimensional | bidimensional | El tensor-1 se pretende con un ‘1’ para que coincida con la dimensión del tensor-2 |
| bidimensional | unidimensional | Se calcula el producto array-vector |
| 1/N-dimensional (N>2) | 1/N-dimensional (N>2) | Se realiza la multiplicación de arrays por lotes. |
Ejemplo 1: Argumentos de la misma dimensión
Producción:
Ejemplo 2: Argumentos de diferentes dimensiones
Producción:
Ejemplo 3: argumento N-dimensional (N>2)
Producción:
antorcha.bmm():
Este método proporciona la multiplicación de arrays por lotes para los casos en los que ambas arrays a multiplicar tienen solo 3 dimensiones (x×y×z) y la primera dimensión (x) de ambas arrays debe ser la misma. Esto no es compatible con la transmisión. La sintaxis es como se indica a continuación.
torch.bmm( Tensor_1, Tensor_2, determinista=falso, fuera=Ninguno)
El parámetro «determinista» toma valor booleano. Un ‘ falso ‘ hace un cálculo más rápido que no es determinista. Un ‘ verdadero ‘ hace un cálculo más lento, sin embargo, es determinista.
Ejemplo:
En el siguiente ejemplo, la array_1 tiene una dimensión de 2×3×3. La segunda array es de dimensión 2×3×4.
Producción:
** Nota: las arrays varían para cada corrida ya que los valores aleatorios se llenan dinámicamente.
@ operador:
El operador @ – Simon H, cuando se aplica a arrays, realiza la multiplicación por elementos en arrays 1D y la multiplicación normal de arrays en arrays 2D. Si ambas arrays tienen la misma dimensión, entonces la multiplicación de arrays se lleva a cabo normalmente sin ninguna difusión/anteposición. Si alguna de las arrays tiene una dimensión diferente, primero se realiza la transmisión adecuada y luego se realiza la multiplicación. Este operador también se aplica a las arrays N-dimensionales.
Ejemplo:
Producción:
Divida una línea larga en varias líneas en Python , solo está tratando de arreglar cómo aparece nuestro código. Escribir una línea realmente larga en una sola línea hace que el código parezca menos limpio y hay posibilidades de que uno pueda confundirlo con algo complejo. Dividir la misma línea puede aumentar la legibilidad del código, descartar cualquier confusión y, obviamente, lo hace presentable. Por lo general, una línea se divide después de cruzar una cierta cantidad de caracteres.
Ejemplo:
Método 1: dividir una línea larga en varias líneas usando una barra invertida
Se puede colocar una barra invertida (\) entre la línea para que aparezca separada, como se muestra a continuación. Además, tenga en cuenta que los tres casos producen exactamente el mismo resultado, la única diferencia es la forma en que se presentan en el código:
Ejemplo:
Producción:
ANTES DE ROMPER:
¿Cuántas veces se sintió frustrado al buscar una buena colección de preguntas de programación/algoritmo/entrevista?
DESPUÉS DE ROMPER:
¿Cuántas veces se sintió frustrado al buscar una buena colección de preguntas de programación/algoritmo/entrevista?
DESPUÉS DE ROMPER USANDO UNA VARIABLE:
¿Cuántas veces se sintió frustrado al buscar una buena colección de preguntas de programación/algoritmo/entrevista? ¿Qué esperabas y qué obtuviste? Geeks for geeks es un portal que ha sido creado para brindar información bien escrita.
Método 2: dividir una línea larga en varias líneas utilizando el operador de concatenación de strings
El operador de concatenación de strings (+), algo tan básico, puede reemplazar fácilmente las barras invertidas en el ejemplo anterior para dar el mismo resultado.
Ejemplo:
Producción:
¿Cuántas veces se sintió frustrado al buscar una buena colección de preguntas de programación/algoritmo/entrevista? ¿Qué esperabas y qué obtuviste? Geeks for geeks es un portal que ha sido creado para proporcionar soluciones bien escritas, bien pensadas y bien explicadas para preguntas seleccionadas.
Método 3: dividir una línea larga en varias líneas usando paréntesis
Se puede lograr el mismo resultado manteniendo cada fragmento entre paréntesis y separando cada fragmento del otro usando una coma (,).
Producción:
¿Cuántas veces se sintió frustrado al buscar una buena colección de preguntas de programación/algoritmo/entrevista? ¿Qué esperabas y qué obtuviste? Geeks for geeks es un portal que ha sido creado para proporcionar soluciones bien escritas, bien pensadas y bien explicadas para preguntas seleccionadas.
Comparando tres comillas dobles y tres comillas simples
En este ejemplo, intentaremos comparar las 2 strings multilínea en Python , para verificar si ambas son iguales o no. Como en el resultado, podemos ver que obtenemos Falso porque x detecta un carácter de nueva línea (\n) en la línea x, mientras que en y no hay ningún carácter de nueva línea.
Producción:
Los algoritmos Naive Bayes son un grupo de algoritmos de aprendizaje automático muy populares y comúnmente utilizados para la clasificación. Hay muchas formas diferentes de implementar el algoritmo Naive Bayes, como Gaussian Naive Bayes, Multinomial Naive Bayes, etc. Para obtener más información sobre los conceptos básicos de Naive Bayes, puede seguir este enlace.
Complement Naive Bayes es algo así como una adaptación del algoritmo Multinomial Naive Bayes estándar. Multinomial Naive Bayes no funciona muy bien en conjuntos de datos desequilibrados. Los conjuntos de datos desequilibrados son conjuntos de datos en los que la cantidad de ejemplos de alguna clase es mayor que la cantidad de ejemplos que pertenecen a otras clases. Esto significa que la distribución de ejemplos no es uniforme. Puede ser difícil trabajar con este tipo de conjunto de datos, ya que un modelo puede sobreajustar fácilmente estos datos a favor de la clase con más ejemplos.
Cómo funciona CNB:
Complement Naive Bayes es especialmente adecuado para trabajar con conjuntos de datos desequilibrados. En el complemento Naive Bayes, en lugar de calcular la probabilidad de que un elemento pertenezca a una determinada clase, calculamos la probabilidad de que el elemento pertenezca a todas las clases. Este es el significado literal de la palabra, complemento y por lo tanto se llama Complemento Naive Bayes.
Una descripción general paso a paso de alto nivel del algoritmo (sin ninguna matemática involucrada):
- Para cada clase, calcule la probabilidad de que la instancia dada no pertenezca a ella.
- Después del cálculo de todas las clases, verificamos todos los valores calculados y seleccionamos el valor más pequeño.
- Se selecciona el valor más pequeño (probabilidad más baja) porque es la probabilidad más baja de que NO sea esa clase en particular. Esto implica que tiene la mayor probabilidad de pertenecer realmente a esa clase. Entonces esta clase es seleccionada.
Nota: No seleccionamos el de mayor valor porque estamos calculando el complemento de la probabilidad. El que tiene el valor más alto es menos probable que sea la clase a la que pertenece ese elemento.
Ahora, consideremos un ejemplo: digamos, tenemos dos clases: Apples y Bananas y tenemos que clasificar si una oración dada está relacionada con apples o bananas, dada la frecuencia de un cierto número de palabras. Aquí hay una representación tabular del conjunto de datos simple:
| Número de oración | Redondo | Rojo | Largo | Amarillo | Suave | Clase |
| 1 | 2 | 1 | 1 | 0 | 0 | manzanas |
| 2 | 1 | 1 | 0 | 9 | 5 | plátanos |
| 3 | 2 | 1 | 0 | 0 | 1 | manzanas |
Recuento total de palabras en la clase ‘Manzanas’ = (2+1+1) + (2+1+1) = 8
Recuento total de palabras en la clase ‘Bananas’ = (1 + 1 + 9 + 5) = 16
Entonces, la probabilidad de que una oración pertenezca a la clase ‘manzanas’, 
De manera similar, la probabilidad de que una oración pertenezca a la clase ‘Plátanos’,
En la tabla anterior, hemos representado un conjunto de datos donde las columnas indican la frecuencia de las palabras en una oración determinada y luego muestran a qué clase pertenece la oración. Antes de comenzar, primero debe conocer el Teorema de Bayes . El Teorema de Bayes se usa para encontrar la probabilidad de un evento, dado que ocurre otro evento. La fórmula es:
donde A y B son eventos, P(A) es la probabilidad de ocurrencia de A, y P(A|B) es la probabilidad de que ocurra A dado que el evento B ya ocurrió. P(B), la probabilidad de que ocurra el evento B no puede ser 0 porque ya ocurrió. Si desea obtener más información sobre Naive Bayes y el Teorema de Bayes, puede seguir este enlace.
Ahora veamos cómo funcionan Naive Bayes y Complement Naive Bayes. El algoritmo regular de Naive Bayes es,
donde f i es la frecuencia de algún atributo. Por ejemplo, el número de veces que aparecen ciertas palabras en una oración.
Sin embargo, en complemento bayesiano ingenuo, la fórmula es:
Si echa un vistazo más de cerca a las fórmulas, verá que el Naive Bayes complementario es justo lo contrario del Naive Bayes regular. En Naive Bayes, la clase con el mayor valor obtenido de la fórmula es la clase predicha. Entonces, dado que el Complemento Naive Bayes es justo lo contrario, la clase con el valor más pequeño obtenido de la fórmula CNB es la clase predicha.
Ahora, tomemos un ejemplo e intentemos predecirlo usando nuestro conjunto de datos y CNB,
| Redondo | Rojo | Largo | Amarillo | Suave | Clase |
| 1 | 1 | 0 | 0 | 1 | ? |
Entonces, necesitamos encontrar 
y
Necesitamos comparar ambos valores y seleccionar la clase como la clase predicha como la que tiene el valor más pequeño. Tenemos que hacer esto también para los plátanos y elegir el que tenga el valor más pequeño. es decir, si el valor de (y = Manzanas) es menor, la clase se predice como Manzanas, y si el valor de (y = Plátanos) es menor, la clase se predice como Plátanos.
Usando la fórmula Bayesiana ingenua del complemento para ambas clases,

Ahora, dado que 6.302 < 85.333, la clase pronosticada es Manzanas .
NO usamos la clase con un valor más alto porque un valor más alto significa que es más probable que una oración con esas palabras NO pertenezca a la clase. Esta es exactamente la razón por la que este algoritmo se llama Complement Naive Bayes.
¿Cuándo usar CNB?
- Cuando el conjunto de datos está desequilibrado: si el conjunto de datos en el que se va a realizar la clasificación está desequilibrado, Multinomial y Gaussian Naive Bayes pueden dar una precisión baja. Sin embargo, Complement Naive Bayes funcionará bastante bien y proporcionará una precisión relativamente mayor.
- Para tareas de clasificación de texto: Complement Naive Bayes supera tanto a Gaussian Naive Bayes como a Multinomial Naive Bayes en tareas de clasificación de texto.
Implementación de CNB en Python:
para este ejemplo, usaremos el conjunto de datos de vino que está ligeramente desequilibrado. Determina el origen del vino a partir de diversos parámetros químicos. Para saber más sobre este conjunto de datos, puede consultar este enlace.
Para evaluar nuestro modelo, verificaremos la precisión del conjunto de prueba y el informe de clasificación del clasificador. Usaremos la biblioteca scikit-learn para implementar el algoritmo Complement Naive Bayes.
Código:
PRODUCCIÓN
Obtenemos una precisión del 65,56 % en el conjunto de entrenamiento y una precisión del 66,66 % en el conjunto de prueba. Son más o menos lo mismo y en realidad son bastante buenos dada la calidad del conjunto de datos. Este conjunto de datos es conocido por ser difícil de clasificar con clasificadores simples como el que hemos usado aquí. Así que la precisión es aceptable.
Conclusión:
ahora que sabe qué son los clasificadores de Complement Naive Bayes y cómo funcionan, la próxima vez que se encuentre con un conjunto de datos desequilibrado, puede intentar usar Complement Naive Bayes.
Referencias:
choice() es una función incorporada en el lenguaje de programación Python que devuelve un elemento aleatorio de una lista, tupla o string.
Sintaxis:
Nota: Tenemos que importar aleatoriamente para usar el método choice().
A continuación se muestra la implementación de Python3 del enfoque anterior:
La salida cada vez será diferente ya que el sistema devuelve un elemento aleatorio.
Producción:
Aplicación práctica:
Imprime cualquier número aleatorio 5 veces de una lista dada.
La salida cambia cada vez que se usa la función choice().
Producción:
Con la ayuda del zlib.decompress(s)método, podemos descomprimir los bytes comprimidos de la string en la string original usando el zlib.decompress(s)método.
Sintaxis:
zlib.decompress(string)
Retorno: Devuelve una string descomprimida.
Ejemplo n.º 1:
en este ejemplo, podemos ver que al usar el zlib.decompress(s)método, podemos descomprimir la string comprimida en el formato de bytes de la string al usar este método.
Producción :
String comprimida
b’x\x9c\x0b\xc9\xc8,V\x00″w7w\x85\xc4\xd2\x92\x8c\xfc”\x1d\x85\xc4\xbc\x14\x85\xb4\xcc\xbc \xc4\x1c\x85\xca\xd4\xc4″\x85\xe2\x92\xd2\x94\xd4\xbc\x12=\x00A\xc9\x0f\x0b’String descomprimida
b’Este es el autor de GFG y estudiante de último año.’
Ejemplo #2:
Producción :
String comprimida
b’x\x9csOM\xcd.v\xcb/r\x07\xd1\x0e\x86F\xc6&\xa6f\xe6\x16\x00X\xf6\x06\xea’String descomprimida
b’GeeksForGeeks@12345678′
Dada una oración que contiene n palabras/strings. Elimine todas las palabras/strings duplicadas que sean similares entre sí.
Ejemplos:
Altair es una biblioteca de visualización estadística en Python. Es de naturaleza declarativa y se basa en las gramáticas de visualización Vega y Vega-Lite. Se está convirtiendo rápidamente en la primera opción de las personas que buscan una forma rápida y eficiente de visualizar conjuntos de datos. Si ha utilizado bibliotecas de visualización imperativas como matplotlib, podrá apreciar correctamente las capacidades de Altair.
Se considera correctamente como una biblioteca de visualización declarativa ya que, al visualizar cualquier conjunto de datos en Altair, el usuario solo necesita especificar cómo se asignan las columnas de datos al canal de codificación, es decir, declarar enlaces entre las columnas de datos y los canales de codificación, como los ejes x e y, filas, columnas, etc. Simplemente encuadre, una biblioteca de visualización declarativa le permite concentrarse en el «qué» en lugar del «cómo», al manejar los otros detalles de la trama sin la ayuda de los usuarios.
Por el contrario, las bibliotecas imperativas como matplotlib lo obligan a especificar la parte del «cómo» de la visualización que quita el enfoque de los datos y la relación entre ellos. Esto también hace que el código sea largo y consuma mucho tiempo, ya que debe especificar detalles como las leyendas y los nombres de los ejes.
Instalación
El siguiente comando se puede usar para instalar Altair como cualquier otra biblioteca de Python:
Vamos a utilizar conjuntos de datos del paquete vega_datasets . Para instalar, se debe emplear el siguiente comando:
Nota: se debe usar Jupyter Notebook para ejecutar el código, ya que las visualizaciones requieren una interfaz de Javascript para mostrar los gráficos. Puede consultar el siguiente artículo para saber cómo usar Jupyter Notebook: Primeros pasos con Jupyter Notebook . También puede usar JupyterLab, Zeppelin o cualquier otro entorno de notebook o IDE compatible con notebook.
Elementos esenciales de un gráfico de Altair
Todos los gráficos de altair necesitan tres elementos esenciales: Datos, Marca y Codificación. También se puede hacer un gráfico válido especificando solo los datos y la marca.
El formato básico de todos los gráficos de altair es:
alt.Chart(datos).mark_bar().encode(
codificación1 = ‘columna1’,
codificación2 = ‘columna2’,
)
- Hacer un gráfico.
- Pasa algunos datos.
- Especifique el tipo de marca que desea.
- Especifique la codificación.
Ahora, veamos los elementos esenciales en detalle.
Datos
El conjunto de datos es el primer argumento que pasa al gráfico. Los datos en Altair se basan en Pandas Dataframe, por lo que la codificación se vuelve bastante simple y puede detectar los tipos de datos necesarios en la codificación, pero también puede usar lo siguiente para los datos:
- Un objeto de datos o relacionado como UrlData, InlineData, NamedData
- Un archivo de texto o URL con formato json o csv
- Un objeto que admita __geo_interface__ (por ejemplo, Geopandas GeoDataFrame, GeoJSON Objects)
El uso de DataFrames facilitará el proceso, por lo que debe usar DataFrames siempre que sea posible.
Marca
La propiedad Mark especifica cómo se deben representar los datos en el gráfico. Hay muchos tipos de métodos de marca disponibles en Altair que tienen el siguiente formato:
Algunas marcas básicas incluyen área, barra, punto, texto, marca y línea. Altair también proporciona algunas marcas compuestas como diagrama de caja, banda de error y barra de error. Estos métodos de marca también pueden aceptar argumentos opcionales como el color y la opacidad.
Una de las principales ventajas de usar Altair es que el tipo de gráfico se puede cambiar simplemente cambiando el tipo de marca.
Codificación
Una de las cosas más importantes en la visualización es la asignación de datos a las propiedades visuales del gráfico. Este mapeo en Altair se denomina codificación y se realiza a través del método Chart.encode(). Hay varios tipos de canales de codificación disponibles en Altair: canales de posición, canales de propiedad de marca, canales de hipervínculo, etc. De estos, los más utilizados son los canales x (valor del eje x) e y (valor del eje y) de los canales de posición. y color y opacidad de los canales de propiedad de marca.
Ventajas
- El código básico sigue siendo el mismo para todos los tipos de gráficos, el usuario solo necesita cambiar el atributo de marca para obtener gráficos diferentes.
- El código es más corto y sencillo de escribir que otras bibliotecas de visualización imperativas. El usuario puede concentrarse en la relación entre las columnas de datos y olvidarse de los detalles innecesarios de la trama.
- El facetado y la interactividad son muy fáciles de implementar.
Ejemplos
Programa 1: (Gráfico de barras simple)
Producción:
Gráfico de barras simple usando Altair
Programa 2: (Gráfico de dispersión)
En este ejemplo, visualizaremos el conjunto de datos del iris de la biblioteca vega_datasets en forma de diagrama de dispersión. El método de marca utilizado para el gráfico de dispersión en este ejemplo es mark_point(). Para este análisis de dos variables, asignamos las columnas sepalLength y petalLength a la codificación de los ejes x e y. Además, para diferenciar los puntos entre sí, asignamos la codificación de formas a la columna de especies.
Producción:
Diagrama de dispersión usando Altair
Este método se utiliza para crear una array a partir de una secuencia en el tipo de datos deseado.
Sintaxis: pandas.array(data: Sequence[object], dtype: Union[str, numpy.dtype, pandas.core.dtypes.base.ExtensionDtype, NoneType] = None, copy: bool = True)
Parámetros:
- data : Secuencia de objetos. Los escalares dentro de `data` deberían ser instancias del tipo escalar para `dtype`. Se espera que `data` represente una array unidimensional de datos. Cuando `data` es un índice o una serie, la array subyacente se extraerá de `data`.
- dtype: tr, np.dtype o ExtensionDtype, opcional. El dtype a usar para la array. Este puede ser un dtype NumPy o un tipo de extensión registrado con pandas.
- copia: bool, por defecto True. Si copiar los datos, incluso si no es necesario. Dependiendo del tipo de `datos`, la creación de la nueva array puede requerir la copia de datos, incluso si «copiar = Falso».
A continuación se muestra la implementación del método anterior con algunos ejemplos:
Ejemplo 1 :
Producción :
Ejemplo 2:
Producción :
Pandas es una biblioteca de código abierto que se basa en la biblioteca NumPy. Permite al usuario un análisis rápido, limpieza de datos y preparación de datos de manera eficiente. Pandas es rápido y tiene un alto rendimiento y productividad para los usuarios.
La mayoría de los conjuntos de datos con los que trabaja se denominan DataFrames. DataFrames es una estructura de datos etiquetada bidimensional con índice para filas y columnas, donde cada celda se usa para almacenar un valor de cualquier tipo. Básicamente, los marcos de datos se basan en un diccionario a partir de NumPy Arrays.
En Django REST Framework, el concepto mismo de Serialización es convertir datos de base de datos a un tipo de datos que pueda ser utilizado por javascript. Cada serializador viene con algunos campos (entradas) que se van a procesar. Por ejemplo, si tiene una clase con el nombre Empleado y sus campos como Employee_id, Employee_name, is_admin, etc. Entonces, necesitará AutoField, CharField y BooleanField para almacenar y manipular datos a través de Django. De manera similar, el serializador también funciona con el mismo principio y tiene campos que se usan para crear un serializador.
Este artículo gira en torno a los campos numéricos en serializadores en Django REST Framework. Hay tres campos principales: IntegerField, FloatField y DecimalField.
CampoEntero
IntegerField es básicamente un campo entero que valida la entrada contra la instancia int de Python. Es lo mismo que IntegerField – Django Models
Tiene los siguientes argumentos –
- max_value Valida que el número proporcionado no sea mayor que este valor.
- min_value Valida que el número proporcionado no sea inferior a este valor.
Sintaxis –
campo flotante
FloatField es básicamente un campo flotante que valida la entrada contra la instancia flotante de Python. Es lo mismo que FloatField – Django Models
Tiene los siguientes argumentos –
- max_value Valida que el número proporcionado no sea mayor que este valor.
- min_value Valida que el número proporcionado no sea inferior a este valor.
Sintaxis –
campo decimal
DecimalField es básicamente un campo decimal que valida la entrada contra la instancia decimal de Python. Es lo mismo que DecimalField – Django Models
Tiene los siguientes argumentos –
- max_digits El número máximo de dígitos permitidos en el número. Debe ser Ninguno o un número entero mayor o igual que decimal_places.
- decimal_places El número de lugares decimales para almacenar con el número.
- max_value Valida que el número proporcionado no sea mayor que este valor.
- min_value Valida que el número proporcionado no sea inferior a este valor.
- localizar Establézcalo en Verdadero para habilitar la localización de entrada y salida en función de la configuración regional actual.
Sintaxis –
¿Cómo usar campos numéricos en serializadores?
Para explicar el uso de los campos numéricos, usemos la misma configuración de proyecto de: ¿Cómo crear una API básica usando Django Rest Framework? .
Ahora que tiene un archivo llamado serializadores en su proyecto, creemos un serializador con IntegerField, FloatField y DecimalField como campos.
Ahora vamos a crear algunos objetos e intentar serializarlos y verificar si realmente funcionan, Ejecutar, –
Ahora, ejecute los siguientes comandos de python en el shell
Aquí está el resultado de todas estas operaciones en la terminal:

Validación en campos numéricos
Tenga en cuenta que el lema principal de estos campos es impartir validaciones, como IntegerField valida los datos solo para Python. Verifiquemos si estas validaciones funcionan o no:
Aquí está el resultado de estos comandos que muestra claramente que el correo electrónico y el número de teléfono no son válidos:
Conceptos avanzados
Las validaciones son parte de la deserialización y no de la serialización. Como se explicó anteriormente, la serialización es un proceso de conversión de datos ya creados en otro tipo de datos, por lo que no se requieren estas validaciones predeterminadas. La deserialización requiere validaciones ya que los datos deben guardarse en la base de datos o cualquier otra operación según lo especificado. Entonces, si serializa datos usando estos campos, eso funcionaría.
Argumentos centrales en los campos del serializador
.math-table { borde-colapso: colapsar; ancho: 100%; } .math-table td { borde: 1px sólido #5fb962; alineación de texto: izquierda! importante; relleno: 8px; } .math-table th { borde: 1px sólido #5fb962; relleno: 8px; } .math-table tr>th{ color de fondo: #c6ebd9; alineación vertical: medio; } .math-table tr:nth-child(odd) { background-color: #ffffff; }
| Argumento | Descripción |
|---|---|
| solo lectura | Establézcalo en True para asegurarse de que el campo se use al serializar una representación, pero no al crear o actualizar una instancia durante la deserialización. |
| escribir solamente | Establézcalo en True para asegurarse de que el campo se pueda usar al actualizar o crear una instancia, pero no se incluya al serializar la representación. |
| requerido | Establecer esto en False también permite omitir el atributo del objeto o la clave del diccionario de la salida al serializar la instancia. |
| defecto | Si se establece, proporciona el valor predeterminado que se utilizará para el campo si no se proporciona ningún valor de entrada. |
| permitir nula | Normalmente, se generará un error si se pasa Ninguno a un campo serializador. Establezca este argumento de palabra clave en Verdadero si Ninguno debe considerarse un valor válido. |
| fuente | El nombre del atributo que se utilizará para rellenar el campo. |
| validadores | Una lista de funciones de validación que deben aplicarse a la entrada de campo entrante y que generan un error de validación o simplemente regresan. |
| error de mensajes | Un diccionario de códigos de error a mensajes de error. |
| etiqueta | Una string de texto corta que se puede usar como el nombre del campo en campos de formulario HTML u otros elementos descriptivos. |
| texto de ayuda | Una string de texto que se puede utilizar como descripción del campo en campos de formulario HTML u otros elementos descriptivos. |
| inicial | Un valor que debe usarse para completar previamente el valor de los campos de formulario HTML. |
Seaborn es una increíble biblioteca de visualización para el trazado de gráficos estadísticos en Python. Proporciona hermosos estilos predeterminados y paletas de colores para hacer que los gráficos estadísticos sean más atractivos. Está construido en la parte superior de la biblioteca matplotlib y también está estrechamente integrado a las estructuras de datos de pandas .
seaborn.residplot() :
Este método se utiliza para trazar los residuos de la regresión lineal. Este método hará una regresión de y sobre x y luego dibujará un gráfico de dispersión de los residuos. Opcionalmente, puede ajustar un suavizador lowess a la gráfica residual, lo que puede ayudar a determinar si hay una estructura para los residuales.
Sintaxis: seaborn.residplot(x, y, data=Ninguno, lowess=False, x_partial=Ninguno, y_partial=Ninguno, order=1,
robusto=False, dropna=True, label=Ninguno, color=Ninguno, scatter_kws=Ninguno, line_kws=Ninguno, ax=Ninguno)Parámetros: La descripción de algunos parámetros principales se da a continuación:
- x: Datos o nombre de columna en ‘datos’ para la variable predictora.
- y: Datos o nombre de columna en ‘datos’ para la variable de respuesta.
- data: (opcional) DataFrame que tiene `x` e `y` son nombres de columna.
- lowess: (opcional) ajuste un lowess más suave al diagrama de dispersión residual.
- dropna: (opcional) Este parámetro toma valor booleano. Si es Verdadero, ignore las observaciones con datos faltantes al ajustar y trazar.
Retorno: Ejes con el gráfico de regresión.
A continuación se muestra la implementación del método anterior:
Ejemplo 1:
Producción:
Ejemplo 2:
Producción:
Python es un lenguaje de programación de alto nivel y propósito general ampliamente utilizado. Los programas de Python generalmente son más pequeños que otros lenguajes de programación como Java. Los programadores tienen que escribir relativamente menos y los requisitos de sangría del lenguaje los hacen legibles todo el tiempo. Sin embargo, los programas de Python se pueden hacer más concisos usando algunos códigos de una sola línea. Estos pueden ahorrar tiempo al tener menos código para escribir.
Consulte los siguientes artículos para saber más sobre Python.
One-Liners en Python
One-Liner #1: Para ingresar enteros separados por espacios en una lista: suponga que desea tomar entradas separadas por espacios de la consola y desea convertirlas en List. Para hacer esto , se puede usar la función map() que toma el método int() y los métodos input().split() como parámetro. Aquí, el método int() se usa para convertir la entrada a tipo int y los métodos input().split() se usan para tomar la entrada de la consola y dividir la entrada por espacios. A continuación se muestra la implementación.
Nota: Para saber más sobre la función map() de Python, haga clic aquí . One-Liner #2: Para ingresar una array 2-D (cuando las entradas se dan en forma de fila): el método más ingenuo que viene a la mente al tomar una entrada para la array 2-D se proporciona a continuación.
El código anterior se puede escribir en una sola línea que es mucho más conciso y ahorra tiempo, especialmente para los programadores competitivos.
One-Liner #3: Conocemos este hecho, pero a veces tendemos a ignorarlo mientras traducimos de otros idiomas. Es el intercambio de dos números. La forma más ingenua de hacer esto es:
Sin embargo, Python también proporciona una línea para esto. La forma pythonica es:
Funciones Lambda de una línea n .° 4 (funciones anónimas) : las funciones Lambda son funciones de una línea de Python y se utilizan a menudo cuando se va a evaluar una expresión. Por ejemplo, supongamos que queremos crear una función que devuelva el cuadrado del número pasado como argumento. La forma normal de hacer esto es:
Producción:
La función Lambda reemplaza una función dondequiera que se evalúe una sola expresión.
Producción:
One-Liner #5 Comprensiones de listas: esta es una forma concisa de crear listas. En lugar de hacerlo de la manera habitual, podemos hacer uso de listas de comprensión. Por ejemplo, queremos crear una lista de números pares hasta el 11. La forma normal de hacerlo es:
Producción:
La forma pythonica:
Producción:
One-Liner #6: este truco puede ayudar al usar if-else o while loop. En lugar de hacer esto –
Podemos codificarlo como:
One-Liner #7: Hay varias formas de revertir una lista en python. Maneras pythonicas de invertir una lista:
- Usando la técnica de corte: esta técnica crea la copia de la lista mientras se invierte. Ocupa más memoria.
Producción:
- Usando la función inversa: invierte el contenido del objeto de la lista en el lugar.
Producción:
One-Liner #8: Puedes tomar esto como un desafío. Hacer patrones de python de una sola línea. Por ejemplo, haga que el siguiente código sea conciso en una línea.
Producción:
Conciso todo esto en una sola línea es divertido.
Producción:
One-Liner #9 Encontrar el factorial. La forma normal de encontrar un factorial es iterar hasta ese número y multiplicar el número en cada iteración.
Producción:
Podemos usar math.factorial(x)- Devuelve el factorial de x. Pero genera un error de valor si el número es negativo o no es integral.
Producción:
Una forma más de encontrar el factorial de manera concisa es usando reduce() y la función lambda.
Producción:
One-Liner #10: Encontrar todos los subconjuntos de un conjunto en una línea. La forma habitual requiere mucho trabajo duro y se puede ver aquí . Se puede hacer de una forma mucho más sencilla usando itertools.combinations()
[(1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4)]
One-Liner #11: Lea el archivo en python e introdúzcalo en una lista.
Un código de línea es:
Los números aleatorios son una parte imprescindible de muchos sistemas, incluidas las simulaciones, la criptografía y mucho más. Por lo tanto, la capacidad de producir valores aleatoriamente, sin lógica ni previsibilidad aparentes, se convierte en una función primordial. Dado que las computadoras no pueden producir valores que sean completamente aleatorios, se utilizan algoritmos, conocidos como generadores de números pseudoaleatorios (PRNG) , para realizar esta tarea.
Los valores producidos por los PRNG no son realmente aleatorios y dependen del valor inicial proporcionado al algoritmo, conocido como valor inicial. La propiedad de que una secuencia pseudoaleatoria sea reproducible, dado su valor inicial, es esencial para su aplicación en simulaciones, como la simulación de Monte Carlo, donde es posible que el sistema deba probarse en la misma secuencia más de una vez.
Algunos de los PRNG más populares y más utilizados son:
- Mersenne Twister: se utiliza como generador de números aleatorios predeterminado en Python, R, Excel, Matlab, Ruby y muchos otros sistemas de software populares.
- Generador congruencial lineal: utilizado en C++ y Java
- Generador Wichmann-Hill: se usa en Excel y era el predeterminado en Python 2.2
- Generador Park-Miller
- Secuencia de Weyl del cuadrado medio
Para garantizar que los valores generados por el PRNG sean lo más aleatorios posible, se utilizan varias pruebas estadísticas, incluidas las pruebas Diehard, la serie TestU01, la prueba Chi-Square y la prueba Runs of Randomness. Este artículo se centra en la Prueba de rachas de aleatoriedad.
¿Qué es la Prueba de Carreras?
Una corrida se define como una serie de valores crecientes o decrecientes. El número de valores crecientes o decrecientes es la duración de la ejecución.
- El primer paso para aplicar esta prueba es formular la hipótesis nula y alternativa.
H nulo : la secuencia se produjo de forma aleatoria
H alt : La secuencia no se produjo de manera aleatoria
- Calcule el estadístico de prueba, Z como:
Producción:
A veces, mientras trabajamos con tuplas, podemos tener un problema en el que necesitamos imprimir tuplas, sin espacio entre la coma y el siguiente elemento, que por convención está presente. Este problema puede tener utilidad en la programación diurna y escolar. Analicemos ciertas formas en que se puede realizar esta tarea.
Entrada : test_tuple = (7, 6, 8)
Salida : (7, 6, 8)
Entrada : test_tuple = (6, 8)
Salida : (6, 8)
Método #1: Usar str() + replace()
La combinación de las funciones anteriores se puede usar para resolver este problema. En esto, realizamos la tarea de eliminar el espacio adicional, reemplazándolo con espacio vacío.
The original tuple : (4, 5, 7, 6, 8) The tuple after space removal : (4, 5, 7, 6, 8)
Método #2: Usar join() + map()
Otro método para resolver este problema. En esto, realizamos la tarea de eliminar el espacio mediante la unión externa de cada elemento usando join() y extendiendo la lógica de conversión de strings a cada elemento usando map().
The original tuple : (4, 5, 7, 6, 8) The tuple after space removal : (4, 5, 7, 6, 8)
En este artículo, aprenderemos cómo crear una array Numpy llena solo de ceros, dada la forma y el tipo de array.
Podemos usar el método Numpy.zeros() para realizar esta tarea. Este método toma tres parámetros, discutidos a continuación:
Ejemplo 1:
Producción:
Ejemplo #2:
Producción:
La serie es un tipo de lista en pandas que puede tomar valores enteros, valores de string, valores dobles y más. Pero en Pandas Series devolvemos un objeto en forma de lista, con un índice que comienza de 0 a n , donde n es la longitud de los valores en serie. Más adelante en este artículo, discutiremos los marcos de datos en pandas, pero primero debemos comprender la diferencia principal entre Series y Dataframe . Las series solo pueden contener una lista única con índice, mientras que el marco de datos puede estar compuesto por más de una serie o podemos decir que un marco de datos es una colección de series que se pueden usar para analizar los datos.
Código #1: Creando una Serie simple
Producción:
Verifiquemos el tipo de Serie:
Producción:
Código n.º 2: creación de marcos de datos a partir de varias series
Producción:
Explicación: Hemos creado dos listas ‘autor’ y artículo’ que se han pasado a las funciones Series() para crear dos Series. Después de crear la Serie, creamos un diccionario y pasamos los objetos de la Serie como valores del diccionario y las claves del diccionario se servirán como Columnas del marco de datos.
Código #3: Cómo agregar una nueva columna al marco de datos
Producción:
Explicación: Agregamos una serie más denominada externamente como la edad de los autores, luego agregamos directamente esta serie en el marco de datos de pandas. Recuerde una cosa si falta algún valor, por defecto se convertirá en valor NaN, es decir, nulo por defecto.
Código # 4: valor faltante en el marco de datos
Producción:
Código n. ° 5: creación de un marco de datos usando el diccionario de la serie
Producción:
Explicación: aquí, hemos pasado un diccionario que se ha creado usando una serie como valores y luego pasamos este diccionario para crear un marco de datos. Podemos ver que al crear un marco de datos usando el diccionario, las claves del diccionario se convertirán en Columnas y los valores se convertirán en Filas.
Código n. ° 6: agregar un índice explícito al marco de datos
Producción:
Explicación: Aquí podemos ver que después de proporcionar un índice al marco de datos explícitamente, ha llenado todos los datos con valores NaN ya que hemos creado este marco de datos usando Series y Series tiene sus propios índices predeterminados (0,1,2), es por eso que cuando los índices de tanto el marco de datos como la serie no coinciden, obtuvimos todos los valores de NaN. Podemos rectificar este problema proporcionando los mismos valores de índice para todos los elementos de la Serie. Vamos a ver cómo podemos hacer esto.
Producción:
Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
La función Pandas Index.unique()devuelve valores únicos en el índice. Los únicos se devuelven en orden de aparición, esto NO se ordena.
Sintaxis: Index.unique(nivel=Ninguno)
Parámetros:
nivel: solo devuelve valores del nivel especificado (para MultiIndex)Devoluciones : Índice sin duplicados
Ejemplo #1: Use Index.unique()la función para devolver valores únicos en el índice.
Producción :
Busquemos todos los valores únicos en el Índice.
Salida:
la función ha devuelto un nuevo índice que tiene todos los valores únicos del índice original.
Ejemplo #2: Use Index.unique()la función para encontrar los valores únicos en el índice
Producción :
Encontremos todos los valores únicos en el índice.
Salida:
la función ha devuelto un nuevo índice que contiene todos los valores únicos en el índice original.
random()La función se utiliza para generar números aleatorios en Python. En realidad, no es aleatorio, sino que se usa para generar números pseudoaleatorios. Eso implica que estos números generados aleatoriamente pueden determinarse.
random()La función genera números para algunos valores. Este valor también se llama valor inicial .
¿Cómo funciona la función de la semilla?
La función semilla se usa para guardar el estado de una función aleatoria, de modo que pueda generar los mismos números aleatorios en múltiples ejecuciones del código en la misma máquina o en diferentes máquinas (para un valor inicial específico). El valor inicial es el número de valor anterior generado por el generador. Por primera vez cuando no hay un valor anterior, utiliza la hora actual del sistema.
Usando random.seed()la función
Aquí veremos cómo podemos generar el mismo número aleatorio cada vez con el mismo valor semilla.
Ejemplo 1:
865 865 865 865 865
Ejemplo 2:
244 244 607
Al ejecutar el código anterior, las dos declaraciones de impresión anteriores generarán una respuesta 244 , pero la tercera declaración de impresión da una respuesta impredecible.
Usos de random.seed()
- Esto se utiliza en la generación de una clave de cifrado pseudoaleatoria. Las claves de cifrado son una parte importante de la seguridad informática. Estos son el tipo de claves secretas que se utilizan para proteger los datos del acceso no autorizado a través de Internet.
- Facilita la optimización de los códigos cuando se utilizan números aleatorios para las pruebas. La salida del código en algún momento depende de la entrada. Entonces, el uso de números aleatorios para probar algoritmos puede ser complejo. Además, la función semilla se usa para generar los mismos números aleatorios una y otra vez y simplifica el proceso de prueba del algoritmo.
Tensorflow es una biblioteca de aprendizaje automático de código abierto desarrollada por Google. Una de sus aplicaciones es desarrollar redes neuronales profundas.
El módulo tensorflow.math brinda soporte para muchas operaciones matemáticas básicas. La función tf.atan() [alias tf.math.atan] brinda soporte para la función de tangente inversa en Tensorflow. Da la salida en forma de radianes. El tipo de entrada es tensor y si la entrada contiene más de un elemento, se calcula la tangente inversa por elementos.
Sintaxis : tf.atan(x, nombre=Ninguno) o tf.math.atan(x, nombre=Ninguno)
Parámetros :
x : Un tensor de cualquiera de los siguientes tipos: bfloat16, half, float32, float64, int32, int64, complejo64, o complejo128.
nombre (opcional): el nombre de la operación.
Tipo de retorno : Un tensor con el mismo tipo que el de x.
Código #1:
Producción:
Código #2: Visualización
Producción:
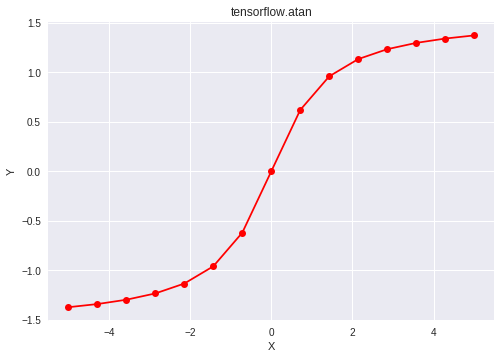
Los problemas relacionados con la array son bastante comunes tanto en la programación competitiva como en el dominio de la ciencia de datos. Uno de esos problemas que podríamos enfrentar es encontrar la concatenación de filas de array en array de tamaño desigual. Analicemos ciertas formas en que se puede resolver este problema.
Método n.º 1: Uso join()de la comprensión de lista +
La combinación de las funciones anteriores puede ayudar a obtener la solución a este problema en particular en una sola línea y, por lo tanto, es muy útil. La función de unión calcula la concatenación de sublistas y todo esto se une mediante la comprensión de listas.
The original list : [['gfg', ' is', ' best'], ['Computer', ' Science'], ['GeeksforGeeks']] The row concatenation in matrix : ['gfg is best', 'Computer Science', 'GeeksforGeeks']
Método n.º 2: Uso del bucle
Esta tarea también se puede realizar de manera de fuerza bruta en la que solo iteramos las sublistas y realizamos la unión de manera bruta creando una nueva string para cada sublista y agregando en la lista.
The original list : [['gfg', ' is', ' best'], ['Computer', ' Science'], ['GeeksforGeeks']] The row concatenation in matrix : ['gfg is best', 'Computer Science', 'GeeksforGeeks']
En este artículo, vamos a discutir varios métodos para convertir mp3 a formato de archivo wave usando Python.
Método 1:
Primero necesitamos instalar ffmpeg. Es un proyecto de software gratuito de código abierto que consta de un gran conjunto de bibliotecas y programas para manejar video, audio y otros archivos multimedia.
Así que primero vamos a instalar pydub . Este es un módulo de manipulación de audio. Python proporciona un módulo llamado pydub para trabajar con archivos de audio. pydub es una biblioteca de Python para trabajar solo con archivos .wav.
Programa:
Producción:
Aquí puede ver que hay un script de python y un archivo hello.mp3 que lo convierte en un archivo result.wav.
El módulo pydub utiliza programas ffmpeg o avconf para realizar la conversión real. Así que tienes que instalar ffmpeg para que esto funcione. Pero si no necesita pydub para nada más, puede usar el módulo de subproceso integrado para llamar a un programa de conversión como ffmpeg , que se muestra en el siguiente método.
Método 2:
Es un simple script o código de dos líneas para convertir un archivo mp3 a un archivo wav.
Aquí no necesitamos el módulo pydub , podemos usar el módulo de subproceso incorporado para llamar al programa convertidor ffmpeg como se muestra a continuación:
Programa:
Producción:
Como puede ver, se genera el formato de onda.
Un objeto es una instancia de una clase. Una clase es como un modelo, mientras que una instancia es una copia de la clase con valores reales. Cuando se crea un objeto de una clase, se dice que la clase está instanciada. Todas las instancias comparten los atributos y el comportamiento de la clase. Pero los valores de esos atributos, es decir, el estado son únicos para cada objeto. Una sola clase puede tener cualquier número de instancias.
Consulte los artículos a continuación para tener una idea sobre las clases y los objetos en Python.
Los objetos de impresión nos dan información sobre los objetos con los que estamos trabajando. En C++, podemos hacer esto agregando un método de ostream&operador amigo para la clase. << (ostream&, const Foobar&)En Java, usamos el toString()método. En Python, esto se puede lograr mediante el uso de métodos __repr__o . se usa si necesitamos información detallada para la depuración, mientras que se usa para imprimir una versión de string para los usuarios.__str____repr____str__
Ejemplo:
Producción:
Puntos importantes sobre la impresión:
- Python usa el
__repr__método si no hay ningún__str__método.Ejemplo:
classTest:def__init__(self, a, b):self.a=aself.b=bdef__repr__(self):return"Test a:% s b:% s"%(self.a,self.b)# Driver Codet=Test(1234,5678)print(t)Producción:
Test a:1234 b:5678
- Si no se define ningún método __repr__, se usa el predeterminado.
Ejemplo:
classTest:def__init__(self, a, b):self.a=aself.b=b# Driver Codet=Test(1234,5678)print(t)Producción:
<__main__.Test object at 0x7f9b5738c550>
El módulo de secretos se usa para generar números aleatorios para administrar datos importantes, como contraseñas, autenticación de cuentas, tokens de seguridad y secretos relacionados, que son criptográficamente fuertes. Este módulo es responsable de brindar acceso a la fuente más segura de aleatoriedad. Este módulo está presente en Python 3.6 y superior.
Números aleatorios: secretos de clase.SystemRandom
Esta clase utiliza la función os.urandom() para la generación de números aleatorios a partir de fuentes proporcionadas por el sistema operativo.
- secrets.choice(secuencia): esta función devuelve un elemento elegido al azar de una secuencia no vacía para administrar un nivel básico de seguridad.
Ejemplo 1: Genere una contraseña alfanumérica de diez caracteres.importsecretsimportstringalphabet=string.ascii_letters+string.digitspassword=''.join(secrets.choice(alphabet)foriinrange(10))print(password)Producción :
'tmX47l1uo4'
Ejemplo 2: genere una contraseña alfanumérica de diez caracteres con al menos un carácter en minúscula, al menos un carácter en mayúscula y al menos tres dígitos.
importsecretsimportstringalphabet=string.ascii_letters+string.digitswhileTrue:password=''.join(secrets.choice(alphabet)foriinrange(10))if(any(c.islower()forcinpassword)andany(c.isupper()forcinpassword)andsum(c.isdigit()forcinpassword) >=3):print(password)breakProducción :
Tx8LppU05Q
- secrets.randbelow(n) : esta función devuelve un número entero aleatorio en el rango [0, n).
importsecretspasswd=secrets.randbelow(20)print(passwd)Producción :
2
- secrets.randbits(k): esta función devuelve un int con k bits aleatorios.
importsecretspasswd=secrets.randbits(7)print(passwd)Producción :
61



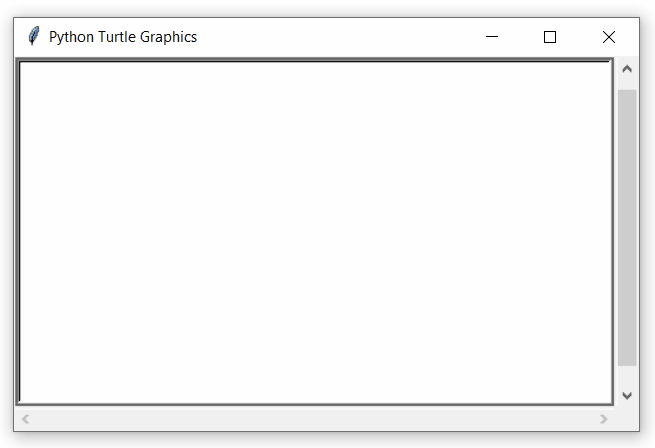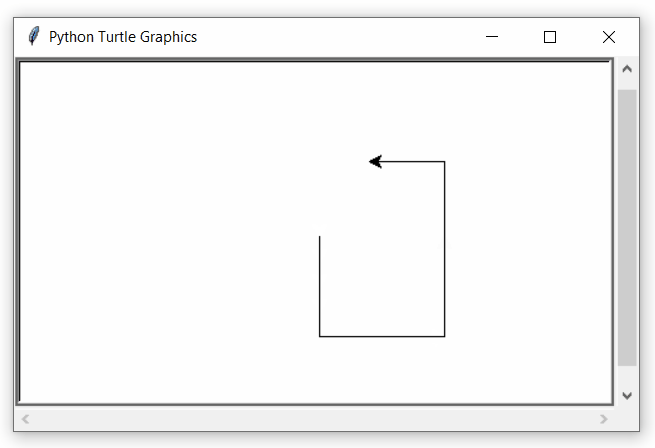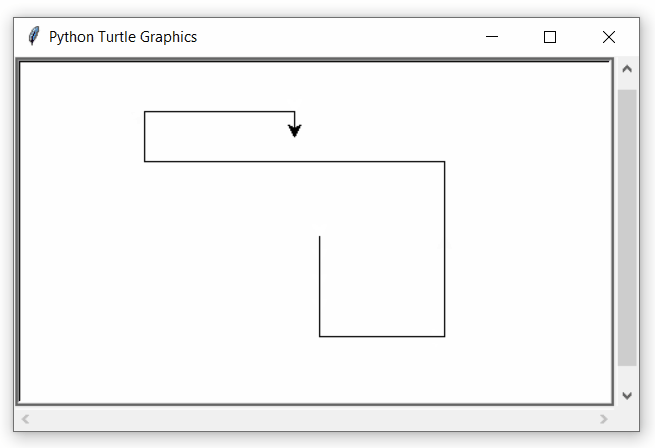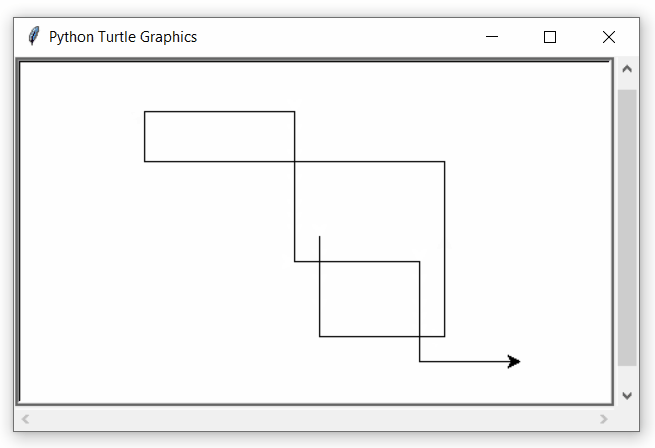
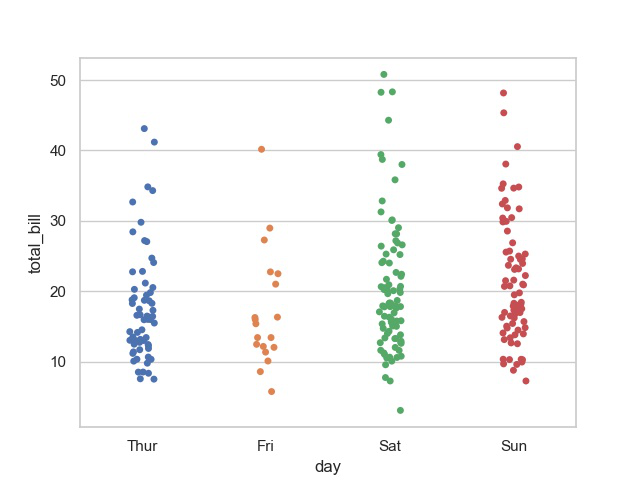
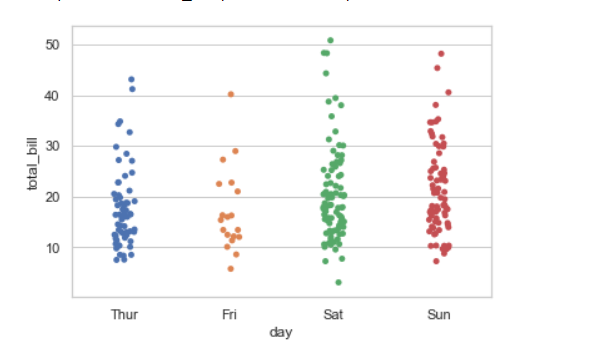
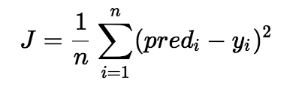
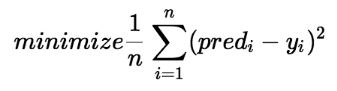

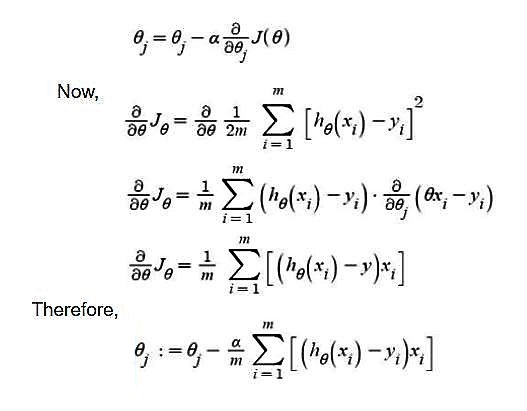
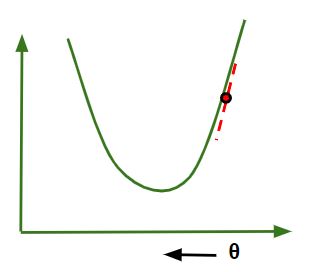
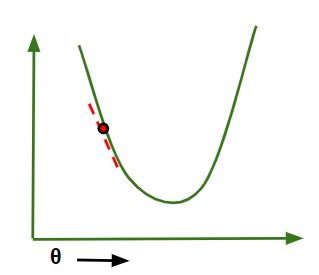
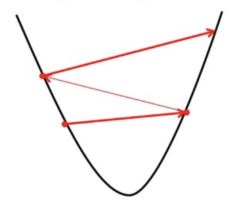
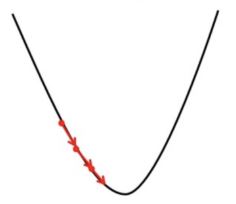
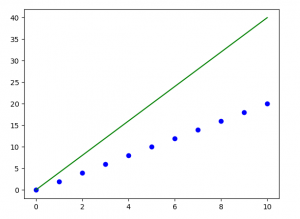










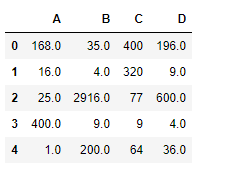


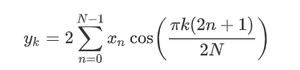
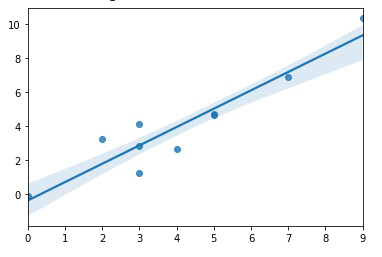
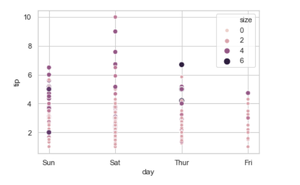

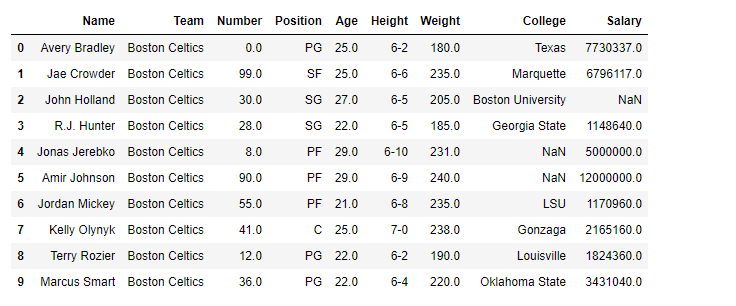
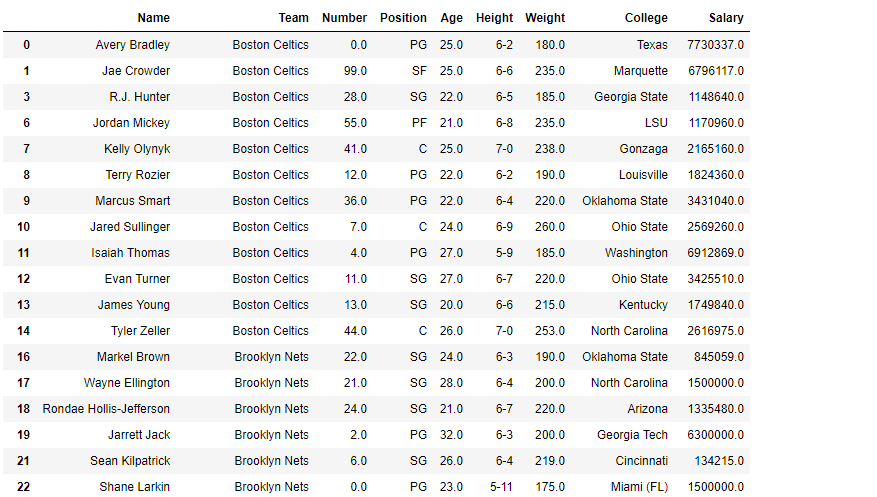
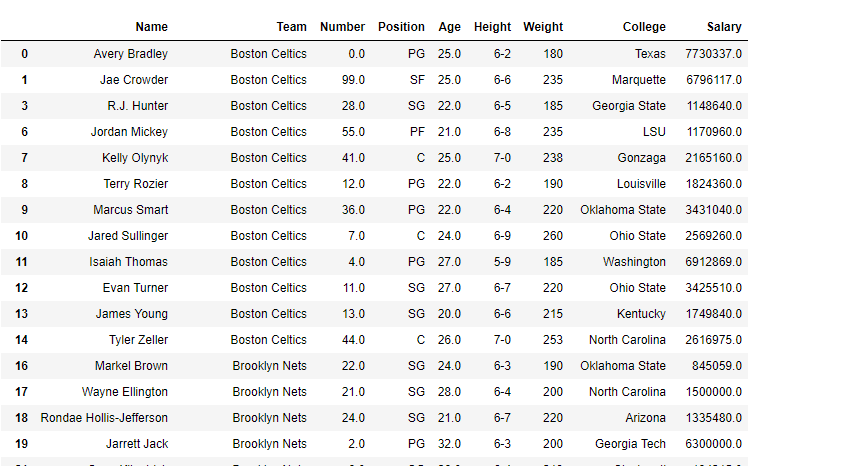
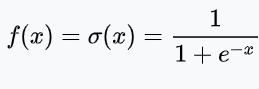
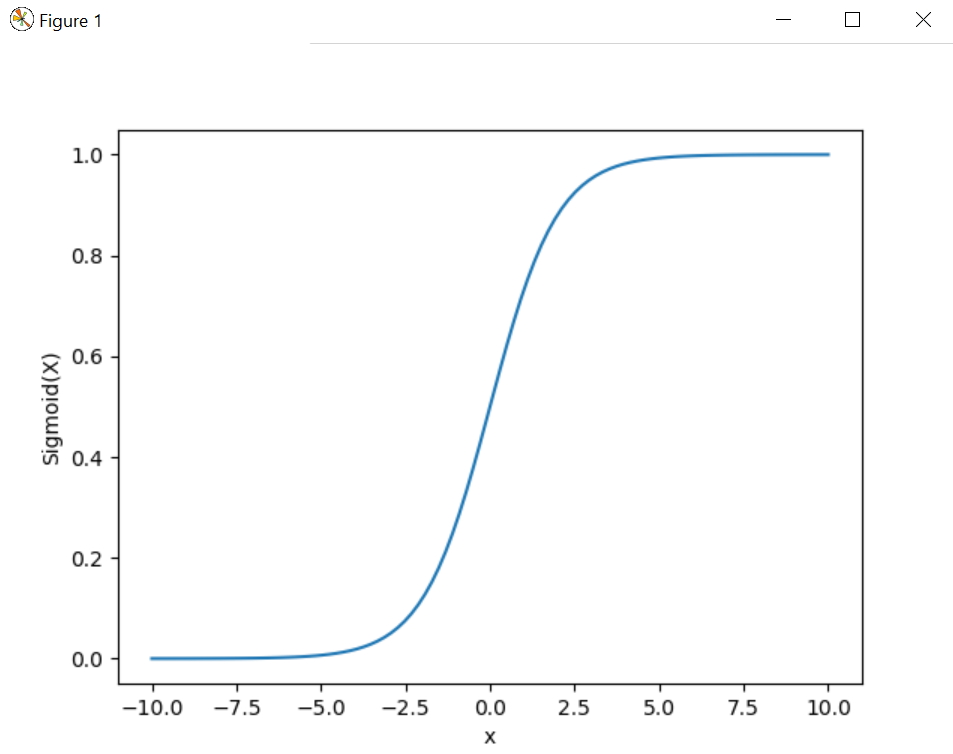
![\[s = 2\times\sqrt{\frac{M_{00}}{256}}\]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-8c152ed637778b42ef5ae34ce1d2ad73_l3.png "Rendered by QuickLaTeX.com")



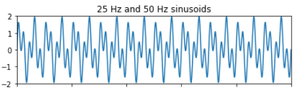
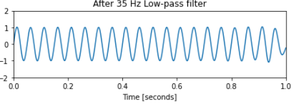
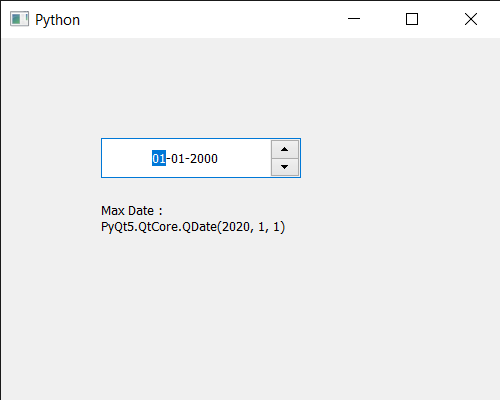










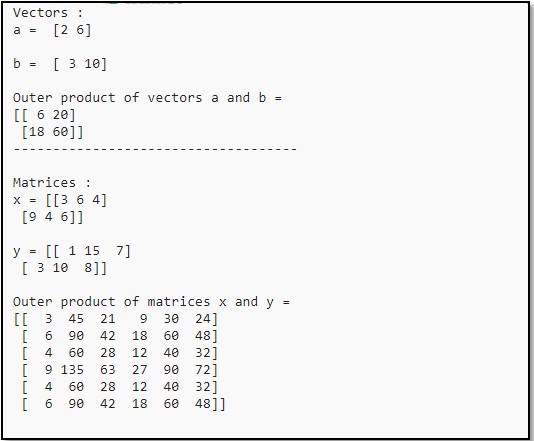






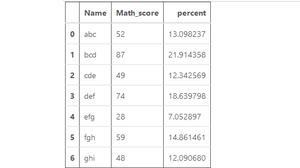
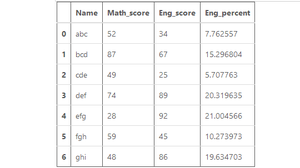
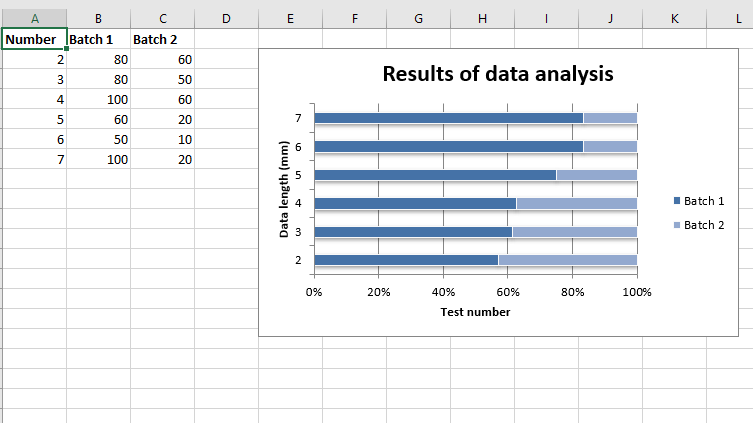






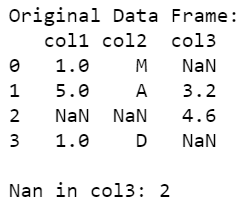
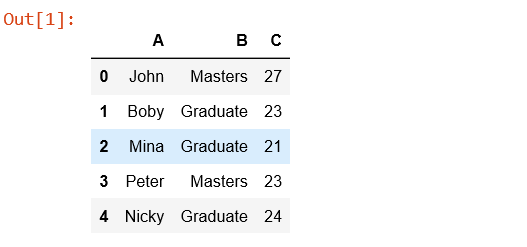
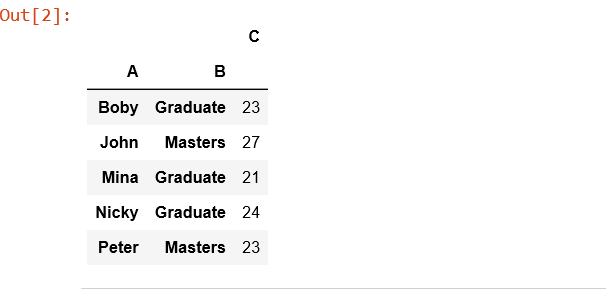
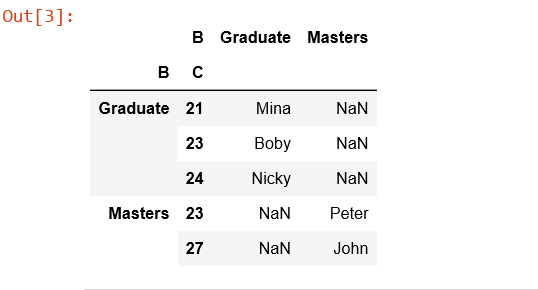


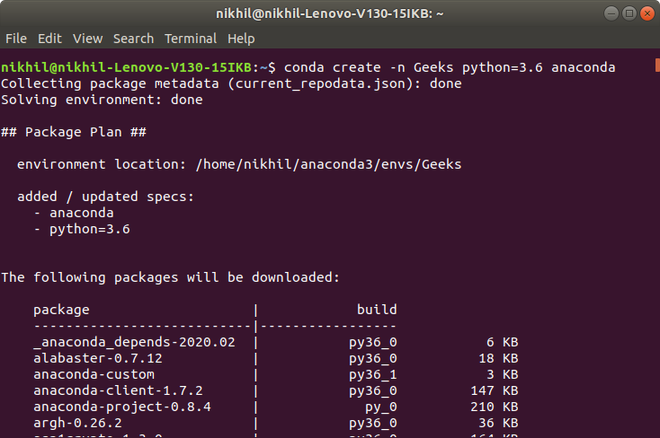


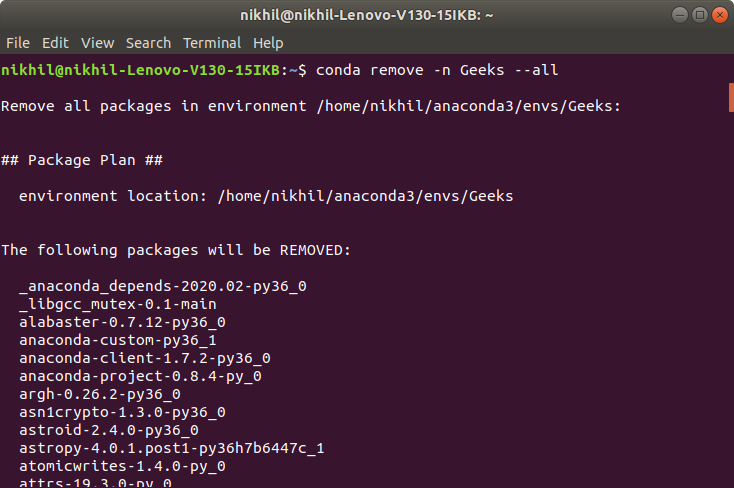
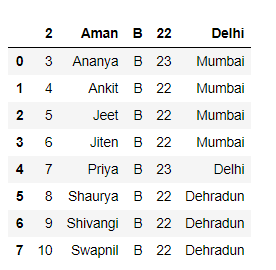
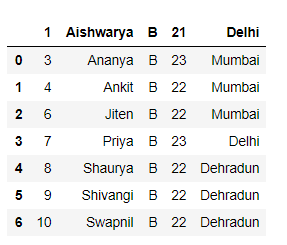
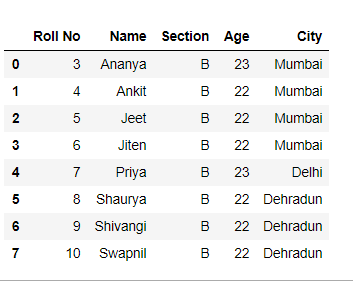
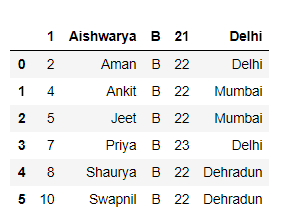
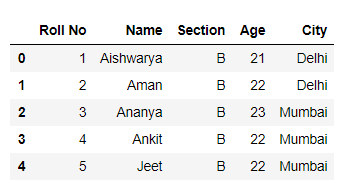









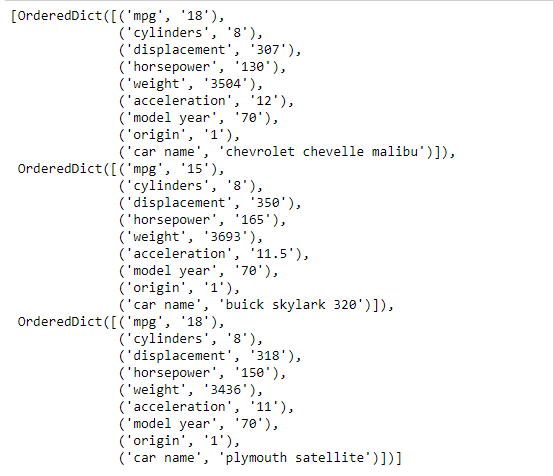


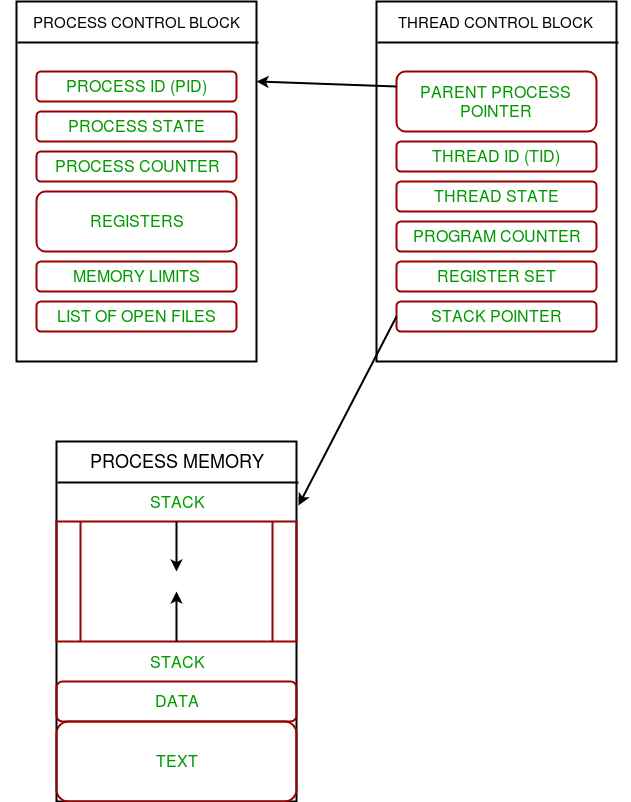






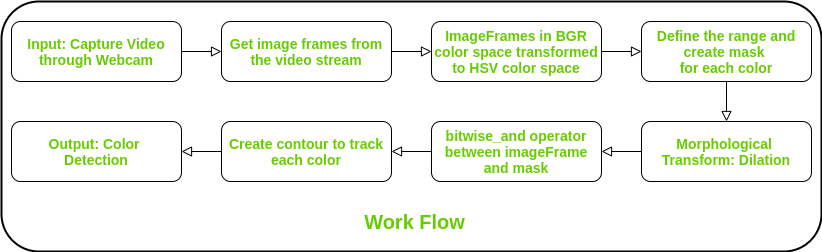


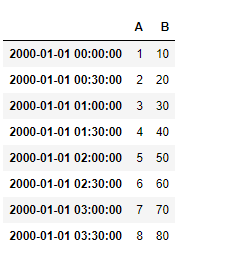

- umbral : el umbral es el número máximo de puntos de datos que puede contener un subclúster en el Node hoja del árbol CF.
- branching_factor : este parámetro especifica el número máximo de subclústeres de CF en cada Node (Node interno).
- n_clusters : el número de clústeres que se devolverán después de que se complete todo el algoritmo BIRCH, es decir, el número de clústeres después del último paso de agrupación. Si se establece en Ninguno, no se realiza el paso de agrupación final y se devuelven las agrupaciones intermedias.
Implementación de BIRCH en Python: por el bien de este ejemplo, generaremos un conjunto de datos para agrupar usando el método make_blobs() de scikit-learn. Para obtener más información sobre make_blobs(), puede consultar el siguiente enlace: https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_blobs.html Código: para crear 8 clústeres con 600 muestras generadas aleatoriamente y luego graficar los resultados en un diagrama de dispersión.
Gráfico de salida:
El método divmod() en python toma dos números y devuelve un par de números que consisten en su cociente y resto.
Sintaxis:
Ejemplos:
Explicación: el método divmod() toma dos parámetros x e y, donde x se trata como numerador e y como denominador. El método calcula tanto x // y como x % y y devuelve ambos valores.
- Si x e y son números enteros, el valor devuelto es
- Si x o y es un flotante, el resultado es
Producción:
Errores y excepciones
- Si cualquiera de los argumentos (por ejemplo, x e y) es flotante, el resultado es (q, x% y). Aquí, q es la parte entera del cociente.
- Si el segundo argumento es 0, devuelve Error de división cero
- Si el primer argumento es 0, devuelve (0, 0)
Aplicación práctica: comprueba si un número es primo o no usando la función divmod().
Ejemplos:
Algoritmo
- Inicialice una nueva variable, digamos x con el entero dado y un contador de variable a 0
- Ejecute un ciclo hasta que el entero dado se convierta en 0 y siga decrementándolo.
- Guarde el valor devuelto por divmod (n, x) en dos variables, digamos p y q
- Compruebe si q es 0, esto implicará que n es perfectamente divisible por x y, por lo tanto, incrementará el valor del contador
- Compruebe si el valor del contador es mayor que 2, si es así, el número no es primo, de lo contrario es primo
Producción:
Más aplicaciones:
Ejemplo 1:
Producción:
Ejemplo 2:
Producción:
Introducción a las SVM: en el aprendizaje automático, las máquinas de vectores de soporte (SVM, también redes de vectores de soporte) son modelos de aprendizaje supervisado con algoritmos de aprendizaje asociados que analizan los datos utilizados para la clasificación y el análisis de regresión. Una máquina de vectores de soporte (SVM) es un clasificador discriminativo definido formalmente por un hiperplano de separación. En otras palabras, dados los datos de entrenamiento etiquetados (aprendizaje supervisado), el algoritmo genera un hiperplano óptimo que categoriza nuevos ejemplos.
¿Qué es la máquina de vectores de soporte?
Matplotlib es una biblioteca en Python y es una extensión matemática numérica para la biblioteca NumPy. La clase Axes contiene la mayoría de los elementos de la figura: Axis, Tick, Line2D, Text, Polygon, etc., y establece el sistema de coordenadas. Y las instancias de Axes admiten devoluciones de llamada a través de un atributo de devoluciones de llamada.
función matplotlib.axes.Axes.tick_params()
La función Axes.tick_params() en el módulo de ejes de la biblioteca matplotlib se usa para controlar el comportamiento de los principales localizadores de ticks.
Sintaxis: Axes.tick_params(self, axis=’ambos’, **kwargs)
Parámetros: este método acepta los siguientes parámetros.
- eje : Este parámetro es el utilizado a qué eje aplicar los parámetros.
Valor devuelto: Este método no devuelve ningún valor.
Los siguientes ejemplos ilustran la función matplotlib.axes.Axes.tick_params() en matplotlib.axes:
Ejemplo 1:
Producción:
Ejemplo 2:
Producción:
En Pandas, tenemos la libertad de agregar columnas en el marco de datos cuando sea necesario. Hay varias formas de agregar columnas al marco de datos de Pandas.
Método 1: Agregar múltiples columnas a un marco de datos usando Listas
Producción :
Método 2: agregue varias columnas a un marco de datos utilizando el método Dataframe.assign()
Producción :
Método 3: agregue varias columnas a un marco de datos utilizando el método Dataframe.insert()
Producción :

Método 4: Agregue múltiples columnas a un marco de datos usando Dictionary y zip()
Producción :

La función scipy.stats.sem(arr, axis=0, ddof=0) se usa para calcular el error estándar de la media de los datos de entrada.
Parámetros:
arr: [array_like] Array de entrada u objeto que tiene los elementos para calcular el error estándar.
eje : Eje a lo largo del cual se calculará la media. Por defecto eje = 0.
ddof : Grado de corrección de libertad para Desviación Estándar.Resultados: error estándar de la media de los datos de entrada.
Ejemplo:
Producción :
Matplotlib es una biblioteca en Python y es una extensión matemática numérica para la biblioteca NumPy. La clase Artist contiene una clase base Abstract para objetos que se representan en un FigureCanvas. Todos los elementos visibles en una figura son subclases de Artista.
El método get_clip_box() en el módulo de artista de la biblioteca matplotlib se usa para obtener el clipbox.
Sintaxis: Artist.get_clip_box(self)
Parámetros: Este método no acepta ningún parámetro.
Devoluciones: este método devuelve el estado animado.
Los siguientes ejemplos ilustran la función matplotlib.artist.Artist.get_clip_box() en matplotlib:
Ejemplo 1:
Producción:
Ejemplo 2:
Producción:
Requisito previo: Agrupación de K-Means | Introducción
Existe un método popular conocido como método del codo que se utiliza para determinar el valor óptimo de K para realizar el algoritmo de agrupación en clústeres de K-Means. La idea básica detrás de este método es que traza los distintos valores de costo con k cambiante . A medida que aumenta el valor de K , habrá menos elementos en el grupo. Entonces la distorsión promedio disminuirá. El menor número de elementos significa más cerca del centroide. Entonces, el punto donde más decae esta distorsión es el punto del codo .
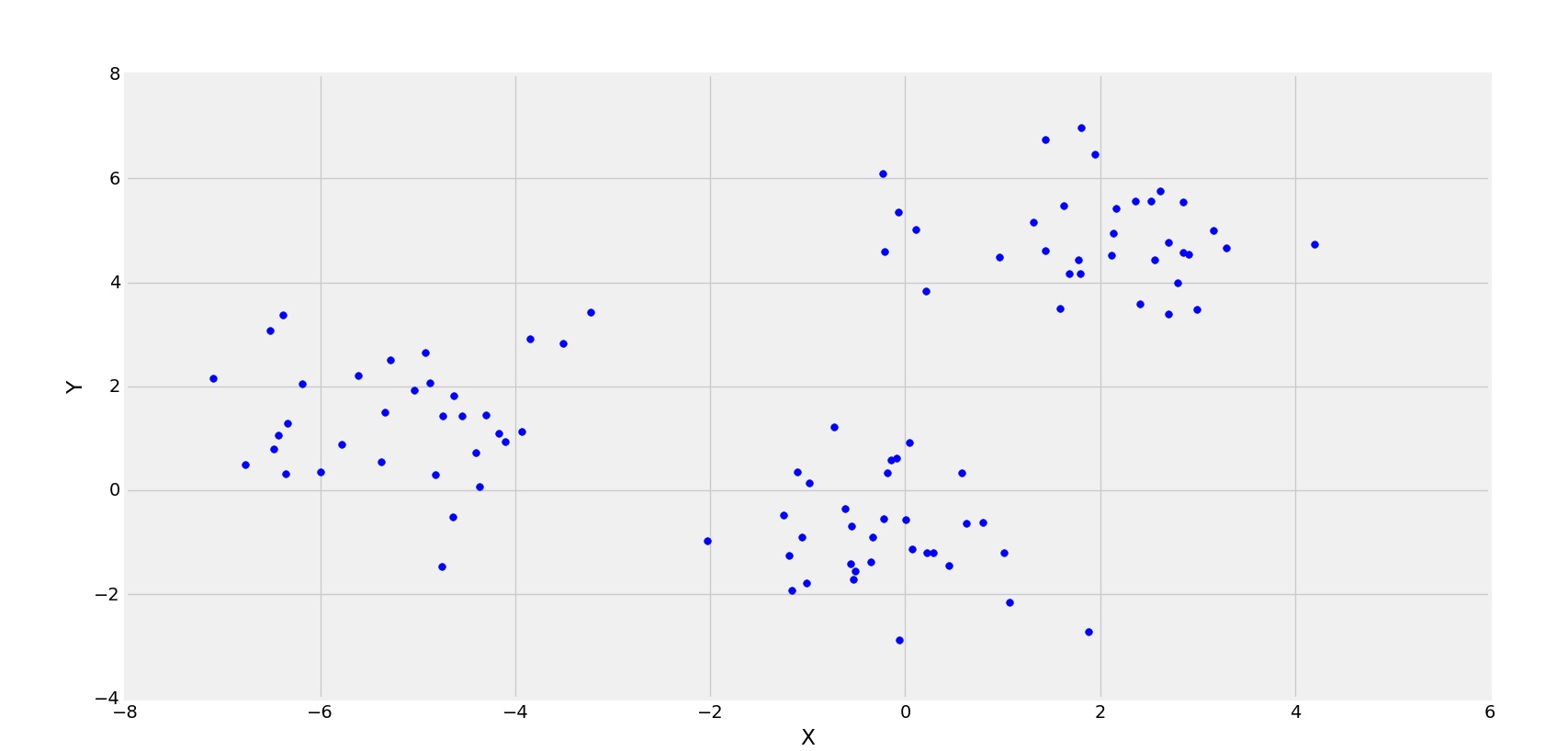
3 grupos se están formando
En la figura anterior, se observa claramente que la distribución de puntos está formando 3 grupos. Ahora, veamos la gráfica del error cuadrático (Costo) para diferentes valores de K.
El codo se está formando en K=3
Claramente el codo se está formando en K=3. Entonces, el valor óptimo será 3 para realizar K-Means.
Otro ejemplo con 4 clústeres.
4-clusters
Gráfico de costo correspondiente-
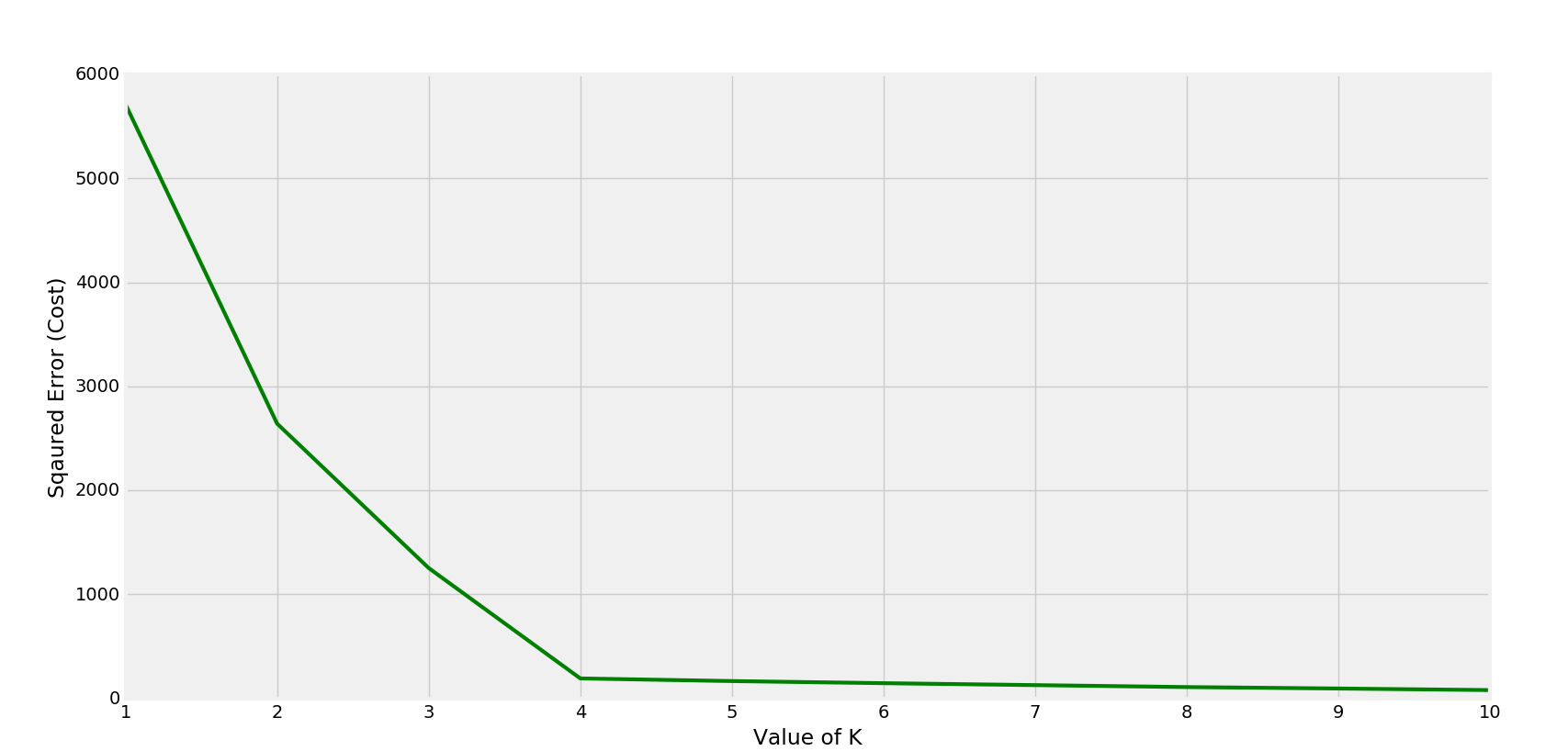
El codo se está formando en K=4
En este caso el valor óptimo de k sería 4. (Observable desde los puntos dispersos).
A continuación se muestra la implementación de Python:
Producción:
Producción:
Crear tipos de datos personalizados puede ser complicado, especialmente cuando desea usarlo como cualquier otro tipo de datos. La lista vinculada se puede considerar como un ejemplo de un tipo de datos personalizado. En otros idiomas, si desea imprimir la lista enlazada, definiría una función de impresión separada, algo así como pprint pero se ve un poco extraño, ¿verdad? Sería fantástico que la función de impresión predeterminada hiciera lo mismo, ¿verdad? Bueno, ahí es donde entra Python. Python tiene algunos métodos sorprendentes llamados métodos Dunder .
metodos dunder
Dunder significa doble bajo métodos. Básicamente, los métodos que comienzan y terminan con guiones bajos dobles se denominan métodos Dunder o métodos mágicos . Uno de esos ejemplos de método under es __init__ . Un método similar es __str__ , que usaremos en este artículo. Este método se puede utilizar para la impresión bonita en Python. Pretty print no es más que aplicar varios tipos de estilos y formatear el contenido que se va a imprimir. Obtenga más información sobre los métodos de dunder aquí .
Los métodos __str__ especifican lo que debe devolverse de una clase cuando esa clase se imprime utilizando la función de impresión estándar . Usando este concepto, podemos tener una representación mucho mejor del tipo de datos personalizado. A continuación se muestra un ejemplo de dicha representación personalizada. Tenga en cuenta que la atención se centra en la implementación de la lista enlazada, pero más en la forma pythonica de representarla.
Ejemplo: bastante imprimir una lista enlazada individualmente 10->15->20 como [10, 15, 20]
[10, 15, 20]
Tenga en cuenta que al imprimir la clase, __str__ se llama de forma predeterminada. Esta es la magia de Python. El objetivo principal de este artículo es mostrar cómo los pequeños métodos mágicos pueden hacer que sus vidas sean mucho más fáciles.
Matplotlib es una increíble biblioteca de visualización en Python para gráficos 2D de arrays. Matplotlib es una biblioteca de visualización de datos multiplataforma basada en arrays NumPy y diseñada para funcionar con la pila SciPy más amplia.
Matplotlib.colors.ListedColormap
La clase matplotlib.colors.ListedColormap pertenece al módulo matplotlib.colors . El módulo matplotlib.colors se usa para convertir argumentos de color o números a RGBA o RGB. Este módulo se usa para asignar números a colores o conversión de especificación de color en una array de colores 1-D también conocida como mapa de colores.
La clase matplotlib.colors.ListedColormap se usa para crear objetos colarmap a partir de una lista de colores. Esto puede ser útil para indexar directamente en el mapa de colores y también se puede usar para crear mapas de colores especiales para el mapeo normal.
Sintaxis: class matplotlib.colors.ListedColormap(colors, name=’from_list’, N=Ninguno)
Parámetros:
- colors: es una array o lista de especificaciones de color de Matplotlib o equivale a una array de punto flotante N x 3 o N x 4 (N valores rgb o rgba)
- name: Es un parámetro opcional que acepta una string para identificar el mapa de colores.
- N: Es un parámetro opcional que acepta un valor entero que representa el número de entradas en el mapa. Su valor predeterminado es Ninguno, donde hay una sola entrada de mapa de colores para cada elemento en la lista de colores. Si N es menor que len(colores), la lista se trunca en N, mientras que si N es mayor, la lista se amplía con repetición.
Métodos de la clase:
1) invertido(): Esto se utiliza para crear una instancia invertida del mapa de colores.
Sintaxis: invertida(self, nombre=Ninguno)
Parámetros:
- name: Es un parámetro opcional que representa el nombre del mapa de colores invertido. Si se establece en Ninguno, el nombre será el nombre del mapa de colores principal + «_r».
Devoluciones: Devuelve una instancia invertida del mapa de colores.
Ejemplo 1:
Producción:
Ejemplo 2:
Producción:
Dados dos números hexadecimales, escriba un programa en Python para calcular su suma.
Ejemplos:
Acercarse:
Para agregar dos valores hexadecimales en python, primero los convertiremos en valores decimales, luego los agregaremos y finalmente los convertiremos nuevamente a un valor hexadecimal. Para convertir los números haremos uso de la función hex() La función hex( ) es una de las funciones integradas en Python3, que se utiliza para convertir un número entero en su forma hexadecimal correspondiente. También usaremos la función int() para convertir el número a forma decimal. La función int() en Python y Python3 convierte un número en la base dada a decimal.
A continuación se muestran las implementaciones basadas en el enfoque anterior:
Ejemplo 1:
393
Ejemplo 2:
17
Ejemplo 3:
393
En este artículo, veremos cómo podemos recuperar la información de las 250 mejores películas en la base de datos de IMDb, IMDb establece calificaciones para todas las películas. Para obtener las 250 mejores películas de IMDb, utilizaremos el método get_top250_movies.
Sintaxis: imdb_object.get_top250_movies()
Argumento: no requiere argumento
Devolución: devuelve una lista de 250 elementos y cada elemento es un objeto de película imdb
A continuación se muestra la implementación.
Producción :
Las operaciones morfológicas son un conjunto de operaciones que procesan imágenes a partir de formas. Aplican un elemento estructurante a una imagen de entrada y generan una imagen de salida.
Las operaciones morfológicas más básicas son dos: Erosión y Dilatación
Fundamentos de la Erosión:
- Erosiona los límites del objeto en primer plano
- Se utiliza para disminuir las características de una imagen.
Trabajo de erosión:
- Un núcleo (una array de tamaño impar (3,5,7) se convoluciona con la imagen.
- Un píxel en la imagen original (ya sea 1 o 0) se considerará 1 solo si todos los píxeles debajo del kernel son 1; de lo contrario, se erosiona (se vuelve a cero).
- Por lo tanto, todos los píxeles cercanos al límite se descartarán según el tamaño del kernel.
- Entonces, el grosor o el tamaño del objeto de primer plano disminuye o simplemente la región blanca disminuye en la imagen.
Fundamentos de la dilatación:
- Aumenta el área del objeto.
- Se utiliza para acentuar las características.
Trabajo de dilatación:
- Un núcleo (una array de tamaño impar (3,5,7) se convoluciona con la imagen
- Un elemento de píxel en la imagen original es ‘1’ si al menos un píxel debajo del núcleo es ‘1’.
- Aumenta la región blanca en la imagen o aumenta el tamaño del objeto en primer plano
La segunda imagen es la forma erosionada de la imagen original y la tercera imagen es la forma dilatada.

Usos de la erosión y la dilatación:
- Erosión:
- Es útil para eliminar pequeños ruidos blancos.
- Se utiliza para separar dos objetos conectados, etc.
- Dilatación:
- En casos como la eliminación de ruido, la erosión es seguida por la dilatación. Porque la erosión elimina los ruidos blancos, pero también encoge nuestro objeto. Entonces lo dilatamos. Dado que el ruido se ha ido, no volverán, pero el área de nuestro objeto aumenta.
- También es útil para unir partes rotas de un objeto.
Este artículo es una contribución de Pratima Upadhyay . Si te gusta GeeksforGeeks y te gustaría contribuir, también puedes escribir un artículo usando write.geeksforgeeks.org o enviar tu artículo por correo a review-team@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Como todos sabemos, una mejor codificación conduce a un mejor modelo y la mayoría de los algoritmos no pueden manejar las variables categóricas a menos que se conviertan en un valor numérico.
Las características categóricas se dividen generalmente en 3 tipos:
A. Binario: Cualquiera/o
Ejemplos:
- Sí No
- Verdadero Falso
B. Ordinal: Grupos ordenados específicos.
Ejemplos:
- bajo medio alto
- frío, caliente, lava caliente
C. Nominal: Grupos No Ordenados. Ejemplos
- gato, perro, tigre
- pizza, hamburguesa, coca cola
Conjunto de datos: para descargar el archivo, haga clic en el conjunto de datos de codificación del enlace
Ejemplo:
Producción:
conjunto de datos
Examinemos las columnas del conjunto de datos con diferentes tipos de técnicas de codificación.
Código: mapeo de características binarias presentes en el conjunto de datos.
Producción:
Bin_1 después de aplicar el mapeo
bin_2 después de aplicar el mapeo
Codificación de etiquetas: el algoritmo de codificación de etiquetas es bastante simple y considera un orden para la codificación, por lo tanto, puede usarse para codificar datos ordinales.
Código:
Producción:
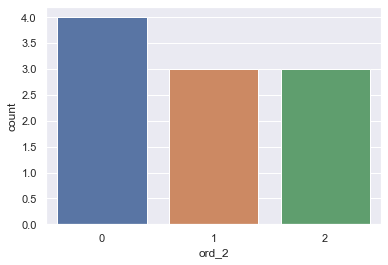
Gráfico de ord_2 después de la codificación de la etiqueta
Codificación One-Hot: para superar la desventaja de la codificación de etiquetas, ya que considera cierta jerarquía en las columnas que puede inducir a error a las características nominales presentes en los datos. podemos usar la estrategia One-Hot Encoding.
La codificación one-hot se procesa en 2 pasos:
- División de categorías en diferentes columnas.
- Ponga ‘0 para otros y ‘1’ como indicador para la columna apropiada.
Código: codificación One-Hot con la biblioteca Sklearn
Producción:
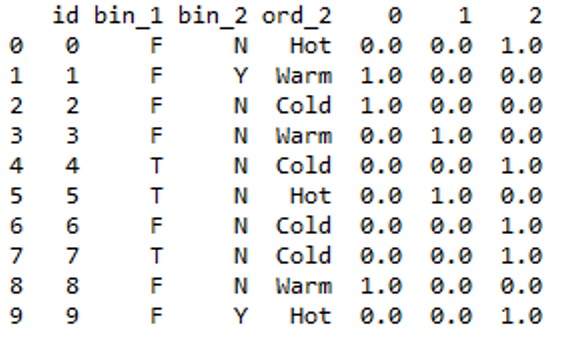
Producción
Código: codificación One-Hot con pandas
Producción:
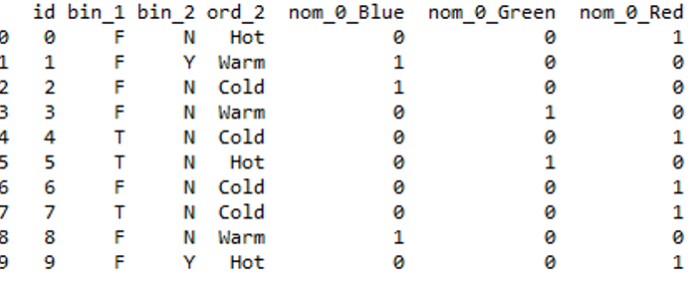
producción
Este método es preferible ya que da buenas etiquetas.
Nota: El enfoque de codificación one-hot elimina el orden, pero hace que la cantidad de columnas se expanda enormemente. Entonces, para columnas con más valores únicos, intente usar otras técnicas.
Codificación de frecuencia: También podemos codificar considerando la distribución de frecuencia. Este método puede ser efectivo a veces para características nominales.
Código:
Producción:
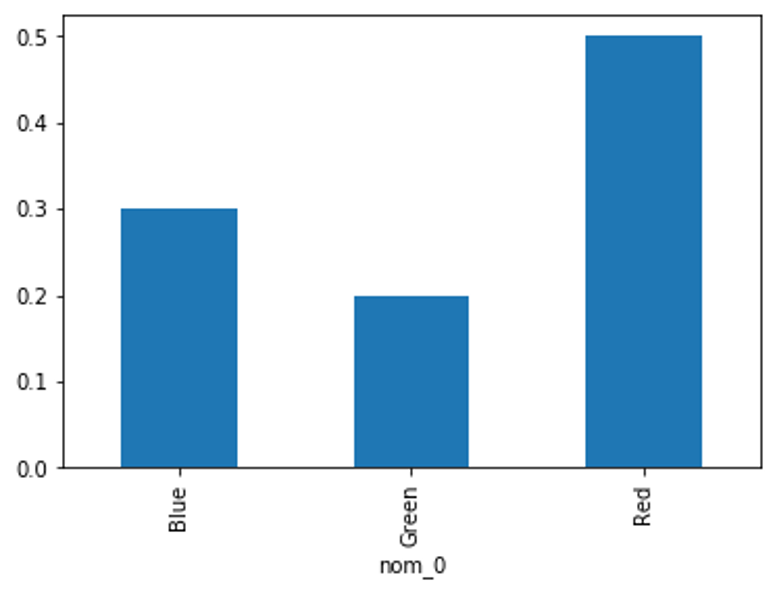
Distribución de frecuencias (fq)
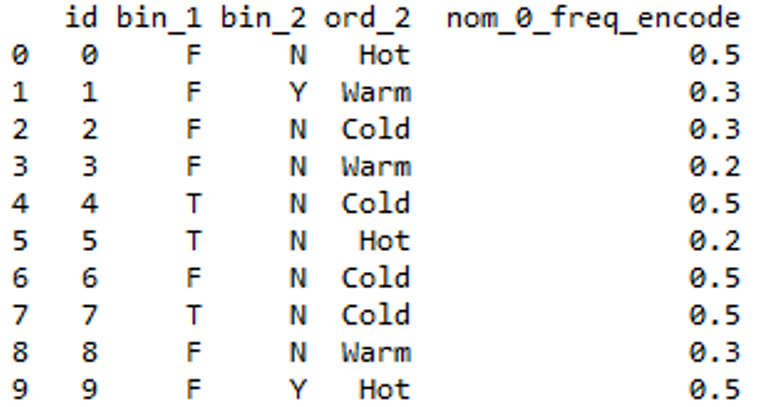
Producción
Codificación ordinal: podemos usar la codificación ordinal proporcionada en la clase de aprendizaje de Scikit para codificar características ordinales. Asegura que se mantenga la naturaleza ordinal de las variables.
Código: Uso de Scikit learn.
Producción:
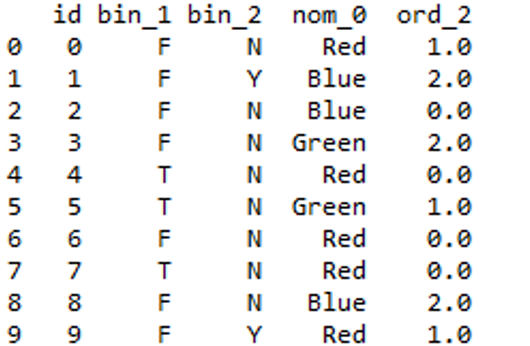
Producción
Un problema con esta representación (codificación ordinal) es que el algoritmo ML supondría que los dos valores cercanos están más cerca que los distintos.
Ejemplo del problema anterior:
Producción:
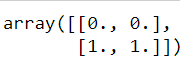
Está buscando los más cercanos. Asume que «rojo» y «verde» pertenecen a la misma categoría.
Código: asignación manual de clasificación mediante el uso de un diccionario
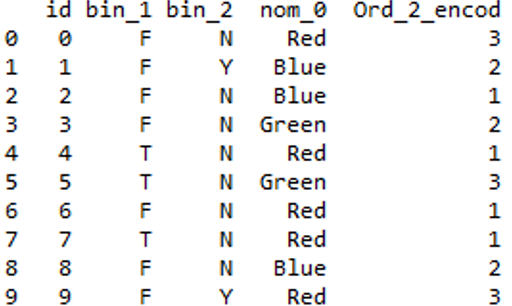
Producción
Codificación binaria: inicialmente, las categorías se codifican como enteros y luego se convierten en código binario, luego los dígitos de esa string binaria se colocan en columnas separadas.
Este método es bastante preferible cuando hay más categorías. Imagínese si tiene 100 categorías diferentes. Una codificación en caliente creará 100 columnas diferentes, pero la codificación binaria solo necesita 7 columnas.
Código:
Producción:
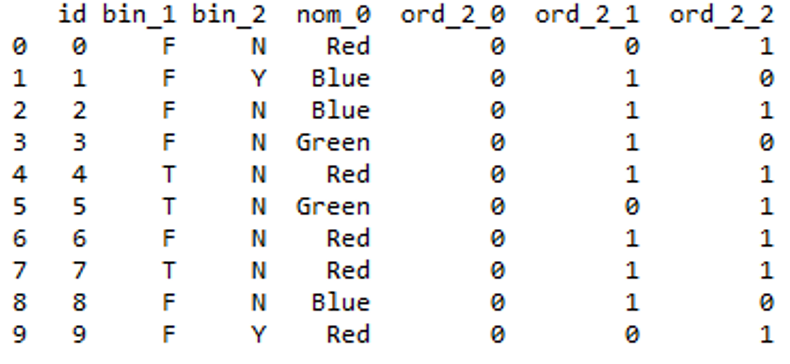
Producción
HashEncoding: Hashing es el proceso de convertir una string de caracteres en un valor hash único aplicando una función hash. Este proceso es bastante útil ya que puede manejar una mayor cantidad de datos categóricos y su bajo uso de memoria.
Artículo sobre hash
Código:
Producción:
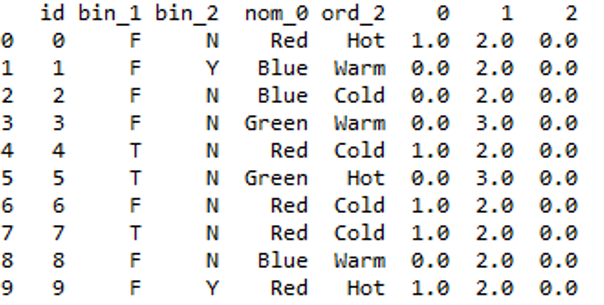
Producción
Puede eliminar aún más la función convertida de su marco de datos.
Codificación media/objetivo: la codificación objetivo es buena porque recoge valores que pueden explicar el objetivo. Es utilizado por la mayoría de los kagglers en sus competencias. La idea básica es reemplazar un valor categórico con la media de la variable objetivo.
Código:
Puede eliminar aún más la función convertida de su marco de datos.
Producción:
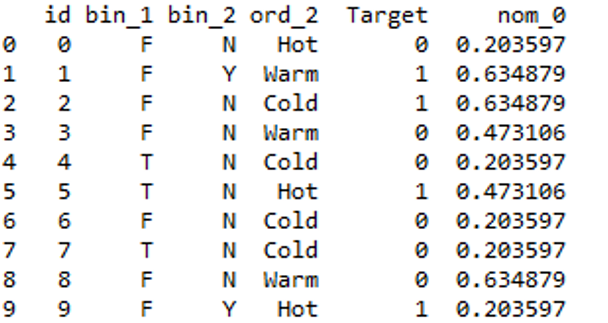
producción
Requisito previo: implementar la función de nube en Google Cloud Platform
¿Buscas datos para entrenar tu modelo en línea? ¿Qué pasa si le decimos que puede generar sus propios datos en solo unas pocas líneas de código?
Todo lo que necesita es una cuenta de Google Cloud Platform y saber cómo implementar un código simple en Cloud Function. Usaremos Hojas de cálculo de Google para almacenar los datos. Puede usar Cloud SQL o Google Cloud Storage Bucket o Firebase para almacenar los datos. Todo lo que necesita hacer es habilitar las API necesarias.
Habilitación de las API y creación de las credenciales:
- Vaya a Marketplace en Cloud Console.
- Haga clic en HABILITAR APIS Y SERVICIOS
- Luego busque la API de Google Drive y habilítela
- Luego vaya a la pestaña Credenciales en la barra de navegación izquierda en la pantalla.
- Luego haga clic en Crear credenciales y luego seleccione Clave de cuenta de servicio
- Luego cree una nueva cuenta de servicio dándole un nombre y establezca el Rol en Editor en el subcampo Proyectos y mantenga el tipo de clave como JSON y haga clic en el botón Crear. Mantenga el JSON descargado de forma segura.
- Vuelva a ir a Dashboard y siga los mismos pasos. Esta vez busque Hojas de cálculo de Google y habilite la API.
Después de realizar todos estos pasos, su página debería verse así

Crear la hoja de cálculo
- Crear una hoja de cálculo en Google Sheets
- Busque el archivo JSON descargado para el campo client_email y copie ese correo electrónico.
- Abra la hoja de cálculo recién creada y haga clic en la opción de compartir y escriba el correo electrónico del cliente allí.
Entonces, la parte aburrida está hecha. Ahora, saltemos al código.
Configuración de funciones en la nube
- Cree una nueva función en la nube y cambie el tiempo de ejecución a Python 3.7
- Vaya a requirements.txt y elimine el texto repetitivo y agréguele las siguientes líneas.
gspread>=3.1.0
oauth2client>=4.1.3 - Ahora lo más importante y lo mejor, escribir el código . Elimine todo el código repetitivo y pegue el siguiente código
importgspreadfromoauth2client.service_accountimportServiceAccountCredentialsfromdatetimeimportdatetimedefupdate(request):# getting the variables readydata={# your client_json contents as dictionary}request_json=request.get_json()request_args=request.argstemp=""ifrequest_jsonand'temp'inrequest_json:temp=request_json['temp']elifrequest_argsand'temp'inrequest_args:temp=request_args['temp']# use creds to create a client to interact with the Google Drive APIcreds=ServiceAccountCredentials.from_json_keyfile_dict(data, scope)client=gspread.authorize(creds)# Find a workbook by name and open the first sheet# Make sure you use the right name here.sheet=client.open("Temperature").sheet1row=[datetime.now().strftime("% d/% m/% Y % H:% M:% S"), temp]index=2sheet.insert_row(row, index)Código Explicación –
-> Primero, obtenemos las importaciones necesarias. gspread es la biblioteca para realizar el manejo de Google Sheets. Luego, estamos importando oauth2client . Esto manejará nuestra autenticación de las credenciales generadas. Luego, estamos importando fecha y hora para registrar los datos correctamente con la hora y fecha actuales.
-> Entrando en la actualización (solicitud) , primero agregamos nuestras credenciales en el diccionario de datos . Luego, almacenamos los parámetros de solicitud del usuario en una variable llamada request_json y luego inicializamos temp y luego asignamos el valor clave ‘temp’ a la variable.
-> Estamos definiendo nuestro alcance para la autenticación. Estamos utilizando oauth2client para realizar la autenticación necesaria con los ámbitos especificados.
Luego, abra su hoja de cálculo de Google especificando el nombre de su hoja allí. Luego, estamos insertando la fecha y hora de registro y el parámetro en la hoja en la fila especificada en la variable de índice . - Ahora escriba actualizar en la Función para ejecutar y luego haga clic en ddeploy
Después de eso, su página de Cloud Function debería verse así 
. Después de esto, debe hacer clic en el nombre de la función, aquí function-1
. Luego, vaya a la pestaña de activación
. Después de eso, observe la URL que se muestra allí. Esta es la URL a la que enviará la solicitud GET junto con el parámetro de datos para agregar el valor del parámetro a la hoja de cálculo.
Configuración del dispositivo IoT
Puede usar Nodemcu o Arduino para enviar los datos a Hojas de cálculo de Google, pero necesitará un módulo WiFi junto con él y, por supuesto, también se puede usar Raspberry Pi. Ahora, todo lo que tiene que hacer es enviar una solicitud http a la URL de la función de nube junto con los parámetros, aquí temp o temperatura. Esto editaría la hoja de cálculo y agregaría los valores de los parámetros a la hoja de cálculo.
Dicho esto, así es como puede usar Cloud Functions para registrar datos en Hojas de cálculo de Google. Puede hacer lo mismo para Cloud SQL o cualquier otro medio de almacenamiento. Los datos almacenados se pueden usar como datos de entrenamiento para su modelo de aprendizaje automático relevante.
Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
Pandas Series.agg()se usa para pasar una función o una lista de funciones que se aplicarán a una serie o incluso a cada elemento de la serie por separado. En el caso de una lista de funciones, se devuelven múltiples resultados por agg()método.
Sintaxis: Series.agg(func, eje=0)
Parámetros:
func: Función, lista de funciones o string de nombre de función a llamar en Serie.
eje: 0 o ‘índice’ para el funcionamiento por filas y 1 o ‘columnas’ para el funcionamiento por columnas.Tipo de devolución: el tipo de devolución depende del tipo de devolución de la función pasada como parámetro.
Ejemplo #1:
En este ejemplo, se pasa una función lambda que simplemente suma 2 a cada valor de la serie. Dado que la función se aplicará a cada valor de serie, el tipo de retorno también es serie. Se genera una serie aleatoria de 10 elementos pasando una array generada utilizando el método aleatorio Numpy.
Salida:
como se muestra en la salida, la función se aplicó a cada valor y se agregó 2 a cada valor de la serie.
Ejemplo #2: Pasar lista de funciones
En este ejemplo, se pasa una lista de algunas funciones predeterminadas de Python y se devuelven múltiples resultados por agg()método en múltiples variables.
Salida:
como se muestra en la salida, se devolvieron varios resultados. Min, Max y la array ordenada se devolvieron en diferentes variables resultado1, resultado2, resultado3 respectivamente.
En este estilo de vida moderno, el combustible se ha convertido en una necesidad para todos los seres humanos. Es una base para nuestro estilo de vida. Entonces, vamos a escribir un script para rastrear su precio usando Python.
Módulos necesarios
- bs4: Beautiful Soup (bs4) es una biblioteca de Python para extraer datos de archivos HTML y XML. Este módulo no viene integrado con Python. Para instalar este tipo, escriba el siguiente comando en la terminal.
- requests: Solicitud le permite enviar requests HTTP/1.1 de forma extremadamente sencilla. Este módulo tampoco viene integrado con Python. Para instalar este tipo, escriba el siguiente comando en la terminal.
Veamos la ejecución paso a paso del script.
Paso 1: importar todas las dependencias
Paso 2: Cree una función de obtención de URL
Paso 3: ahora pase la URL a la función getdata() y convierta esos datos en código HTML
Producción :
[<div class=”gold_silver_table”> <table border=”0″ cellpadding=”1″ cellpacing=”1″ width=”100%”> <tr class=”first”> <td class=”heading” width= ”200″>Ciudad</td> <td class=”heading” width=”200″>Precio de hoy</td> <td class=”heading” width=”200″>Precio de ayer</td> </tr > <tr class=”even_row”> <td><a href=”/precio-de-la-gasolina-en-nueva-delhi.html” title=”Nueva Delhi”>Nueva Delhi</a></td> <td> ₹ 82,08</td> <td> ₹ 82,03</td> </tr> <tr class=”odd_row”> <td><a href=”/precio-de-la-gasolina-en-calcuta.html” title=”Calcuta ”>Calcuta</a></td> <td> ₹ 83,57</td> <td> ₹ 83,52</td> </tr> <tr class=”even_row”> <td><a href=”/ precio-de-la-gasolina-en-mumbai.html” title=”Mumbai”>Mumbai</a></td><td> ₹ 88,73</td> <td> ₹ 88,68</td> </tr> <tr class=”odd_row”> <td><a href=”/precio-de-la-gasolina-en-chennai.html” title =»Chennai»>Chennai</a></td> <td> ₹ 85,04</td> <td> ₹ 85,00</td> </tr> <tr class=»even_row»> <td><a href =»/precio-de-la-gasolina-en-gurgaon.html» title=»Gurgaon»>Gurgaon</a></td> <td> ₹ 79,92</td> <td> ₹ 79,84</td> </tr> <tr class=”odd_row”> <td><a href=”/precio-de-la-gasolina-en-noida.html” title=”Noida”>Noida</a></td> <td> ₹ 82,23</td > <td> ₹ 82,30</td> </tr> <tr class=”even_row”> <td><a href=”/precio-de-la-gasolina-en-bangalore.html” title=”Bangalore”>Bangalore</ a></td> <td> $84,75</td> <td> $84,70</td> </tr> <tr class=”odd_row”> <td><a href=”/precio-de-la-gasolina-en-bhubaneswar.html” title=”Bhubaneswar”>Bhubaneswar</a></td> < td> ₹ 82,47</td> <td> ₹ 82,59</td> </tr> <tr class=”even_row”> <td><a href=”/precio-de-la-gasolina-en-chandigarh.html” title= ”Chandigarh”>Chandigarh</a></td> <td> ₹ 78,96</td> <td> ₹ 78,92</td> </tr> <tr class=”odd_row”> <td><a href= ”/precio-de-la-gasolina-en-hyderabad.html” title=”Hyderabad”>Hyderabad</a></td> <td> ₹ 85,30</td> <td> ₹ 85,25</td> </tr> < tr class=”even_row”> <td><a href=”/precio-de-la-gasolina-en-jaipur.html” title=”Jaipur”>Jaipur</a></td> <td> ₹ 90,08</td> <td> ₹ 89,24</td> </tr> <tr class=”odd_row”> <td><a href=”/precio-de-la-gasolina-en-lucknow.html” title=”Lucknow”>Lucknow</a></td> <td> ₹ 82,20</td> <td> ₹ 82,09</td> </tr> <tr class=”even_row”> <td><a href=”/precio-de-la-gasolina-en-patna.html” title=”Patna”>Patna</a ></td> <td> ₹ 84,73</td> <td> ₹ 84,88</td> </tr> <tr class=”odd_row”> <td><a href=”/precio-de-gasolina-en- trivandrum.html” title=”Trivandrum”>Trivandrum</a></td> <td> ₹ 83,91</td> <td> ₹ 84,03</td> </tr> </table> </div>]a href=”/precio-de-la-gasolina-en-patna.html” title=”Patna”>Patna</a></td> <td> ₹ 84,73</td> <td> ₹ 84,88</td> </ tr> <tr class=”odd_row”> <td><a href=”/precio-de-la-gasolina-en-trivandrum.html” title=”Trivandrum”>Trivandrum</a></td> <td> ₹ 83,91< /td> <td> $84,03</td> </tr> </tabla> </div>]a href=”/precio-de-la-gasolina-en-patna.html” title=”Patna”>Patna</a></td> <td> ₹ 84,73</td> <td> ₹ 84,88</td> </ tr> <tr class=”odd_row”> <td><a href=”/precio-de-la-gasolina-en-trivandrum.html” title=”Trivandrum”>Trivandrum</a></td> <td> ₹ 83,91< /td> <td> $84,03</td> </tr> </tabla> </div>]
Nota: estos scripts le darán solo datos sin procesar en formato de string que tiene que imprimir sus datos con sus necesidades.
Paso 4: Ahora, busque los datos que necesita en Sting con soup.find_all().
Producción :

Paso 4: Cree un DataFrame para mostrar su resultado.
Código completo:
Producción :

El atributo de string lo proporciona Beautiful Soup, que es un marco de web scraping para Python. El raspado web es el proceso de extracción de datos del sitio web utilizando herramientas automatizadas para acelerar el proceso. Si una etiqueta tiene solo un elemento secundario, y ese elemento secundario es NavigableString , se puede acceder al elemento secundario mediante .string .
Prerrequisito: Hermosa Instalación de Sopa .
Sintaxis:
Los siguientes ejemplos explican el concepto de string en Beautiful Soup.
Ejemplo 1: En este ejemplo, vamos a obtener la string.
Producción:
Ejemplo 2: En este ejemplo, vamos a obtener el tipo de string.
Producción:
Dado un diccionario, pruebe si se incrementa, es decir, su clave y valores aumentan en 1.
Entrada : test_dict = {1:2, 3:4, 5:6, 7:8}
Salida : Verdadero
Explicación : Todas las claves y valores en orden difieren en 1.
Entrada : test_dict = {1:2, 3:10, 5:6, 7:8}
Salida : Falso
Explicación : Elementos irregulares.
Método: uso de elements() + bucle + extender() + comprensión de lista
En esto, el primer paso es hacer que el diccionario muestre la conversión usando items() + list comprehension y extend() , el siguiente ciclo se usa para probar si la lista convertida es incremental.
Producción:
En este artículo veremos cómo podemos cambiar el estilo del borde a la parte de edición de línea del cuadro combinado, la edición de línea es la parte del cuadro combinado que muestra el elemento seleccionado, es editable por naturaleza. setLineEditPara configurar y acceder al objeto de edición de línea , usamos un lineEditmétodo respectivamente.
Nota: Cuando creamos un objeto de edición de línea, hace que el cuadro combinado sea editable.
Para poder hacer esto tenemos que hacer lo siguiente:
1. Cree un cuadro combinado
2. Agregue un elemento al cuadro combinado
3. Cree un objeto QLineEdit
4. Establezca el borde del objeto QLineEdit
5. Agregue un estilo de borde
6. Agregue el objeto QLineEdit al cuadro combinado
Sintaxis:
A continuación se muestra la implementación.
Producción :
El conjunto de datos es una colección de atributos y filas. El conjunto de datos puede tener datos faltantes que están representados por NA en Python y en este artículo, vamos a reemplazar los valores faltantes en este artículo
Consideramos este conjunto de datos: Conjunto de datos
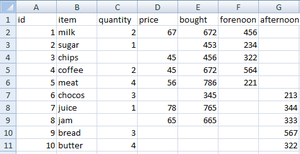
conjunto de datos
En nuestros datos contiene valores faltantes en las columnas cantidad, precio, comprado, mañana y tarde,
Entonces, podemos reemplazar los valores que faltan en la columna de cantidad con la media, la columna de precio con una mediana, la columna Comprada con desviación estándar. Columna de la mañana con el valor mínimo en esa columna. Columna de la tarde con valor máximo en esa columna.
Acercarse:
- Importar el módulo
- Cargar conjunto de datos
- Completa los valores que faltan
- Verificar conjunto de datos
Sintaxis:
Media: datos=datos.fillna(datos.mean())
Mediana: datos=datos.fillna(datos.mediana())
Desviación estándar: data=data.fillna(data.std())
Min: datos=datos.fillna(datos.min())
Máx.: datos=datos.fillna(datos.max())
A continuación se muestra la implementación:
Producción:
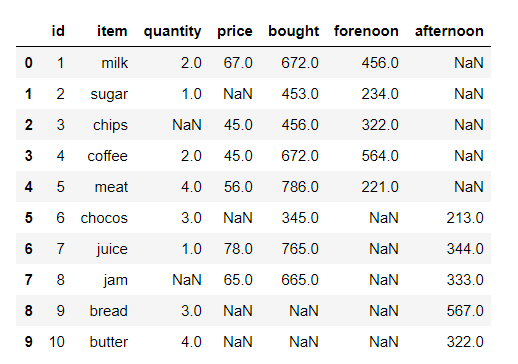
Luego, procederemos a reemplazar los valores faltantes con la media, la mediana, la moda, la desviación estándar, el mínimo y el máximo.
Producción:
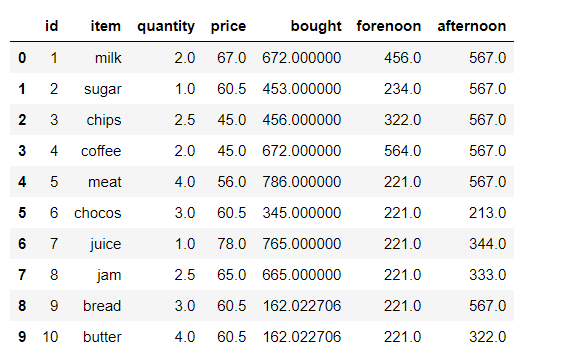
Ambos son efectivos, con Django dependiendo de Python y Laravel dependiendo de PHP y tomando un paquete de otro sistema efectivo: Symfony. Esperando que al cliente no le importe qué idioma o sistema utilizamos, permítanme comparar los dos: Laravel no brinda un backend por defecto, pero Django sí. Entonces, en el caso de que un cliente necesite un sitio en línea con un backend, Django gana, ya que su backend podría ser un poco menos complejo que el de Joomla o WordPress, pero aún así es muy bueno. Por supuesto, podemos programar continuamente un backend para Laravel, pero Django tiene uno por defecto. Django y Laravel te permiten formar tablas de bases de datos utilizando modelos. Con Django, el marco demostrado le permite asociarse con la base de datos sin utilizar demasiado lenguaje SQL, en caso de que lo haga. Esto puede ser una ventaja para los ingenieros de software reconocibles con Django. Pero también puede ser un inconveniente.
Django
Django es un sistema basado en Python que permite a los diseñadores utilizar un enfoque ordenado para el control de desarrollo. Django viene profundamente sugerido por los ingenieros de software, y se parece al MVT o al método Demostrar Ver Formato, restringido a Laravel. La curva de aprendizaje para Python es esencialmente inexistente. Por lo tanto, es sencillo y muy simple utilizar Django. Transmites tu aplicación en un entorno totalmente amenazante, donde los clientes, bots y programadores malévolos están esperando para comerse tus brechas de seguridad. La seguridad en Django puede ser un problema real y hace que los ingenieros eviten los errores comunes que generalmente los atormentan en el desarrollo de aplicaciones web. Django puede ser un sistema para construir aplicaciones web, un punto muerto. Brinda un conjunto de componentes bien probados que cubren casos de uso común (por ejemplo, confirmación del cliente o traer registros de una base de datos y convertirlos en objetos para que los maneje su lógica). Django sugiere de manera verificable una determinada forma de crear su aplicación web (para el caso, su página de inicio, la página de detalles de su cliente, etc.), por lo general, un caso en el que algunas limitaciones de las mejores prácticas evitan que el código se vuelva ruidoso, como suele ser el caso. con PHP, para el caso. En Django, hay algunos lugares claramente «correctos» para hacer ciertas cosas, lo que hace que sea esencialmente menos exigente para los compañeros de trabajo obtener su código y ampliar la estructura. Django sugiere de manera verificable una determinada forma de crear su aplicación web (para el caso, su página de inicio, la página de detalles de su cliente, etc.), por lo general, un caso en el que algunas limitaciones de las mejores prácticas evitan que el código se vuelva ruidoso, como suele ser el caso. con PHP, para el caso. En Django, hay algunos lugares claramente «correctos» para hacer ciertas cosas, lo que hace que sea esencialmente menos exigente para los compañeros de trabajo obtener su código y ampliar la estructura. Django sugiere de manera verificable una cierta forma de construir su aplicación web (para el caso, su página de inicio, la página de detalles de su cliente, etc.), típicamente un caso en el que un poco de limitaciones de las mejores prácticas evita que el código se vuelva ruidoso, como suele ser el caso. con PHP, para el caso. En Django, hay algunos lugares claramente «correctos» para hacer ciertas cosas, lo que hace que sea esencialmente menos exigente para los compañeros de trabajo obtener su código y ampliar la estructura.
Las características clave de Django incluyen
- Excelente documentación : Django brinda excelente documentación y sus informes están continuamente actualizados por los ingenieros de Django. llegó a ser de código abierto en 2005 hasta la fecha de presentación, y la documentación está mejorando con la mejora dinámica de la innovación y, además, se anuncia en diferentes idiomas
- Utiliza SEO : Django aclara ese concepto al mantener el sitio a través de URL en lugar de las direcciones IP en el servidor, lo que facilita que los ingenieros de SEO incluyan el sitio en el servidor mientras que el desarrollador web no tiene que cambiar el URL en unos pocos códigos numéricos.
- Enorme biblioteca de paquetes : la comunidad de Django es excepcionalmente grande y sólida, le brindan paquetes para casi todo lo que necesita en el sitio web y hará que los marcos de administración estén de acuerdo con usted de manera excepcionalmente efectiva.
Laravel
laravel puede ser un sistema PHP, gratuito y de código abierto que permite a los ingenieros utilizar el diseño de MVC para necesidades de mejora. Laravel sigue el enfoque de programación orientada a objetos o OOP y el enfoque de controlador de vista de modelo o MVC. Laravel es excepcionalmente natural y te permitirá dominar el desarrollo PHP de vanguardia con movimientos de bases de datos, Smooth ORM Composer, paquetes, REST, plantillas, etc.
Las características clave de Laravel incluyen
- Enrutamiento : La forma de dirección más sencilla de administrar y teórica. Hace que todo esté libre de molestias y la deliberación dada elimina todas y cada una de las complejidades.
- Soporte ORM elocuente : Otro beneficio dado a la parte única e informatizada de la pantalla. Conexiones y mapeo de la base de datos con nuestra aplicación con una tradición sencilla sobre la técnica de arreglo
- Gestión de colas : para identificar las tareas superfluas y alinearlas detrás de escena y hacer que el tiempo de reacción del cliente sea mucho más rápido.
Diferencia entre Django y Laravel
| Django | Laravel |
|---|---|
| Podría ser un sistema de aplicación web Full Stack compuesto en Python | Podría ser un sistema de aplicación web Full Stack compuesto en PHP |
| Es mantenido por Django Software Foundation | Está siendo mantenido por el propio ingeniero y su comunidad bajo el permiso del MIT. |
| Tiene un punto culminante de mejora rápida con una increíble reunión de clientes de la comunidad. | Tiene un diseño limpio y una base comunitaria en desarrollo. |
| Soporta alta escalabilidad | Laravel también sustenta una gran versatilidad, pero el contraste es el lenguaje utilizado para escribir en el sistema. |
| Existen algunos otros marcos para Python | El marco por así decirlo a considerar para PHP |
| Modelo de plantilla de vista de modelo (MVT) | Modelo de controlador de vista de modelo (MVC) |
Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos. La función pandas dataframe.get_value() se utiliza para recuperar rápidamente el valor único en el marco de datos en la columna y el índice pasados. La entrada a la función es la etiqueta de la fila y la etiqueta de la columna.
Sintaxis:
Parámetros:
- índice: etiqueta de fila
- col : etiqueta de la columna
- Takeable: interpreta el índice/col como indexadores, predeterminado Falso
Devuelve: valor: valor escalar
Para obtener un enlace al archivo CSV utilizado en el código, haga clic aquí
Ejemplo #1: Use la función get_value() para encontrar el valor del salario en la décima fila
Producción:
Ejemplo #2: Use la función get_value() y pase el valor del índice de columna en lugar del nombre. Nota: También podemos usar el valor del indexador entero de las columnas configurando el parámetro Takeable = True.
Producción:

Python 3.8 todavía está en desarrollo. Pero se han lanzado muchas versiones alfa. Una de las últimas funciones de Python 3.8 es el Operador Walrus. En este artículo, discutiremos el operador Walrus y lo explicaremos con un ejemplo.
Introducción
Walrus-operator es otro nombre para las expresiones de asignación. De acuerdo con la documentación oficial, es una forma de asignar variables dentro de una expresión usando la notación NOMBRE := expr. Las expresiones de asignación permiten asignar un valor a una variable, incluso a una variable que aún no existe, en el contexto de la expresión en lugar de como una declaración independiente.
Código:
Producción :
Aquí, en lugar de usar «len(a)» en dos lugares, lo hemos asignado a una variable llamada «n», que se puede usar más adelante. Esto nos ayuda a resolver la duplicación de código y mejora la legibilidad.
Ejemplo –
Tratemos de entender las expresiones de asignación más claramente con la ayuda de un ejemplo que usa Python 3.7 y Python 3.8. Aquí tenemos una lista de diccionarios llamada “sample_data”, que contiene el ID de usuario, el nombre y un booleano llamado completado.
Producción: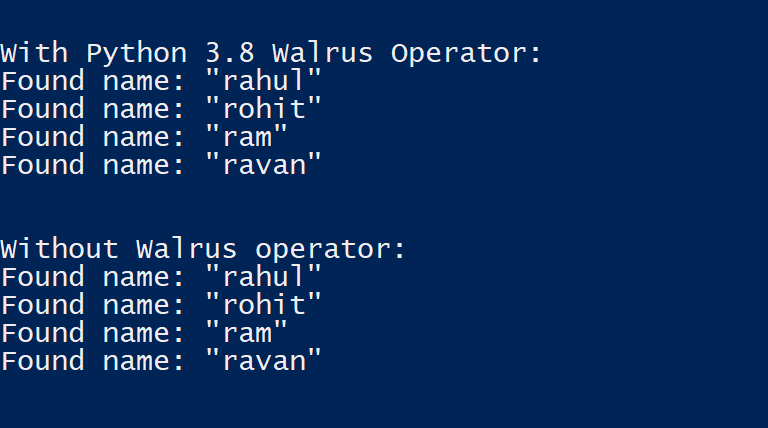
Tkinter es un conjunto de herramientas de GUI utilizado en Python para crear GUI fáciles de usar. Tkinter es el marco de GUI más utilizado y más básico disponible en Python. Tkinter utiliza un enfoque orientado a objetos para crear GUI.
Nota: Para obtener más información, consulte Python GUI – tkinter
Widget de nivel superior
Se utiliza un widget de nivel superior para crear una ventana encima de todas las demás ventanas. El widget de nivel superior se utiliza para proporcionar información adicional al usuario y también cuando nuestro programa trata con más de una aplicación. Estas ventanas están directamente organizadas y administradas por el Administrador de ventanas y no es necesario tener ninguna ventana principal asociada con ellas cada vez.
Sintaxis:
Parámetros opcionales
- root = ventana raíz (opcional)
- bg = color de fondo
- fg = color de primer plano
- bd = borde
- altura = altura del widget.
- ancho = ancho del widget.
- font = Tipo de fuente del texto.
- cursor = cursor que aparece en el widget que puede ser una flecha, un punto, etc.
Métodos comunes
- iconify convierte las ventanas en iconos.
- deiconify vuelve a convertir el icono en ventana.
- state devuelve el estado actual de la ventana.
- retirar elimina la ventana de la pantalla.
- title define el título de la ventana.
- frame devuelve un identificador de ventana que es específico del sistema.
Ejemplo 1:
Producción
Ejemplo 2: Creación de múltiples toplevels uno sobre el otro
Producción
Escribir código bien formateado es muy importante, los programas pequeños son fáciles de entender, pero a medida que los programas se vuelven más complejos, se vuelven más y más difíciles de entender. En algún momento, ni siquiera puedes entender el código escrito por ti. Para evitar esto, es necesario escribir el código en un formato legible. Aquí Black entra en juego, Black asegura la calidad del código.
¿Qué es el negro?
Linters como pycodestyle o flake8 muestran si su código está de acuerdo con el formato PEP8, que es la guía de estilo oficial de Python. Pero el problema es que les da una carga a los desarrolladores arreglar este estilo de formato. Aquí Black entra en juego no solo informa errores de formato sino que también los corrige.

Para citar el proyecto README:
Black es el formateador de código Python intransigente. Al usarlo, acepta ceder el control sobre las minucias del formateo manual. A cambio, Black le brinda velocidad, determinismo y libertad de las molestias de estilo pycode sobre el formato. Ahorrarás tiempo y energía mental para asuntos más importantes.
Nota: Black se puede integrar fácilmente con muchos editores como Vim, Emacs, VSCode, Atom o un sistema de control de versiones como GIT.
Instalación y uso de Black:
Black requiere Python 3.6.0+ con pip instalado:
Es muy simple de usar negro. Ejecute el siguiente comando en la terminal.
Esto reformateará su código usando el estilo de código Black.
Ejemplo 1: Vamos a crear un nombre de archivo sin formato «sample.py» y queremos formatearlo usando negro. A continuación se muestra la implementación.
Después de crear este archivo, ejecute el siguiente comando.
Archivo de salida:
En el ejemplo anterior, ambos son el mismo código de pieza, pero después de usar negro, se formatea y, por lo tanto, es fácil de entender.
Ejemplo 2: Vamos a crear otro archivo “sample1.py” que contenga el siguiente código.
Después de escribir el comando anterior nuevamente en la terminal.
Archivo de salida:
El módulo OS en Python proporciona varios métodos para interactuar con el sistema operativo. Viene bajo el módulo de utilidad estándar de Python, por lo que no es necesario instalarlo externamente. os.path es un submódulo del módulo OS que contiene algunas funciones útiles en los nombres de ruta. Los parámetros de ruta son strings o bytes. Estas funciones aquí se utilizan para diferentes propósitos, como fusionar, normalizar y recuperar nombres de rutas en Python.
De acuerdo con los documentos os.path.abspath(), devuelve una versión absolutizada normalizada de la ruta del nombre de la ruta, lo que puede sonar elegante, pero simplemente significa que este método devuelve el nombre de la ruta a la ruta pasada como parámetro a esta función.
Sintaxis: os.path.abspath(ruta)
Parámetro:
Ruta: un objeto similar a una ruta que representa una ruta del sistema de archivos.Tipo de devolución: este método devuelve una versión normalizada de la ruta del nombre de la ruta.
Ejemplo 1:
Producción:
Ejemplo 2: esta función también puede devolver la ruta normalizada después de cambiar el directorio de trabajo actual.
Producción:
El módulo de Turtle proporciona primitivos de gráficos de Turtle, tanto en formas orientadas a objetos como orientadas a procedimientos. Debido a que usa Tkinter para los gráficos subyacentes, necesita una versión de Python instalada con soporte Tk.
Turtle.escribir()
Esta función se usa para escribir texto en la posición actual de la Turtle.
Sintaxis:
Turtle.escribir(argumento, mover=Falso, alinear=’izquierda’, fuente=(‘Arial’, 8, ‘normal’))
Parámetros:
| Argumentos | Descripción |
| argumento | Información, que se escribirá en TurtleScreen |
| Muevete | Verdadero Falso |
| alinear | Una de las strings «izquierda», «centro» o derecha» |
| fuente | Una tupla (nombre de fuente, tamaño de fuente, tipo de fuente) |
A continuación se muestra la implementación del método anterior con algunos ejemplos:
Ejemplo 1 :
Producción :

Ejemplo 2:
Producción :

Ejemplo 3:
Producción :

Ejemplo 4:
Producción :

RGB y HSV, dos modelos de color de uso común se analizan en los artículos: RGB , HSV . En este artículo, presentamos los modelos de color CMY y CMYK.
El cian, el magenta y el amarillo son los colores secundarios de la luz y los colores primarios de los pigmentos. Esto significa que si se hace brillar luz blanca sobre una superficie cubierta con pigmento cian, no se reflejará luz roja. Cian resta la luz roja de la luz blanca. A diferencia del modelo de color RGB, CMY es sustractivo , lo que significa que los valores más altos se asocian con colores más oscuros en lugar de con colores más claros.
Los dispositivos que implementan pigmentos en papel de color u otras superficies utilizan el modelo de color CMY, por ejemplo, impresoras y fotocopiadoras. La conversión de RGB a CKY es una operación simple, como se ilustra en el programa de Python a continuación. Es importante que todos los valores de color se normalicen a [0, 1] antes de convertir.
A continuación se muestra el código para convertir el modelo de color RGB a CMY.
Producción:
De acuerdo con la rueda de colores que se muestra arriba, cantidades iguales de cian, magenta y amarillo deberían producir negro. Sin embargo, en la vida real, la combinación de estos pigmentos produce un color negro fangoso. Para producir el negro puro, que se usa con bastante frecuencia durante la impresión, agregamos un cuarto color, el negro, a la mezcla de pigmentos. Esto se llama impresión a cuatro colores . La adición de negro en este modelo hace que se le denomine modelo de color CMYK .
Hemos explorado Python básico hasta ahora desde el Conjunto 1 al 4 ( Conjunto 1 | Conjunto 2 | Conjunto 3 | Conjunto 4 ).
En este artículo, discutiremos cómo manejar excepciones en Python usando try. catch, y finalmente declaración con la ayuda de ejemplos apropiados.
El error en Python puede ser de dos tipos, es decir , errores de sintaxis y excepciones . Los errores son los problemas en un programa debido a que el programa detendrá la ejecución. Por otro lado, se generan excepciones cuando ocurren algunos eventos internos que cambian el flujo normal del programa.
Diferencia entre error de sintaxis y excepciones
Error de sintaxis: como sugiere el nombre, este error se debe a una sintaxis incorrecta en el código. Conduce a la terminación del programa.
Ejemplo:
Producción:

Excepciones: se generan excepciones cuando el programa es sintácticamente correcto, pero el código resultó en un error. Este error no detiene la ejecución del programa, sin embargo, cambia el flujo normal del programa.
Ejemplo:
Producción:

En el ejemplo anterior, se generó ZeroDivisionError ya que estamos tratando de dividir un número por 0.
Nota: Exception es la clase base para todas las excepciones en Python. Puede consultar la jerarquía de excepciones aquí .
Instrucción Try and Except: detección de excepciones
Las declaraciones Try y Except se utilizan para capturar y manejar excepciones en Python. Las declaraciones que pueden generar excepciones se mantienen dentro de la cláusula try y las declaraciones que manejan la excepción se escriben dentro de la cláusula excepto.
Ejemplo: Intentemos acceder al elemento de la array cuyo índice está fuera de límite y manejar la excepción correspondiente.
Second element = 2 An error occurred
En el ejemplo anterior, las declaraciones que pueden causar el error se colocan dentro de la declaración de prueba (segunda declaración de impresión en nuestro caso). La segunda declaración de impresión intenta acceder al cuarto elemento de la lista que no está allí y esto arroja una excepción. Luego, esta excepción es capturada por la declaración de excepción.
Captura de una excepción específica
Una declaración de prueba puede tener más de una cláusula excepto, para especificar controladores para diferentes excepciones. Tenga en cuenta que se ejecutará como máximo un controlador. Por ejemplo, podemos agregar IndexError en el código anterior. La sintaxis general para agregar excepciones específicas es:
Ejemplo: captura de una excepción específica en Python
ZeroDivisionError Occurred and Handled
Si comentas en la línea fun(3), la salida será
El resultado anterior es así porque tan pronto como Python intenta acceder al valor de b, se produce NameError.
Prueba con la cláusula Else
En python, también puede usar la cláusula else en el bloque try-except que debe estar presente después de todas las cláusulas excepto. El código ingresa al bloque else solo si la cláusula try no genera una excepción.
Ejemplo: prueba con la cláusula else
Producción:
Finalmente palabra clave en Python
Python proporciona una palabra clave finalmente , que siempre se ejecuta después de los bloques try y except. El bloque final siempre se ejecuta después de la finalización normal del bloque de prueba o después de que finaliza el bloque de prueba debido a alguna excepción.
Sintaxis:
Ejemplo:
Producción:
Excepción de generación
La declaración de aumento permite al programador forzar que ocurra una excepción específica. El único argumento de raise indica la excepción que se va a generar. Debe ser una instancia de excepción o una clase de excepción (una clase que se deriva de Exception).
La salida del código anterior simplemente se imprimirá como «Una excepción», pero también se producirá un error de tiempo de ejecución en el último debido a la declaración de aumento en la última línea. Entonces, la salida en su línea de comando se verá así
Este artículo es una contribución de Nikhil Kumar Singh (nickzuck_007)
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
QDateEdit es la clase que proporciona la información de la fecha, lo que permite al usuario ingresar la fecha. Permite al usuario editar fechas usando el teclado o las teclas de flecha para aumentar o disminuir la fecha. Es el widget más utilizado para obtener fechas de entrada. A continuación se muestra cómo se ve el widget de edición de fecha  Ejemplo: una ventana que tiene un QDateEdit y el usuario puede ingresar cualquier fecha en ella y cuando el usuario presiona Intro después de cambiar la fecha, la fecha ingresada se mostrará en la etiqueta A continuación se muestra la implementación
Ejemplo: una ventana que tiene un QDateEdit y el usuario puede ingresar cualquier fecha en ella y cuando el usuario presiona Intro después de cambiar la fecha, la fecha ingresada se mostrará en la etiqueta A continuación se muestra la implementación
Producción :
str() y repr() se usan para obtener una representación de string del objeto.
- Ejemplo de str():
s='Hello, Geeks.'print(str(s))print(str(2.0/11.0))Producción:
Hello, Geeks. 0.181818181818
- Ejemplo de repr():
s='Hello, Geeks.'print(repr(s))print(repr(2.0/11.0))Producción:
'Hello, Geeks.' 0.18181818181818182
.
De la salida anterior, podemos ver si imprimimos una string usando la función repr(), luego se imprime con un par de comillas y si calculamos un valor, obtenemos un valor más preciso que la función str().
Las siguientes son diferencias:
- str() se usa para crear resultados para el usuario final, mientras que repr() se usa principalmente para la depuración y el desarrollo. El objetivo de repr es ser inequívoco y el de str es ser legible . Por ejemplo, si sospechamos que un float tiene un pequeño error de redondeo, repr nos mostrará mientras que str no.
- repr() calcula la representación de string «oficial» de un objeto (una representación que tiene toda la información sobre el objeto) y str() se usa para calcular la representación de string «informal» de un objeto (una representación que es útil para imprimir el objeto).
- La declaración de impresión y la función integrada str() usan __str__ para mostrar la representación de string del objeto, mientras que la función integrada repr() usa __repr__ para mostrar el objeto.
Entendamos esto con un ejemplo: –
Producción:
str() muestra la fecha de hoy de manera que el usuario pueda entender la fecha y la hora.
repr() imprime la representación «oficial» de un objeto de fecha y hora (significa que usando la representación de string «oficial» podemos reconstruir el objeto).
¿Cómo hacer que funcionen para nuestras propias clases definidas?
Una clase definida por el usuario también debe tener un __repr__ si necesitamos información detallada para la depuración. Y si pensamos que sería útil tener una versión de string para los usuarios, creamos una función __str__.
Producción:
Este artículo es una contribución de Arpit Agarwal. Si le gusta GeeksforGeeks y le gustaría contribuir, también puede escribir un artículo y enviarlo por correo electrónico a contribuya@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
UwU se usa como emoticón para demostrar una reacción a algo lindo. En este emoticón, las ‘U’ significan 2 ojos cerrados y la ‘w’ significa los labios de la boca apretados y emocionados. Imagina ver algo lindo, como un bebé estornudando lindamente, la respuesta puede ser UwU, que se pronuncia como «ooh-wooh».
El texto UwU es el tipo de jerga en la que el texto original ha sido «UwUfied». Se supone que el texto UwU es una versión más linda del texto original. Es popular entre ciertas comunidades en línea, principalmente como una práctica divertida.
Ejemplos:
Algoritmo:
- Cambie todas las ‘R’s y ‘r’s a ‘w’ y ‘W’ respectivamente.
- Cambie todas las ‘L’s y ‘l’s a ‘w’ y ‘W’ respectivamente.
- Si el carácter actual es ‘o’ o ‘O’ y el carácter anterior es ‘M’, ‘m’, ‘N’ o ‘n’, agregue ‘y’ entre los caracteres.
- Si ninguna de las condiciones coincide con ningún carácter, déjelo como está.
Producción :
numpy.sum(arr, axis, dtype, out): esta función devuelve la suma de los elementos de la array sobre el eje especificado.
Parámetros:
arr: array de entrada.
eje : eje a lo largo del cual queremos calcular el valor de la suma. De lo contrario, considerará que arr está aplanado (funciona en todos los ejes). axis = 0 significa a lo largo de la columna y axis = 1 significa trabajar a lo largo de la fila.
out : Array diferente en el que queremos colocar el resultado. La array debe tener las mismas dimensiones que la salida esperada. El valor predeterminado es Ninguno.
initial : [escalar, opcional] Valor inicial de la suma.Retorno: suma de los elementos de la array (un valor escalar si el eje no es ninguno) o array con valores de suma a lo largo del eje especificado.
Código #1:
Producción:
Código #2:
Producción:
Código #3:
Producción:
La similitud del documento, como sugiere el nombre, determina qué tan similares son los dos documentos dados. Por «documentos», nos referimos a una colección de strings. Por ejemplo, un ensayo o un archivo .txt. Muchas organizaciones utilizan este principio de similitud de documentos para comprobar el plagio. También lo utilizan muchas instituciones que realizan exámenes para verificar si un estudiante hizo trampa al otro. Por lo tanto, es muy importante a la vez que interesante saber cómo funciona todo esto.
La similitud del documento se calcula calculando la distancia del documento. La distancia del documento es un concepto en el que las palabras (documentos) se tratan como vectores y se calcula como el ángulo entre dos vectores de documentos dados. Los vectores de documentos son la frecuencia de aparición de palabras en un documento dado. Veamos un ejemplo:
Digamos que nos dan dos documentos D1 y D2 como:
D1 : “Esto es un geek”
D2 : “Esto era una cosa de geek”
Las palabras similares en ambos documentos se convierten en:
Si hacemos una representación tridimensional de esto como vectores tomando D1, D2 y palabras similares en geometría de 3 ejes, entonces obtenemos:
Ahora, si tomamos el producto escalar de D1 y D2 ,
Ahora que sabemos cómo calcular el producto escalar de estos documentos, ahora podemos calcular el ángulo entre los vectores del documento:
Aquí d es la distancia del documento. Su valor oscila entre 0 y 90 grados. Donde 0 grados significa que los dos documentos son exactamente idénticos y 90 grados indican que los dos documentos son muy diferentes.
Ahora que sabemos acerca de la similitud y la distancia del documento, veamos un programa de Python para calcular lo mismo:
Programa de similitud de documentos:
Nuestro algoritmo para confirmar la similitud de los documentos constará de tres pasos fundamentales:
- Divide los documentos en palabras.
- Calcule las frecuencias de las palabras.
- Calcule el producto escalar de los vectores del documento.
Para el primer paso, primero usaremos el .read()método para abrir y leer el contenido de los archivos. A medida que leamos los contenidos, los dividiremos en una lista. A continuación, calcularemos la lista de frecuencia de palabras de la lectura en el archivo. Por lo tanto, se cuenta la aparición de cada palabra y la lista se ordena alfabéticamente.
Ahora que tenemos la lista de palabras, calcularemos la frecuencia de aparición de las palabras.
Por último, calcularemos el producto punto para dar la distancia del documento.
¡Eso es todo! Es hora de ver la función de similitud de documentos:
Aquí está el código fuente completo.
Producción:
Para leer la tabla sql en un DataFrame usando solo el nombre de la tabla, sin ejecutar ninguna consulta, usamos el read_sql_table()método en Pandas. Esta función no admite conexiones DBAPI.
leer_tabla_sql()
Sintaxis: pandas.read_sql_table(table_name, con, schema=Ninguno, index_col=Ninguno, coerce_float=True, parse_dates=Ninguno, columnas=Ninguno, chunksize=Ninguno)
Parámetros:
table_name: (str) Nombre de la tabla SQL en la base de datos.
con: SQLAlchemy conectable o str.
esquema: (str) Nombre del esquema SQL en la base de datos para consultar (si el tipo de base de datos lo admite). El valor predeterminado es Ninguno
index_col : Lista de string o string. Columna(s) para establecer como índice(MultiIndex). El valor predeterminado es Ninguno.
coerce_float : (bool) Intenta convertir valores de objetos no numéricos que no son strings (como decimal.Decimal) a punto flotante. El valor predeterminado es verdadero
parse_dates: (lista o dictado)
- Lista de nombres de columna para analizar como fechas.
- Dict of {column_name: format string} donde format string es compatible con strftime en caso de analizar tiempos de string o es uno de (D, s, ns, ms, us) en caso de analizar marcas de tiempo de enteros.
- Dict of {column_name: arg dict}, donde arg dict corresponde a los argumentos de palabras clave de pandas.to_datetime() Especialmente útil con bases de datos sin compatibilidad nativa con fecha y hora, como SQLite.
Columnas: lista de nombres de columna para seleccionar de la tabla SQL. El valor predeterminado es Ninguno
chunksize : (int) Si se especifica, devuelve un iterador donde chunksize es el número de filas que se incluirán en cada fragmento. El valor predeterminado es Ninguno.
Tipo de retorno: marco de datos
Ejemplo 1 :
Producción :
Ejemplo 2:
Producción :
Ejemplo 3:
Producción :
En PyQt5 hay muchos widgets y barras y cuando tendemos a hacer una aplicación, terminamos poniendo muchas ventanas y para cada ventana hay una barra de estado de salida. A veces no podemos recordar por qué se usa esta barra de estado y qué es esta barra de estado. Es por eso que, para fines de back-end, PyQt5 nos permite configurar el texto de ayuda. En este artículo veremos cómo configurar y acceder al texto de ayuda para la barra de estado.
Para configurar el texto de ayuda usamos setWhatsThis()el método y para acceder al texto de ayuda usamos el whatsThis()método.
Sintaxis:
self.statusBar().setWhatsThis() self.statusBar().whatsThis()Argumento:
setWhatsThis()toma una string como argumento.whatsThis()no acepta argumentos.Return :
setWhatsThis()return NingunowhatsThis()devuelve una string.
Código:
Producción :
Django es un marco de trabajo de alto nivel escrito en Python que nos permite crear aplicaciones web del lado del servidor. En este artículo, veremos cómo crear una aplicación de noticias usando Django.
Usaremos News Api y obtendremos todos los titulares de noticias de la API. Lea más sobre la api aquí news api .
Realice los siguientes pasos en el símbolo del sistema o terminal:

Abra la carpeta del proyecto de noticias con un editor de texto. La estructura del directorio debería verse así

Cree una carpeta de «plantillas» en su aplicación de noticias y en settings.py
Settings .py

En views.py:
en las vistas, creamos una vista llamada índice que toma una solicitud y muestra un html como respuesta. En primer lugar, importamos newsapi desde NewsApiClient.
Cree un index.html en la carpeta de plantillas .
Ahora asigne las vistas a urls.py
Su salida del proyecto debería verse así:
En los dos artículos anteriores ( Conjunto 2 y Conjunto 3 ), discutimos los conceptos básicos de python. En este artículo, aprenderemos más sobre python y sentiremos el poder de python.
Diccionario en Python
En python, el diccionario es similar al hash o mapas en otros idiomas. Se compone de pares clave-valor. Se puede acceder al valor mediante una clave única en el diccionario. (Antes de Python 3.7, el diccionario solía estar desordenado, lo que significaba que los pares clave-valor no se almacenaban en el orden en que se ingresaban en el diccionario, pero desde Python 3.7 se almacenan en el orden en que el primer elemento se almacenará en la primera posición y el último en la última posición.)
Producción:
romper, continuar, pasar en Python
- break: te saca del bucle actual.
- continuar: finaliza la iteración actual en el bucle y pasa a la siguiente iteración.
- pass: La instrucción pass no hace nada. Se puede utilizar cuando se requiere una declaración. sintácticamente pero el programa no requiere ninguna acción.
Se usa comúnmente para crear clases mínimas.
Producción:
mapa, filtrar, lambda
- map: La función map() aplica una función a cada miembro de iterable y devuelve el resultado. Si hay varios argumentos, map() devuelve una lista que consta de tuplas que contienen los elementos correspondientes de todos los iterables.
- filter: toma una función que devuelve True o False y la aplica a una secuencia, devolviendo una lista de solo aquellos miembros de la secuencia para los que la función devolvió True.
- lambda: Python proporciona la capacidad de crear una función en línea anónima simple (no se permiten declaraciones internamente) llamada función lambda. Usando lambda y map, puede tener dos bucles for en una línea.
Producción:
Para obtener más claridad sobre el mapa, el filtro y lambda, puede echar un vistazo al siguiente ejemplo:
Producción:
La misma operación se puede realizar en dos líneas usando map, filter y lambda como:
Producción:
Este artículo es una contribución de Nikhil Kumar Singh . Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
La forma completa de JSON es la notación de objetos Javascript. Significa que un archivo de secuencia de comandos (ejecutable) que está hecho de texto en un lenguaje de programación se utiliza para almacenar y transferir los datos. Python admite JSON a través de un paquete integrado llamado JSON . Para usar esta función, importamos el paquete JSON en el script de Python. El texto en JSON se realiza a través de una string entre comillas que contiene el valor en el mapeo de clave-valor dentro de { }. Es similar al diccionario en Python .
Escribir JSON en un archivo en Python
La serialización de JSON se refiere a la transformación de datos en una serie de bytes (por lo tanto, en serie) para ser almacenados o transmitidos a través de una red. Para manejar el flujo de datos en un archivo, la biblioteca JSON en Python utiliza la función de volcado() o volcados() para convertir los objetos de Python en su objeto JSON respectivo, por lo que facilita la escritura de datos en los archivos. Consulte la siguiente tabla que se proporciona a continuación.
| OBJETO PITÓN | OBJETO JSON |
|---|---|
| dictado | objeto |
| lista, tupla | formación |
| calle | cuerda |
| int, largo, flotante | números |
| Verdadero | verdadero |
| Falso | falso |
| Ninguna | nulo |
Método 1: escribir JSON en un archivo en Python usando json.dumps()
El paquete JSON en Python tiene una función llamada json.dumps() que ayuda a convertir un diccionario en un objeto JSON. Toma dos parámetros:
- diccionario: el nombre de un diccionario que debe convertirse en un objeto JSON.
- sangría – define el número de unidades para la sangría
Después de convertir el diccionario en un objeto JSON, simplemente escríbalo en un archivo usando la función «escribir».
Producción:

Método 2: escribir JSON en un archivo en Python usando json.dump()
Otra forma de escribir JSON en un archivo es usando el método json.dump(). El paquete JSON tiene la función de «volcado» que escribe directamente el diccionario en un archivo en forma de JSON, sin necesidad de convertirlo en un objeto JSON real. . Toma 2 parámetros:
- diccionario: el nombre de un diccionario que debe convertirse en un objeto JSON.
- Puntero de archivo: puntero del archivo abierto en modo escribir o agregar.
Producción:

Leer JSON desde un archivo usando Python
La deserialización es lo opuesto a la serialización, es decir, la conversión de objetos JSON en sus respectivos objetos de Python. Para ello se utiliza el método load(). Si usó datos JSON de otro programa o los obtuvo como un formato de string de JSON, puede deserializarse fácilmente con load(), que generalmente se usa para cargar desde una string; de lo contrario, el objeto raíz está en una lista o dictado
Leer JSON desde un archivo usando json.load()
El paquete JSON tiene la función json.load() que carga el contenido JSON de un archivo JSON en un diccionario. Toma un parámetro:
- Puntero de archivo: un puntero de archivo que apunta a un archivo JSON.
Producción:

En este artículo veremos cómo agregar una imagen de fondo al indicador presionado que inicialmente estaba en el estado marcado. Para hacer esto, tenemos que cambiar el código de la hoja de estilo asociado con el objeto de la casilla de verificación y agregar una imagen de fondo al indicador de estado marcado cuando se presiona.
A continuación se muestra el código de la hoja de estilo.
A continuación se muestra la implementación.
Producción :
Dada una lista de números, escriba un programa Python para imprimir todos los números positivos en la lista dada.
Ejemplo:
Ejemplo #1: Imprime todos los números positivos de la lista dada usando for loop
Itere cada elemento de la lista usando el bucle for y verifique si el número es mayor o igual a 0. Si la condición se cumple, solo imprima el número.
Producción:
Ejemplo #2: Usando el ciclo while
Producción:
Ejemplo #3: Uso de la comprensión de listas
Producción:
Ejemplo #4: Uso de expresiones lambda
Producción:
Muchas veces necesitamos combinar valores en diferentes columnas en una sola columna. Puede haber muchos casos de uso de esto, como combinar nombres y apellidos de personas en una lista, combinar día, mes y año en una sola columna de Fecha, etc. Ahora veremos cómo podemos lograr esto con la ayuda de algunos ejemplos.
Ejemplo 1: En este ejemplo, combinaremos dos columnas de nombre y apellido en un nombre de columna. Para lograr esto usaremos la función map.
Producción:
Ejemplo 2: Del mismo modo, podemos concatenar cualquier número de columnas en un marco de datos. Veamos otro ejemplo para concatenar tres columnas diferentes del día, mes y año en una sola columna Fecha.
Producción:
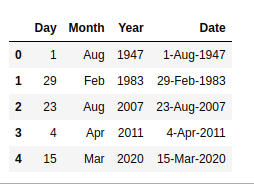
Ejemplo 3:
Podemos llevar este proceso más allá y concatenar varias columnas de varios marcos de datos diferentes. En este ejemplo, combinamos las columnas del marco de datos df1 y df2 en un solo marco de datos.
Producción:
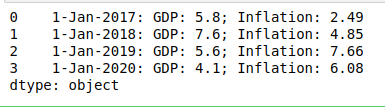
Las compensaciones de fecha son un tipo estándar de incremento de fecha utilizado para un rango de fechas en Pandas. Funciona exactamente como relativedelta en términos de los argumentos de palabra clave que pasamos. DateOffets funciona de la siguiente manera, cada compensación especifica un conjunto de fechas que se ajustan a DateOffset. Por ejemplo, Bday define este conjunto como el conjunto de fechas que son días laborables (MF).
Se pueden crear DateOffsets para adelantar fechas un número determinado de fechas válidas. Por ejemplo, se puede agregar Bday(2) a una fecha para adelantarla dos días hábiles. Si la fecha no comienza en una fecha válida, primero se mueve a una fecha válida y luego se crea una compensación.
El rollo de función de Pandas tseries.offsets.CustomBusinessDay.rollback()proporcionó la fecha hacia atrás hasta el siguiente desplazamiento solo si no está en el desplazamiento.
Sintaxis: pandas.tseries.offsets.CustomBusinessDay.rollback(dt)
Parámetro:
dt: fechaDevoluciones: retroceder si no está en compensación
Ejemplo n.º 1: use pandas.tseries.offsets.CustomBusinessDay.rollback()la función para revertir la marca de tiempo dada si no está compensada.
Producción :
Ahora agregaremos el desplazamiento al objeto de marca de tiempo dado para incrementar el valor de fecha y hora. También revertiremos la marca de tiempo dada si no está compensada.
Producción :

Como podemos ver en el resultado, hemos creado con éxito un desplazamiento y lo hemos agregado a la marca de tiempo dada. También hemos revertido la marca de tiempo dada, ya que no está compensada.
Ejemplo n.º 2: use pandas.tseries.offsets.CustomBusinessDay.rollback()la función para revertir la marca de tiempo dada si no está compensada.
Producción :
Ahora agregaremos el desplazamiento al objeto de marca de tiempo dado para incrementar el valor de fecha y hora. También revertiremos la marca de tiempo dada si no está compensada.
Producción :

Como podemos ver en el resultado, hemos creado con éxito un desplazamiento y lo hemos agregado a la marca de tiempo dada. También hemos revertido la marca de tiempo dada, ya que no está compensada.
Las listas de Python tienen varios métodos integrados para eliminar elementos de la lista. Aparte de estos, también podemos usar la instrucción del para eliminar un elemento de la lista especificando una posición. Veamos estos métodos:
Método 1: Uso de
la instrucción del La instrucción del no es una función de List. Los elementos de la lista se pueden eliminar utilizando la declaración del especificando el índice del elemento (elemento) que se eliminará.
Producción:
La lista original es: [‘Iris’, ‘Orchids’, ‘Rose’, ‘Lavender’, ‘Lily’, ‘Carnations’]
Después de eliminar el elemento: [‘Iris’, ‘Rose’, ‘Lavender’, ‘Lily’ , ‘Claveles’]
Método 2: Usar remove()
Podemos eliminar un elemento de la lista pasando el valor del elemento que se eliminará como parámetro para la función remove().
Producción:
La lista original es: [‘Iris’, ‘Orchids’, ‘Rose’, ‘Lavender’, ‘Lily’, ‘Carnations’]
Después de eliminar el elemento: [‘Iris’, ‘Rose’, ‘Lavender’, ‘Lily’ , ‘Claveles’]
Método 3: Usar pop()
pop() también es un método de lista. Podemos eliminar el elemento en el índice especificado y obtener el valor de ese elemento usando pop().
Producción –
La lista original es: [‘Iris’, ‘Orchids’, ‘Rose’, ‘Lavender’, ‘Lily’, ‘Carnations’]
Elemento reventado: Orchids
Después de eliminar el elemento: [‘Iris’, ‘Rose’, ‘Lavender’ , ‘Lirio’, ‘Claveles’]
shuffle() es un método incorporado del módulo aleatorio. Se utiliza para barajar una secuencia (lista). Barajar significa cambiar la posición de los elementos de la secuencia. Aquí, la operación de barajado está en su lugar.
aleatorio.shuffle()
Sintaxis: random.shuffle(secuencia, función)
Parámetros:
- secuencia: puede ser una lista
- función: opcional y por defecto es random(). Debe devolver un valor entre 0 y 1.
Devoluciones: nada
Ejemplo 1: barajar una lista
Producción :
El método shuffle() no se puede usar para mezclar tipos de datos inmutables como strings.
Ejemplo 2:
Producción :
En este artículo, veremos cómo podemos configurar la información sobre herramientas en el gráfico de barras en el módulo PyQtGraph. PyQtGraph es una biblioteca de interfaz de usuario y gráficos para Python que proporciona la funcionalidad comúnmente requerida en el diseño y las aplicaciones científicas. Sus objetivos principales son proporcionar gráficos rápidos e interactivos para mostrar datos (gráficos, videos, etc.) y, en segundo lugar, proporcionar herramientas para ayudar en el desarrollo rápido de aplicaciones (por ejemplo, árboles de propiedades como los que se usan en Qt Designer). Un gráfico de barras o gráfico de barras es una tabla o gráfico que presenta datos categóricos con barras rectangulares con alturas o longitudes proporcionales a los valores que representan. Las barras se pueden trazar vertical u horizontalmente. Un gráfico de barras verticales a veces se denomina gráfico de columnas. La información sobre herramientas, infotip, o sugerencia es un elemento común de la interfaz gráfica de usuario que se muestra como un cuadro de texto informativo al pasar el cursor sobre un elemento. El usuario pasa el puntero sobre un elemento, sin hacer clic en él, y una información sobre herramientas puede aparecer como un pequeño «cuadro flotante» con información sobre el elemento sobre el que se pasa el cursor.
Podemos crear una ventana de trazado y un gráfico de barras con la ayuda de los comandos que se indican a continuación.
Para hacer esto, usamos
setToolTipel método con el objeto de gráfico de barras .Sintaxis: bargraph.setToolTip(texto)
Argumento: toma una string como argumento
Retorno : Devuelve Ninguno
A continuación se muestra la implementación.
Producción :
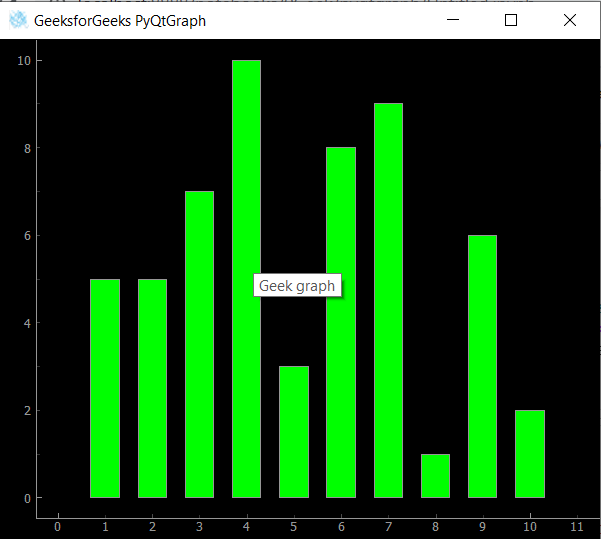
En Python3, string.punctuationes una string preiniciada que se usa como constante de string. En Python, string.punctuationdará todos los conjuntos de puntuación.
Sintaxis: string.puntuación
Parámetros: No toma ningún parámetro, ya que no es una función.
Devoluciones: Devuelve todos los conjuntos de puntuación.
Nota: asegúrese de importar la función de biblioteca de strings para usarstring.punctuation
Código #1:
Producción :
Código #2: Pruebas de código dadas para la puntuación.
Producción:
En este artículo, veremos cómo podemos eliminar una tupla vacía de una lista de tuplas dada. Encontraremos varias formas en las que podemos realizar esta tarea de eliminar tuplas usando varios métodos y formas en Python. Ejemplos:
Método 1: Usando el concepto de Comprensión de Listas
Producción:
Método 2: Usando el método filter() Usando el método incorporado filter() en Python, podemos filtrar los elementos vacíos pasando None como parámetro. Este método funciona tanto en Python 2 como en Python 3 y superior, pero el resultado deseado solo se muestra en Python 2 porque Python 3 devuelve un generador. filter() es más rápido que el método de comprensión de listas. Veamos qué sucede cuando ejecutamos el programa en Python 2.
Producción:
Ahora veamos qué sucede cuando intentamos ejecutar el programa en Python 3 y superior. Al ejecutar el programa en Python 3, como se mencionó, se devuelve un generador.
Producción:
Método #3: Usar el método len()
[('ram', '15', '8'), ('laxman', 'sita'), ('krishna', 'akbar', '45'), ('', '')]
Para proteger nuestro sistema del acceso de usuarios no autorizados, puede falsificar la dirección IP de nuestro sistema utilizando el servicio VPN proporcionado por diferentes organizaciones. Puede configurar una VPN en su sistema de forma gratuita.
Después de configurar e iniciar sesión en la VPN a través del sistema Ubuntu, debe conectarse manualmente con diferentes servidores VPN después de un tiempo. Podemos automatizarlo usando python para que automáticamente la dirección IP de nuestro sistema siga cambiando después de un tiempo para que nadie pueda rastrear nuestro sistema de todos modos. Hará que nuestro sistema esté más protegido.
Siga los pasos para automatizar VPN usando Python:
Paso 1: Abra su terminal (Ctrl+Alt+T) y cree un archivo usando gedit escribiendo el siguiente comando en la terminal.
Paso 2: importa los módulos de python en el archivo abierto.
Paso 3: cree una lista de códigos de servidor VPN gratuitos proporcionados por Windscribe (VPN).
Paso 4: Inicie un bloque de prueba, conéctese con Windscribe usando el módulo os
Y luego comience un bucle infinito y escriba algunas líneas debajo.
- Elija un código aleatorio de la lista de códigos utilizando el módulo random.
- Cree una suspensión aleatoria durante 15 a 20 minutos, después de lo cual se cambia la IP del sistema utilizando módulos aleatorios y de tiempo .
- Conéctese con el código VPN elegido al azar.
Paso 5: Inicie un bloque catch y luego:
- Desconecte la VPN, se ejecutará si recibe algún error.
- Mostrar un mensaje de desconexión aquí.
A continuación se muestra el código completo basado en el enfoque anterior:
Producción:
El proceso para ejecutar el programa de localización automática de VPN en python:
Paso 1: inicie sesión en Windscribe con el que configuró la VPN en el sistema con el comando que se indica a continuación.
Paso 2: Ejecute el archivo que ha creado en los pasos anteriores con el siguiente comando.
NOTA: Esto cambiará la dirección IP de su sistema aleatoriamente. Presione Ctrl+c para cerrar el servicio VPN.
Haga clic aquí para ver un pequeño video para una mejor comprensión de la configuración y ejecución del programa de automatización de VPN.
El tipo int implementa la clase base abstracta numbers.Integral.
1. int.bit_length()
Devuelve el número de bits necesarios para representar un número entero en binario, excluyendo el signo y los ceros iniciales.
Código para demostrar
3 3
2. int.to_bytes(longitud, orden de bytes, *, firmado = Falso)
Devuelve una array de bytes que representan un número entero. Si el orden de bytes es «grande», el byte más significativo está al comienzo de la array de bytes. Si byteorder es «pequeño», el byte más significativo está al final de la array de bytes. El argumento con signo determina si se usa el complemento a dos para representar el número entero.
b'\x04\x00'
3. int.from_bytes(bytes, orden de bytes, *, firmado=Falso)
Devuelve el número entero representado por la array de bytes dada.
16
El procesamiento del lenguaje natural (NLP) es un subcampo de la informática, la inteligencia artificial, la ingeniería de la información y la interacción humano-computadora. Este campo se enfoca en cómo programar computadoras para procesar y analizar grandes cantidades de datos de lenguaje natural. Es difícil de realizar ya que el proceso de lectura y comprensión de idiomas es mucho más complejo de lo que parece a primera vista.
La tokenización es el proceso de tokenizar o dividir una string, texto en una lista de tokens. Uno puede pensar en token como partes como una palabra es un token en una oración y una oración es un token en un párrafo.
Puntos clave del artículo –
- Texto en tokenización de oraciones
- Frases en palabras tokenización
- Oraciones que usan tokenización de expresiones regulares

Código n.º 1: tokenización de oraciones: división de oraciones en el párrafo
Producción :
¿Cómo sent_tokenize funciona?
La sent_tokenize función usa una instancia de PunktSentenceTokenizerfrom the nltk.tokenize.punkt module, que ya ha sido entrenada y, por lo tanto, sabe muy bien marcar el final y el comienzo de la oración en qué caracteres y puntuación.
Código #2: PunktSentenceTokenizer – Cuando tenemos grandes cantidades de datos, entonces es eficiente usarlos.
Producción :
Código n.º 3: tokenizar oraciones de diferentes idiomas: también se pueden tokenizar oraciones de diferentes idiomas utilizando un archivo pickle diferente al inglés.
Producción :
Código n.° 4: tokenización de palabras: división de palabras en una oración.
Producción :
¿Cómo funciona word_tokenize ? word_tokenize()La función es una función contenedora que llama a tokenize() en una instancia de TreebankWordTokenizer class.
Código #5: UsoTreebankWordTokenizer
Producción :
Estos tokenizadores funcionan separando las palabras mediante puntuación y espacios. Y como se mencionó en los resultados del código anteriores, no descarta la puntuación, lo que permite al usuario decidir qué hacer con la puntuación en el momento del preprocesamiento.
Código #6: PunktWordTokenizer– No separa la puntuación de las palabras.
Producción :
Código #6: WordPunctTokenizer– Separa la puntuación de las palabras.
Producción :
Código #7: Uso de expresiones regulares
Producción :
Código #7: Uso de expresiones regulares
Producción :
Este artículo es una introducción breve pero concisa al multiprocesamiento en el lenguaje de programación Python.
¿Qué es el multiprocesamiento?
El multiprocesamiento se refiere a la capacidad de un sistema para admitir más de un procesador al mismo tiempo. Las aplicaciones en un sistema de multiprocesamiento se dividen en rutinas más pequeñas que se ejecutan de forma independiente. El sistema operativo asigna estos hilos a los procesadores mejorando el rendimiento del sistema.
¿Por qué multiprocesamiento?
Considere un sistema informático con un solo procesador. Si se le asignan varios procesos al mismo tiempo, tendrá que interrumpir cada tarea y cambiar brevemente a otra para mantener todos los procesos en marcha.
Esta situación es como un chef que trabaja solo en una cocina. Tiene que hacer varias tareas como hornear, remover, amasar, etc.
Entonces, la esencia es que: Cuantas más tareas deba hacer a la vez, más difícil se vuelve hacer un seguimiento de todas ellas, y mantener el tiempo correcto se convierte en un desafío mayor.
¡Aquí es donde surge el concepto de multiprocesamiento!
Un sistema multiprocesador puede tener:
- multiprocesador, es decir, una computadora con más de un procesador central.
- Procesador multinúcleo, es decir, un solo componente informático con dos o más unidades de procesamiento reales independientes (llamadas «núcleos»).
Aquí, la CPU puede ejecutar fácilmente varias tareas a la vez, y cada tarea utiliza su propio procesador.
Es como el chef en la última situación siendo asistido por sus asistentes. Ahora, pueden dividir las tareas entre ellos y el chef no necesita cambiar entre sus tareas.
Multiprocesamiento en Python
En Python, el módulo de multiprocesamiento incluye una API muy simple e intuitiva para dividir el trabajo entre múltiples procesos.
Consideremos un ejemplo simple usando un módulo de multiprocesamiento:
Tratemos de entender el código anterior:
- Para importar el módulo de multiprocesamiento, hacemos:
import multiprocessing
- Para crear un proceso, creamos un objeto de la clase Proceso . Toma los siguientes argumentos:
- target : la función a ser ejecutada por el proceso
- args : los argumentos que se pasarán a la función de destino
Nota: El constructor de procesos también toma muchos otros argumentos que se discutirán más adelante. En el ejemplo anterior, creamos 2 procesos con diferentes funciones objetivo:
p1 = multiprocessing.Process(target=print_square, args=(10, )) p2 = multiprocessing.Process(target=print_cube, args=(10, ))
- Para iniciar un proceso, usamos el método de inicio de la clase Process .
p1.start() p2.start()
- Una vez que se inician los procesos, el programa actual también sigue ejecutándose. Para detener la ejecución del programa actual hasta que se complete un proceso, usamos el método de unión .
p1.join() p2.join()
Como resultado, el programa actual primero esperará a que se complete p1 y luego p2 . Una vez que se completan, se ejecutan las siguientes declaraciones del programa actual.
Consideremos otro programa para comprender el concepto de diferentes procesos que se ejecutan en el mismo script de python. En este ejemplo a continuación, imprimimos la ID de los procesos que ejecutan las funciones de destino:
- El script principal de Python tiene una ID de proceso diferente y el módulo de multiprocesamiento genera nuevos procesos con diferentes ID de proceso a medida que creamos los objetos Process p1 y p2 . En el programa anterior, usamos la función os.getpid() para obtener la ID del proceso que ejecuta la función de destino actual.
Observe que coincide con los ID de proceso de p1 y p2 que obtenemos usando el atributo pid de la clase Process .
- Cada proceso se ejecuta de forma independiente y tiene su propio espacio de memoria.
- Tan pronto como finaliza la ejecución de la función de destino, los procesos finalizan. En el programa anterior, usamos el método is_alive de la clase Process para verificar si un proceso aún está activo o no.
Considere el siguiente diagrama para comprender cómo los nuevos procesos son diferentes del script principal de Python: 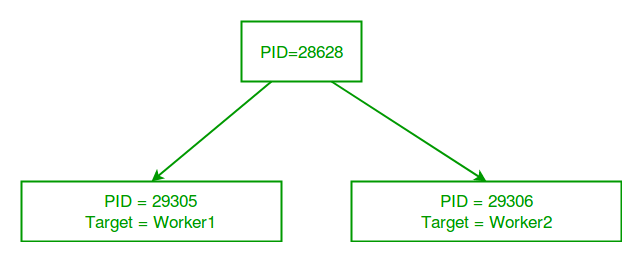
Por lo tanto, esta fue una breve introducción al multiprocesamiento en Python. Los siguientes artículos cubrirán los siguientes temas relacionados con el multiprocesamiento:
- Compartir datos entre procesos usando Array, valor y colas.
- Conceptos de Lock y Pool en multiprocesamiento
Próximo:
Referencias:
Este artículo es una contribución de Nikhil Kumar . Si le gusta GeeksforGeeks y le gustaría contribuir, también puede escribir un artículo usando contribuya.geeksforgeeks.org o envíe su artículo por correo a contribuya@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
En Django REST Framework, el concepto mismo de Serialización es convertir datos de base de datos a un tipo de datos que pueda ser utilizado por javascript. Cada serializador viene con algunos campos (entradas) que se van a procesar. Por ejemplo, si tiene una clase con el nombre Empleado y sus campos como Employee_id, Employee_name, is_admin, etc. Entonces, necesitará AutoField, CharField y BooleanField para almacenar y manipular datos a través de Django. De manera similar, el serializador también funciona con el mismo principio y tiene campos que se usan para crear un serializador.
Este artículo gira en torno a los campos de URL en serializadores en Django REST Framework. Hay dos campos principales: URLField y SlugField.
campo URL
URLField es básicamente un RegexField que valida la entrada contra un patrón de coincidencia de URL. Espera direcciones URL completas del formulario http:///. Funciona igual que URLField – Django Models
Tiene los siguientes argumentos –
- allow_blank : si se establece en True, la string vacía debe considerarse un valor válido. Si se establece en False, la string vacía se considera no válida y generará un error de validación. El valor predeterminado es falso.
Sintaxis –
campo de babosas
SlugField es un RegexField que valida la entrada contra el patrón [a-zA-Z0-9_-]+. Es lo mismo que SlugField – Django Models .
Sintaxis –
¿Cómo usar campos de URL en serializadores?
Para explicar el uso de los campos de URL, usemos la misma configuración de proyecto de: ¿Cómo crear una API básica usando Django Rest Framework? .
Ahora que tiene un archivo llamado serializadores en su proyecto, creemos un serializador con URLField y SlugField como campos.
Ahora vamos a crear algunos objetos e intentar serializarlos y verificar si realmente funcionan, Ejecutar, –
Ahora, ejecute los siguientes comandos de python en el shell
Aquí está el resultado de todas estas operaciones en la terminal:

Validación en campos de URL
Tenga en cuenta que el lema principal de estos campos es impartir validaciones, como URLField valida los datos solo para URL. Verifiquemos si estas validaciones funcionan o no:
Aquí está el resultado de estos comandos que muestra claramente que el correo electrónico y el número de teléfono no son válidos:

Conceptos avanzados
Las validaciones son parte de la deserialización y no de la serialización. Como se explicó anteriormente, la serialización es un proceso de conversión de datos ya creados en otro tipo de datos, por lo que no se requieren estas validaciones predeterminadas. La deserialización requiere validaciones ya que los datos deben guardarse en la base de datos o cualquier otra operación según lo especificado. Entonces, si serializa datos usando estos campos, eso funcionaría.
Argumentos centrales en los campos del serializador
.math-table { borde-colapso: colapsar; ancho: 100%; } .math-table td { borde: 1px sólido #5fb962; alineación de texto: izquierda! importante; relleno: 8px; } .math-table th { borde: 1px sólido #5fb962; relleno: 8px; } .math-table tr>th{ color de fondo: #c6ebd9; alineación vertical: medio; } .math-table tr:nth-child(odd) { background-color: #ffffff; }
| Argumento | Descripción |
|---|---|
| solo lectura | Establézcalo en True para asegurarse de que el campo se use al serializar una representación, pero no al crear o actualizar una instancia durante la deserialización. |
| escribir solamente | Establézcalo en True para asegurarse de que el campo se pueda usar al actualizar o crear una instancia, pero no se incluya al serializar la representación. |
| requerido | Establecer esto en False también permite omitir el atributo del objeto o la clave del diccionario de la salida al serializar la instancia. |
| defecto | Si se establece, proporciona el valor predeterminado que se utilizará para el campo si no se proporciona ningún valor de entrada. |
| permitir nula | Normalmente, se generará un error si se pasa Ninguno a un campo serializador. Establezca este argumento de palabra clave en Verdadero si Ninguno debe considerarse un valor válido. |
| fuente | El nombre del atributo que se utilizará para rellenar el campo. |
| validadores | Una lista de funciones de validación que deben aplicarse a la entrada de campo entrante y que generan un error de validación o simplemente regresan. |
| error de mensajes | Un diccionario de códigos de error a mensajes de error. |
| etiqueta | Una string de texto corta que se puede usar como el nombre del campo en campos de formulario HTML u otros elementos descriptivos. |
| texto de ayuda | Una string de texto que se puede utilizar como descripción del campo en campos de formulario HTML u otros elementos descriptivos. |
| inicial | Un valor que debe usarse para completar previamente el valor de los campos de formulario HTML. |
Python es un lenguaje de programación de alto nivel y propósito general ampliamente utilizado. Inicialmente fue diseñado por Guido van Rossum en 1991 y desarrollado por Python Software Foundation. Fue desarrollado principalmente para enfatizar la legibilidad del código y su sintaxis permite a los programadores expresar conceptos en menos líneas de código. Python es un lenguaje de programación que le permite trabajar rápidamente e integrar sistemas de manera más eficiente.
Python 3.8 contiene muchas pequeñas mejoras con respecto a las versiones anteriores. Este artículo describe las adiciones y los cambios más significativos en Python 3.8
Parámetros solo posicionales (/)
Hay una nueva sintaxis de parámetro de función «/» que indica que algunos parámetros de función deben especificarse posicionalmente y no pueden usarse como argumentos de palabra clave. La adición de «/» mejora la consistencia del lenguaje y permite un diseño de API robusto.
Ejemplo:
Producción:
Rastreo (última llamada más reciente):
Archivo «», línea 1, en
TypeError: add() recibió algunos argumentos posicionales pasados como argumentos de palabra clave: ‘x, y’
El marcador «/» significa que pasar valores para x e y solo se puede hacer posicionalmente, pero no usando argumentos de palabras clave.
Expresiones de asignación (: =)
Este operador se utiliza para asignar y devolver un valor en la misma expresión. Esto elimina la necesidad de inicializar la variable por adelantado. El principal beneficio de esto es que ahorra algunas líneas de código. También se le conoce como “El operador de la morsa” debido a su similitud con los ojos y colmillos de una morsa.
Ejemplo:
Producción:
f-strings ahora admite «=»
Este mecanismo de formato de strings se conoce como interpolación de strings literales o más comúnmente como strings F (debido al carácter f inicial que precede a la string literal). La idea detrás de f-strings es simplificar la interpolación de strings. Python 3.8 permite el uso del operador de asignación mencionado anteriormente y el signo igual (=) dentro de las strings f.
Por ejemplo, digamos que tenemos dos variables «a» y «b», y queremos imprimir «a + b» junto con el resultado. Aquí podemos usar f-strings=.
Ejemplo:
Producción:
Esto es muy útil durante la depuración, especialmente para todos los que usan sentencias print() para la depuración.
invertido() funciona con un diccionario
A diferencia de Python 3.7, ahora en Python 3.8, el método incorporado «invertido()» se puede usar para acceder a los elementos en el orden inverso de inserción.
Ejemplo:
Producción:
Sin paréntesis para declaraciones de retorno y rendimiento
Las declaraciones ‘rendimiento’ y ‘retorno’ no requieren paréntesis para devolver múltiples valores.
Por ejemplo:
Producción:
función pow()
En la forma de tres argumentos de pow(), cuando el exponente es -1, calcula el inverso multiplicativo modular del valor dado.
Por ejemplo, para calcular el inverso multiplicativo modular de 38 módulo 137:
Producción:
Advertencia de sintaxis
Si pierde una coma en su código como a = [(1, 2) (3, 4)], en lugar de arrojar TypeError, muestra una advertencia de sintaxis informativa como esta:
Comprensión de diccionario
Las comprensiones de dictados se han modificado para que la clave se calcule primero y el valor en segundo lugar:
módulo ‘csv’
El ‘csv.DictReader’ ahora devuelve instancias de diccionario en lugar de ‘colecciones.OrderedDict’.
importlib_metadata
importlib_metadata es una nueva biblioteca agregada en los módulos de utilidad estándar de Python, que proporciona una API para acceder a los metadatos de un paquete instalado, como sus puntos de entrada o su nombre de nivel superior.
Ejemplo: la versión de pip se puede verificar usando este módulo.
Producción:
9.0.1
Metadatos-Versión: 2.1
Nombre: pip
Versión: 9.0.1
Resumen: La herramienta recomendada por PyPA para instalar paquetes de Python.
Página de inicio: https://pip.pypa.io/
Autor: Los desarrolladores
de pip Correo electrónico del autor: python-virtualenv@groups.google.com
Licencia: MIT
Descripción: pip
===
La herramienta `PyPA recomendada
`_
para instalar Paquetes de Python.
* `Instalación `_
* `Documentación `_
* `Registro de cambios `_
* `Página de Github `_
* `Seguimiento de problemas `_
* `Lista de correo de usuarios `_
* `Lista de correo de desarrolladores `_
* Usuario IRC: #pypa en Freenode.
* Desarrollador IRC: #pypa-dev en Freenode.
.. imagen:: https://img.shields.io/pypi/v/pip.svg
:objetivo: https://pypi.python.org/pypi/pip
.. imagen:: https://img.shields .io/travis/pypa/pip/master.svg
:objetivo: http://travis-ci.org/pypa/pip
.. imagen:: https://img.shields.io/appveyor/ci/pypa/pip .svg
:objetivo: https://ci.appveyor.com/project/pypa/pip/history
.. imagen:: https://readthedocs.org/projects/pip/badge/?version=stable
:objetivo: https: //pip.pypa.io/en/stable
Código de conducta
————— Se espera que todas las personas que
interactúan en las bases de código, los rastreadores de problemas, las salas de chat
y las listas de correo del proyecto pip sigan el `Código de conducta de PyPA`_.
.. _Código de Conducta PyPA: https://www.pypa.io/es/ultimos/codigo-de-conducta/
Palabras clave: easy_install distutils setuptools egg virtualenv
Plataforma: DESCONOCIDO
Clasificador: Estado de desarrollo::5 – Producción/Estable
Clasificador: Audiencia prevista::Desarrolladores
Clasificador: Licencia::Aprobado por OSI ::
Clasificador de licencia MIT: Tema::Desarrollo de software::Herramientas de compilación
Clasificador: Lenguaje de Programación::Python::2
Clasificador: Lenguaje de Programación::Python::2.6
Clasificador: Lenguaje de Programación::Python::2.7
Clasificador: Lenguaje de Programación::Python::3
Clasificador: Lenguaje de Programación::Python::3.3
Clasificador: Lenguaje de Programación::Python::3.4
Clasificador: Lenguaje de Programación::Python::3.5
Clasificador: Lenguaje de programación::Python::Implementación::PyPy
Requires-Python: >=2.6,!=3.0.*,!=3.1.*,!=3.2.*
Provides-Extra: testing
Actuación
- En Python 3.8, el módulo de multiprocesamiento ofrece una clase SharedMemory que permite crear y compartir regiones de memoria entre diferentes procesos de Python. La memoria compartida proporciona una ruta mucho más rápida para pasar datos entre procesos, lo que eventualmente permite que Python use múltiples procesadores y múltiples núcleos de manera más eficiente.
- Muchos métodos y funciones integrados se han acelerado entre un 20 % y un 50 %.
- Las listas recién creadas ahora son en promedio un 12% más pequeñas que antes.
- Las escrituras en variables de clase son mucho más rápidas en Python 3.8.
La autenticación de Google y la obtención de correos desde cero significan que no se utiliza ningún módulo que ya haya configurado este proceso de autenticación. Usaremos el cliente python de la API de Google, oauth2client que es proporcionado por Google. A veces, es realmente difícil implementar esta autenticación de Google con estas bibliotecas, ya que no había documentación adecuada disponible. Pero después de completar esta lectura, las cosas se aclararán por completo.
Ahora vamos a crear el proyecto Django 2.0 y luego implementar los servicios de autenticación de Google y luego extraer los correos. Estamos extrayendo el correo solo para mostrar cómo se puede pedir permiso después de autenticarlo.
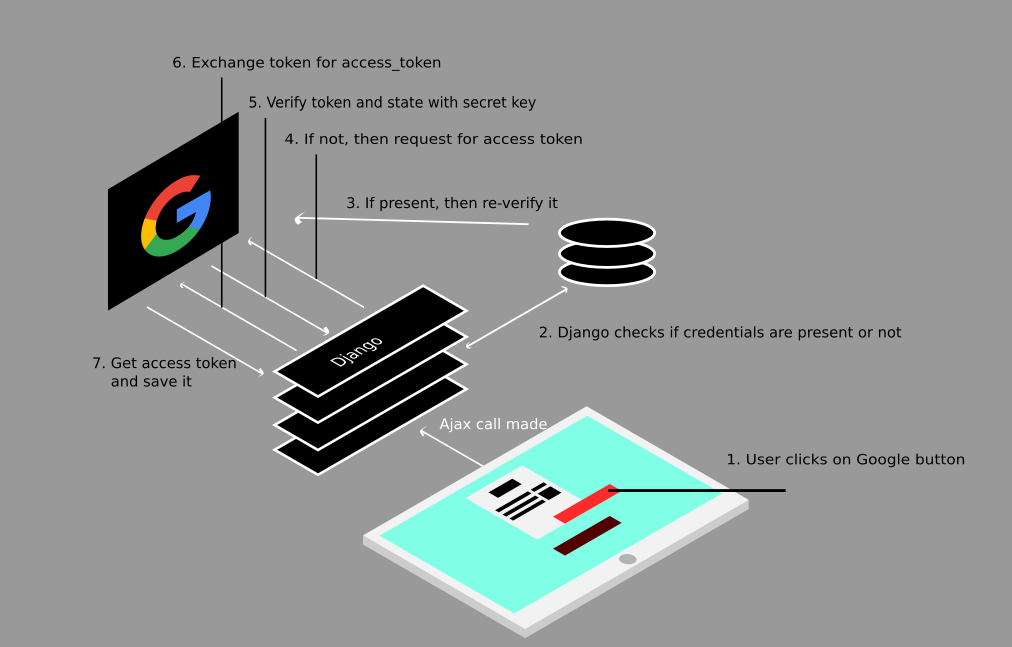
Paso #1: Creando el Proyecto Django
El primer paso es crear un entorno virtual y luego instalar las dependencias. Así que estaremos usando venv:
Este comando creará una carpeta myvenv a través de la cual acabamos de activar el entorno virtual. Ahora escriba
Entonces no debe ver dependencias instaladas en él. Ahora lo primero es instalar Django:
Esa es la versión de Django que usamos, pero siéntete libre de usar cualquier otra versión. Ahora, el siguiente paso es crear un proyecto, llamémoslo gfglogin:
Dado que estamos dentro del directorio de inicio de sesión de google, es por eso que queremos que el proyecto django esté en ese directorio actual solo para eso, necesita usar ‘. ‘ al final para la indicación de directorio actual. Luego cree una aplicación para separar la lógica del proyecto principal, así que cree una aplicación llamada gfgauth:
Entonces, la terminal general se verá así:
Desde que creamos una aplicación. Agregue el nombre de esa aplicación settings.pyen la INSTALLED_APP lista. Ahora tenemos el proyecto Django en ejecución, así que migrémoslo primero y luego verifiquemos si hay algún error o no.
Entonces, después de migrar, uno debería poder ejecutar el servidor y ver la página de inicio de Django en esa URL en particular. 
Paso #2: Instalar dependencias
Ya que tenemos el proyecto funcionando con éxito, instalemos los requisitos básicos. Primero, necesitamos googleapiclient, esto es necesario porque tenemos que crear un objeto de recurso que ayude a interactuar con la API. Entonces, para ser precisos, haremos uso del método `build` a partir de él.
Instalar:
Ahora, el segundo módulo es oauth2client, esto se asegurará de toda la autenticación, credencial, flujos y muchas cosas más complejas, por lo que es importante usar esto.
Y por último, instale jsonpickle, (por si acaso no está instalado) porque lo usará oauth2client al hacer CredentalsField.
Así que estas son las únicas dependencias que necesitamos. Ahora pasemos a la parte de codificación y veamos cómo funciona.
Paso #3: Creando modelos
Use modelos para almacenar las credenciales que obtenemos de una API, por lo que solo hay 2 campos principales que deben cuidarse. El primero es id , que será ForeignKey y el segundo es credential que será igual a CredentialsField. Este campo debe importarse desde oauth2client. Entonces nuestro models.pyse verá así:
Actualmente task y updated_time son simplemente campos adicionales agregados, por lo tanto, se pueden eliminar. Entonces, esta credencial contendrá los datos de la credencial en la base de datos.
Pauta importante:
Cuando importamos CredentialsField, automáticamente el __init__método se ejecuta en la parte posterior y si notará el código en la /google-login/myvenv/lib/python3.5/site-packages/oauth2client/contrib/django_util/__init__.py línea de ruta 233
Están importando urlresolvers para poder utilizar el método inverso. Ahora, el problema es que estos urlresolvers se eliminaron después de Django 1.10 o Django 1.11. Si está trabajando en Django 2.0, dará un error que indica que no se pueden encontrar los urlresolvers o que no están allí.
Ahora, para superar este problema, necesitamos cambiar 2 líneas, primero reemplace esa importación from django.core import urlresolvers afrom django.urls import reverse
Y luego reemplace la Línea 411 urlresolvers.reverse(...) areverse(...)
Ahora debería poder ejecutarlo con éxito.
Después de crear estos modelos:
Paso #4: Creando Vistas
En este momento, solo tenemos 3 vistas principales para manejar las requests. Lo primero es mostrar la página de inicio, el estado, el botón de Google para que podamos enviar requests de autenticación. La segunda vista se activará cuando se haga clic en el botón de Google, lo que significa una solicitud de AJAX. El tercero será manejar la solicitud de devolución de Google para que podamos aceptar el token de acceso y guardarlo en nuestra base de datos.
Primero, hagamos lo de la autenticación de Google:
Entonces, en este momento, debemos especificar el flujo a la API, qué permisos debemos solicitar, cuál es mi clave secreta y redirigir la URL. Así que para hacer eso ingrese:
Como puede notar settings.GOOGLE_OAUTH2_CLIENT_SECRETS_JSON, vaya a settings.pyarchivo y escriba:
Esto le dice a Django que donde json está presente el archivo. Posteriormente descargaremos este archivo. Después de especificar el flujo, comencemos la lógica.
Cada vez que necesitamos ver si alguien está autorizado o no, primero verificamos en nuestra base de datos si las credenciales de ese usuario ya están presentes o no. De lo contrario, hacemos requests a la URL de la API y luego obtenemos las credenciales.
Usamos DjangoORMStorage (que es proporcionado por oauth2client) para que podamos almacenar y recuperar credenciales del almacén de datos de Django. Entonces necesitamos pasar 4 parámetros para ello. Primero está la clase modelo que tiene CredientialsField dentro. El segundo es el ID único que tiene credenciales que significa nombre de clave, el tercero es el valor de clave que tiene las credenciales y el último es el nombre de CredentialsField que especificamos en models.py.
Luego obtenemos el valor del almacenamiento y vemos si es válido o no. Si no es válido, creamos un token de usuario y obtenemos uno para autorizar la URL, donde redirigimos al usuario a la página de inicio de sesión de Google. Después de redirigir, el usuario completará el formulario y una vez que Google autorice al usuario, Google enviará datos a la URL de devolución de llamada con access_token la que lo haremos más adelante. Ahora, en caso de que las credenciales del usuario ya estuvieran presentes, volverá a verificar las credenciales y le devolverá el token de acceso o, a veces, el token de acceso actualizado en caso de que el anterior haya expirado.
Ahora necesitamos manejar la URL de devolución de llamada, para hacer eso:
Ahora, dentro de la URL de devolución de llamada, cuando recibimos una respuesta de Google, capturamos los datos y obtenemos el estado de ellos, el estado no es más que el token que generamos mediante generateToken. Entonces lo que hacemos es que validamos el token con secret_key, el token que generamos y con el usuario que lo generó. Estas cosas se verifican mediante un xsrfutil.validate_tokenmétodo que garantiza que el token no sea demasiado antiguo y que se haya generado solo en un momento determinado. Si estas cosas no funcionan bien, le dará un error; de lo contrario, irá al siguiente paso y compartirá el código de la respuesta de devolución de llamada con Google para que pueda obtener el token de acceso.
Entonces, esta fue una verificación de 2 pasos y después de obtener con éxito la credencial, la guardamos en el almacén de datos de Django usando DjangoORMStorage porque solo podemos obtener y almacenar la credencial en CredentialsField. Una vez que lo almacenemos, podemos redirigir al usuario a cualquier página en particular y así es como puede obtener access_token.
Ahora vamos a crear una página de inicio que dirá si el usuario ha iniciado sesión o no.
En este momento, asumimos que el usuario está autenticado en Django, lo que significa que el usuario ya no es anónimo y tiene información guardada en la base de datos. Ahora, para tener soporte para el usuario anónimo, podemos eliminar las comprobaciones de credenciales en la base de datos o crear un usuario temporal.
Volviendo a la vista de inicio, primero verificaremos si el usuario está autenticado o no, lo que significa que el usuario no es anónimo, si es así, haga que inicie sesión; de lo contrario, primero verifique las credenciales. Si el usuario ya inició sesión desde Google, mostrará Estado como Verdadero; de lo contrario, mostrará Falso.
Ahora, llegando a las plantillas, creemos una. Primero vaya a la carpeta raíz y cree una carpeta llamada ‘plantillas’, luego dentro de eso cree index.html:
Ahora, esta página está muy simplificada, por lo que no hay CSS ni estilo, solo un enlace simple para verificar. Ahora también notará el archivo js . así que de nuevo ve a la carpeta raíz y crea un directorio comostatic/js/
Y dentro de js crea un archivo javascript main.js:
Este archivo js se usó para separar la lógica del archivo HTML y también para hacer una llamada AJAX a Django. Ahora tenemos todas las partes hechas para las vistas.
Paso #5: Creación de URL y configuraciones básicas
En las URL del proyecto principal significa gfglogin/urls.pyeditar y poner:
Porque necesitamos probar el funcionamiento de la aplicación gfgauth. Ahora dentro gfgauth/urls.py escribe:
Como puede ver, gmailAuthenticate es para llamadas AJAX, oauth2callback es para la URL de devolución de llamada y la última es la URL de la página de inicio. Ahora, antes de ejecutar, hay algunas configuraciones de las que no hemos hablado:
En settings.pynecesitas editar:
- En la lista PLANTILLAS agregue ‘plantillas’ dentro de la lista DIRS.
- Al final del archivo settings.py agregue:
STATIC_URL = '/static/' STATICFILES_DIRS = ( os.path.join(BASE_DIR, 'static'), ) GOOGLE_OAUTH2_CLIENT_SECRETS_JSON = 'client_secrets.json'
Así que acabamos de especificar dónde están presentes las plantillas y los archivos estáticos y, lo que es más importante, dónde está el archivo json secreto del cliente de google oauth2. Ahora vamos a descargar este archivo.
Paso #6: Generación del archivo secreto del cliente Oauth2
Dirígete a la página de Google Developer Console y crea un proyecto y asígnale el nombre que quieras. Después de crearlo, diríjase al panel del proyecto y haga clic en el menú de navegación que se encuentra en la parte superior izquierda. Luego haga clic en servicios API y luego en la página de credenciales. Haga clic en crear credenciales (es posible que deba establecer el nombre del producto antes de continuar, así que hágalo primero). Ahora seleccione la aplicación web ya que estamos usando Django. Después de esto, especifique el nombre y luego simplemente vaya a redirigir URI y allí escriba:
Y luego guárdalo. No necesita especificar los orígenes de Javascript autorizados, así que déjelo en blanco por ahora. Después de guardarlo, podrá ver todas sus credenciales, simplemente descargue las credenciales, se guardarán con algunos nombres aleatorios, así que simplemente vuelva a formatear el nombre del archivo y escriba ‘client_secrets’ y asegúrese de que esté en formato json. Luego guárdelo y péguelo en la carpeta raíz del proyecto Django (donde se encuentra manage.py).
Paso #7: Ejecutarlo
Ahora vuelve a comprobar si todo es correcto o no. Asegúrate de haberlo migrado. Además, antes de continuar, cree un superusuario para que ya no sea anónimo:
Escriba todos los detalles necesarios y luego haga:
Y ve a http://127.0.0.1:8000
Verás esto:
Lo cual está perfectamente bien, ahora escriba sus credenciales de superusuario aquí y luego podrá ver el panel de administración. Solo evita eso y vuelve a ir a http://127.0.0.1:8000
Ahora debería poder ver el enlace de Google, ahora haga clic en él y verá:

Ahora, como puede ver, dice Iniciar sesión para continuar con GFG, aquí GFG es el nombre de mi proyecto. Así que está funcionando bien. Ahora ingrese sus credenciales y después de enviar verá:

Dado que estamos solicitando permiso de correos, es por eso que le está pidiendo al usuario que lo permita. En caso de que muestre un error, en la consola de Google es posible que deba activar la API de Gmail en su proyecto. Ahora, una vez que lo permita, obtendrá las credenciales y se guardará dentro de su base de datos. En caso de que el usuario haga clic en Cancelar, deberá escribir algunos códigos más para manejar dicho flujo.
Ahora, en caso de que lo haya permitido, podrá ver el token de acceso en su consola/base de datos. Después de obtener access_token, puede utilizarlo para obtener el correo electrónico del usuario y todo lo demás.
Vea el código completo en este repositorio aquí .
Requisito previo: Estructura de datos del diccionario Dada una string, encuentre la primera palabra repetida en una string. Ejemplos:
Tenemos una solución existente para este problema, consulte Buscar la primera palabra repetida en un enlace de string . Podemos resolver este problema rápidamente en python usando la estructura de datos del Diccionario . El enfoque es simple,
para cada
bucle en otros idiomas.
Sintaxis:
for iterator_var in sequence:
statements(s)
Se puede usar para iterar sobre iteradores y un rango.
# Iterating over a list
print("List Iteration")
l = ["geeks", "for", "geeks"]
for i in l:
print(i)
# Iterating over a tuple (immutable)
print("\nTuple Iteration")
t = ("geeks", "for", "geeks")
for i in t:
print(i)
# Iterating over a String
print("\nString Iteration")
s = "Geeks"
for i in s :
print(i)
# Iterating over dictionary
print("\nDictionary Iteration")
d = dict()
d['xyz'] = 123
d['abc'] = 345
for i in d :
print("%s %d" %(i, d[i]))
Producción:
List Iteration geeks for geeks Tuple Iteration geeks for geeks String Iteration G e e k s Dictionary Iteration xyz 123 abc 345
Podemos usar for in loop para iteradores definidos por el usuario. Vea esto por ejemplo.
El lenguaje de programación Python permite usar un bucle dentro de otro bucle. La siguiente sección muestra algunos ejemplos para ilustrar el concepto.
Sintaxis:
for iterator_var in sequence:
for iterator_var in sequence:
statements(s)
statements(s)
La sintaxis para una instrucción de ciclo while anidado en el lenguaje de programación Python es la siguiente:
while expression:
while expression:
statement(s)
statement(s)
Una nota final sobre el anidamiento de bucles es que podemos poner cualquier tipo de bucle dentro de cualquier otro tipo de bucle. Por ejemplo, un bucle for puede estar dentro de un bucle while o viceversa.
from __future__ import print_function for i in range(1, 5): for j in range(i): print(i, end=' ') print()
Producción:
1 2 2 3 3 3 4 4 4 4
Las declaraciones de control de bucle cambian la ejecución de su secuencia normal. Cuando la ejecución sale de un ámbito, todos los objetos automáticos que se crearon en ese ámbito se destruyen. Python admite las siguientes declaraciones de control.
Sentencia Continue
Devuelve el control al inicio del ciclo.
# Prints all letters except 'e' and 's' for letter in 'geeksforgeeks': if letter == 'e' or letter == 's': continue print 'Current Letter :', letter var = 10
Producción:
Current Letter : g Current Letter : k Current Letter : f Current Letter : o Current Letter : r Current Letter : g Current Letter : k
Break Statement
Saca el control del bucle
for letter in 'geeksforgeeks': # break the loop as soon it sees 'e' # or 's' if letter == 'e' or letter == 's': break print 'Current Letter :', letter
Producción:
Current Letter : e
Instrucción de paso
Usamos la instrucción de paso para escribir bucles vacíos. Pass también se usa para declaraciones de control, funciones y clases vacías.
# An empty loop for letter in 'geeksforgeeks': pass print 'Last Letter :', letter
Producción:
Last Letter : s
Ejercicio:
Cómo imprimir una lista en orden inverso (del último al primer elemento) usando los bucles while y for in.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA