En el aprendizaje automático, las máquinas de vectores de soporte (SVM) son modelos de aprendizaje supervisado con algoritmos de aprendizaje asociados que analizan los datos utilizados para la clasificación y el análisis de regresión. Se utiliza principalmente en problemas de clasificación. En este algoritmo, cada elemento de datos se traza como un punto en un espacio n-dimensional (donde n es un número de características), siendo el valor de cada característica el valor de una coordenada particular. Luego, la clasificación se realiza encontrando el hiperplano que mejor diferencia las dos clases.
Además de realizar una clasificación lineal, las SVM pueden realizar de manera eficiente una clasificación no lineal, mapeando implícitamente sus entradas en espacios de características de alta dimensión.
Cómo funciona SVM
Una máquina de vectores de soporte (SVM) es un clasificador discriminativo definido formalmente por un hiperplano de separación. En otras palabras, dados los datos de entrenamiento etiquetados (aprendizaje supervisado), el algoritmo genera un hiperplano óptimo que categoriza nuevos ejemplos.
La pregunta más importante que surge al usar SVM es cómo decidir el hiperplano correcto. Considere los siguientes escenarios:
- Escenario 1:
En este escenario, hay tres hiperplanos llamados A, B, C. Ahora el problema es identificar el hiperplano correcto que diferencia mejor las estrellas y los círculos.
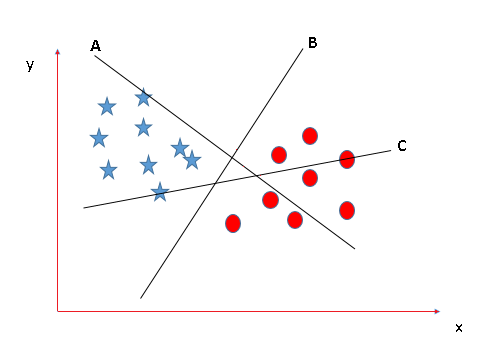
- La regla general que debe conocerse, antes de encontrar el hiperplano correcto, para clasificar la estrella y el círculo es que se debe seleccionar el hiperplano que segrega mejor las dos clases.
En este caso, B clasifica mejor la estrella y el círculo, por lo que es un hiperplano recto.
- Escenario 2:
Ahora toma otro Escenario donde los tres aviones están segregando bien las clases. Ahora surge la pregunta de cómo identificar el avión correcto en esta situación.
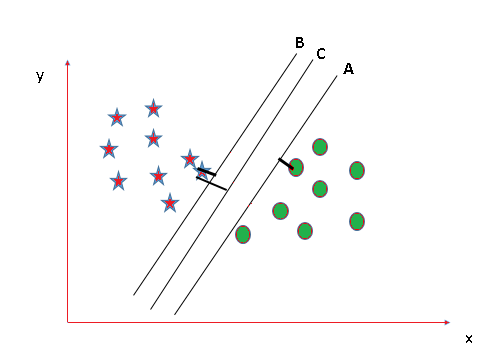
- En tales escenarios, calcule el margen, que es la distancia entre el punto de datos más cercano y el hiperplano. El plano que tenga la distancia máxima será considerado como el hiperplano correcto para clasificar mejor las clases.
Aquí C tiene el margen máximo y, por lo tanto, se considerará como un hiperplano recto.
Arriba hay algunos escenarios para identificar el hiperplano correcto.
Nota: Para obtener detalles sobre la clasificación mediante SVM en Python, consulte Clasificación de datos mediante máquinas de vectores de soporte (SVM) en Python
Implementación de SVM en R
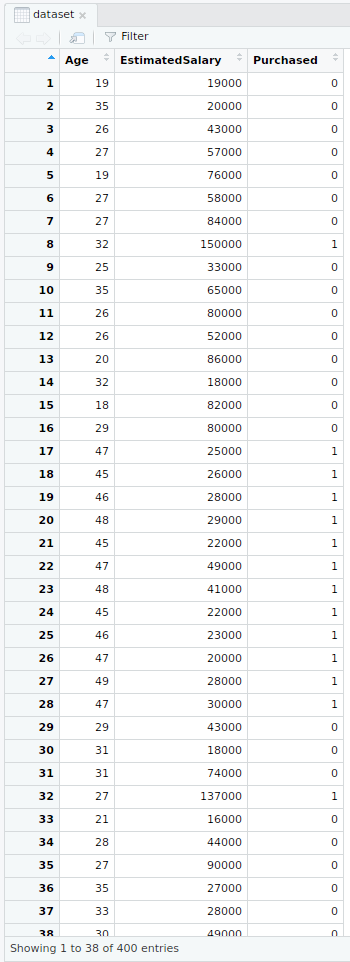
Aquí, se toma un ejemplo al importar un conjunto de datos de ayudas de redes sociales del archivo Social.csv.
La implementación se explica en los siguientes pasos:
- Importación del conjunto de datos
R
# Importing the dataset
dataset = read.csv('Social_Network_Ads.csv')
dataset = dataset[3:5]
- Producción:
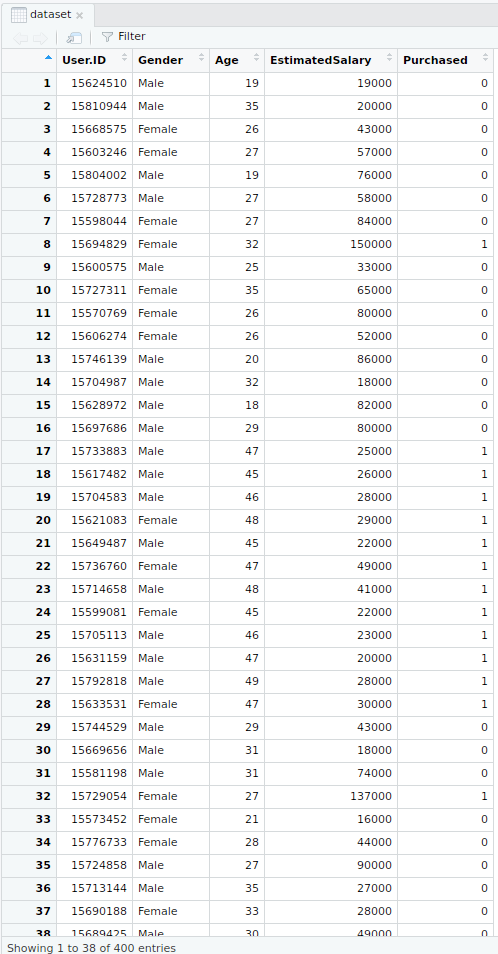
- Selección de las columnas 3-5
Esto se hace para facilitar el cálculo y la implementación (para simplificar el ejemplo).
R
# Taking columns 3-5 dataset = dataset[3:5]
- Producción:
- Codificación de la función de destino
R
# Encoding the target feature as factor dataset$Purchased = factor(dataset$Purchased, levels = c(0, 1))
- Producción:
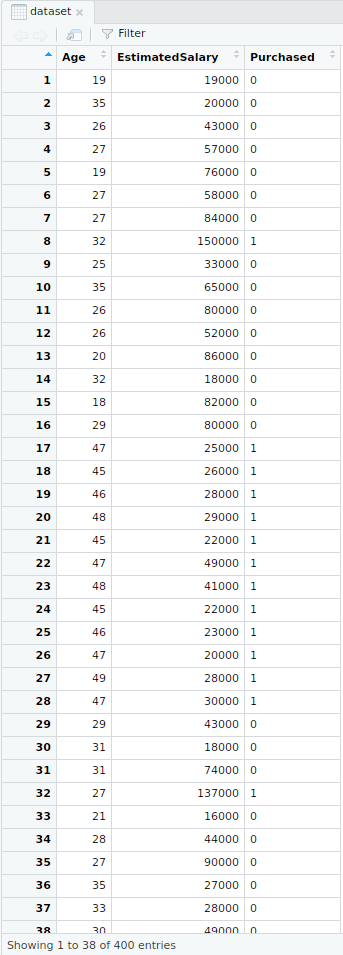
- Dividir el conjunto de datos
R
# Splitting the dataset into the Training set and Test set
install.packages('caTools')
library(caTools)
set.seed(123)
split = sample.split(dataset$Purchased, SplitRatio = 0.75)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
- Producción:
- Disidente
- Disidente

- Conjunto de datos de entrenamiento
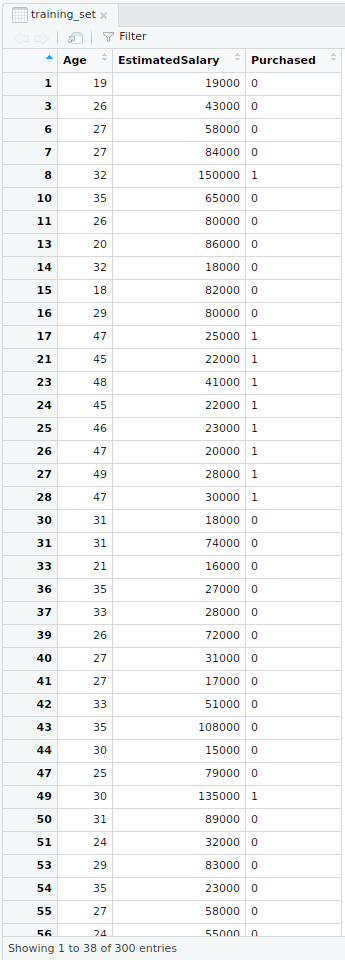
- Conjunto de datos de prueba
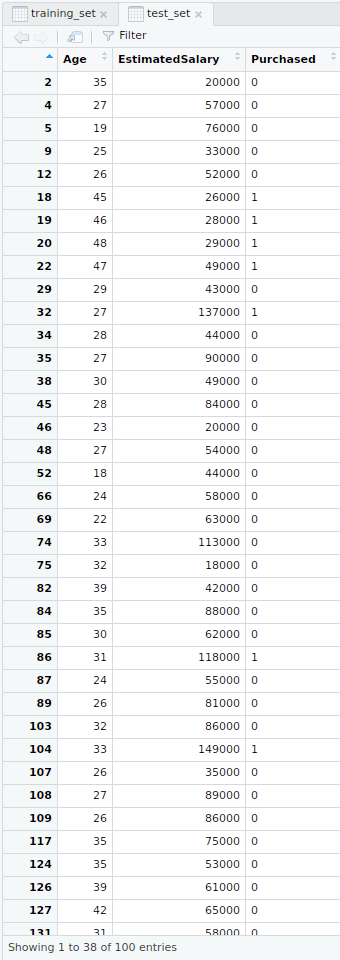
- Escalado de características
R
# Feature Scaling training_set[-3] = scale(training_set[-3]) test_set[-3] = scale(test_set[-3])
- Producción:
- Conjunto de datos de entrenamiento escalado de características
- Conjunto de datos de entrenamiento escalado de características
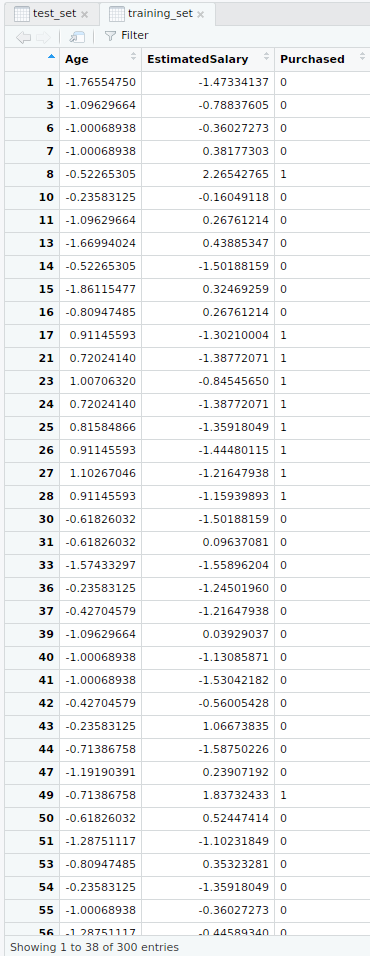
- Conjunto de datos de prueba escalado de características
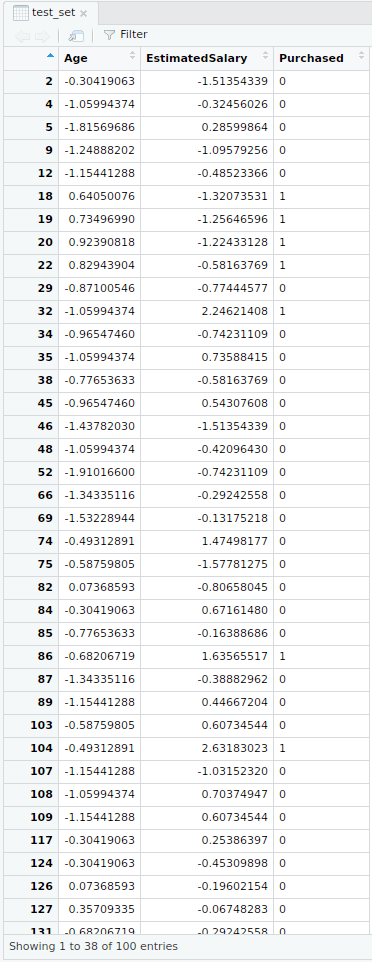
- Adaptación de SVM al conjunto de entrenamiento
R
# Fitting SVM to the Training set
install.packages('e1071')
library(e1071)
classifier = svm(formula = Purchased ~ .,
data = training_set,
type = 'C-classification',
kernel = 'linear')
- Producción:
- clasificador detallado
- clasificador detallado
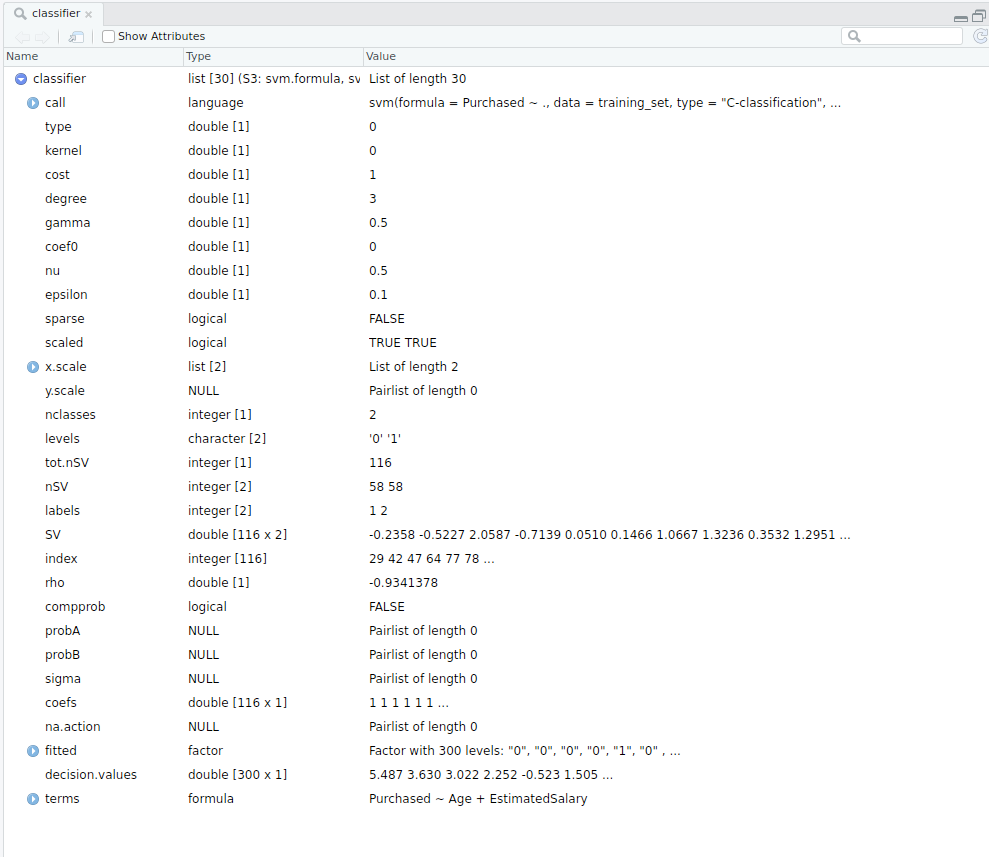
- Clasificador en pocas palabras
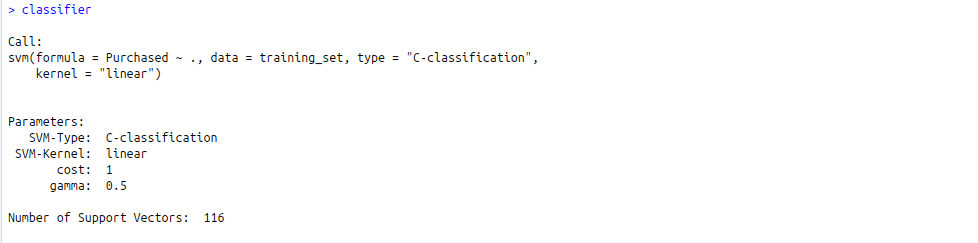
- Predicción del resultado del conjunto de pruebas
R
# Predicting the Test set results y_pred = predict(classifier, newdata = test_set[-3])
- Producción:

- Hacer array de confusión
R
# Making the Confusion Matrix cm = table(test_set[, 3], y_pred)
- Producción:

- Visualización de los resultados del conjunto de entrenamiento
R
# installing library ElemStatLearn
library(ElemStatLearn)
# Plotting the training data set results
set = training_set
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('Age', 'EstimatedSalary')
y_grid = predict(classifier, newdata = grid_set)
plot(set[, -3],
main = 'SVM (Training set)',
xlab = 'Age', ylab = 'Estimated Salary',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '.', col = ifelse(y_grid == 1, 'coral1', 'aquamarine'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3'))
- Producción:
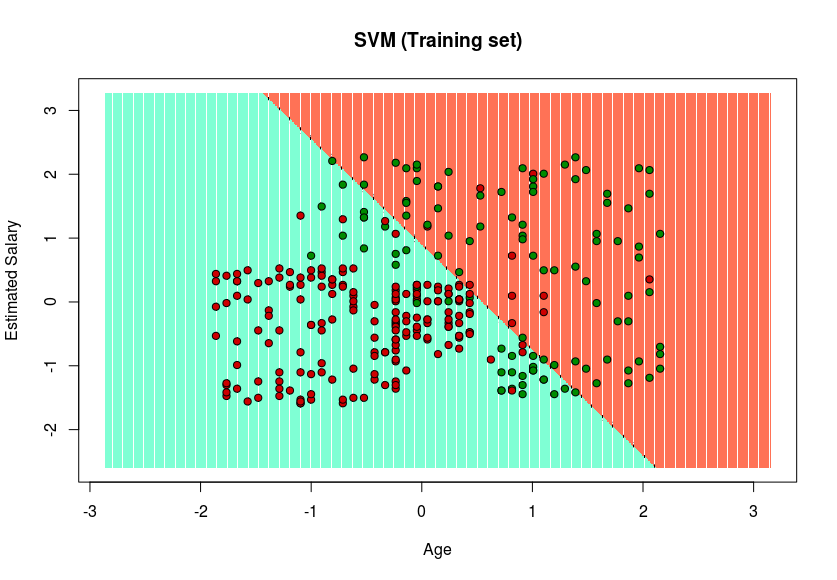
- Visualización de los resultados del conjunto de pruebas
R
set = test_set
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('Age', 'EstimatedSalary')
y_grid = predict(classifier, newdata = grid_set)
plot(set[, -3], main = 'SVM (Test set)',
xlab = 'Age', ylab = 'Estimated Salary',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '.', col = ifelse(y_grid == 1, 'coral1', 'aquamarine'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3'))
- Producción:
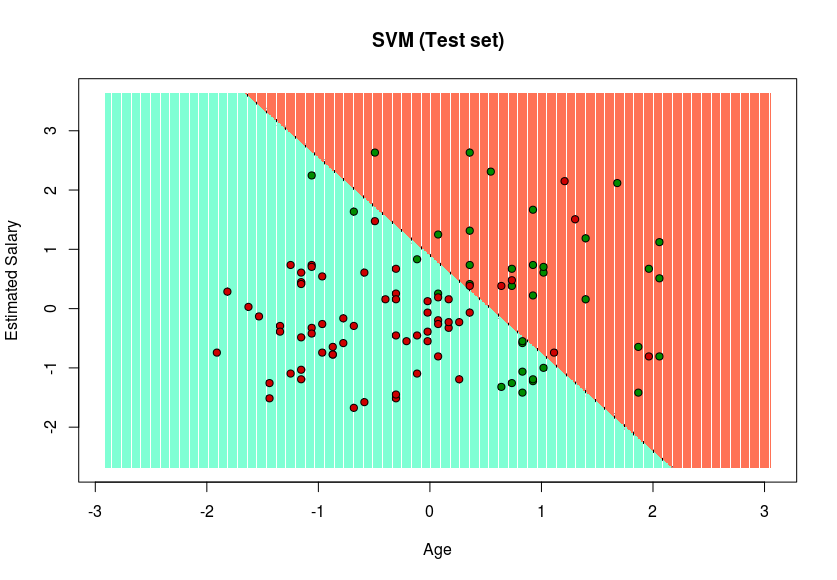
Dado que en el resultado, se ha encontrado un hiperplano en el resultado del conjunto de entrenamiento y se ha verificado que es el mejor en el resultado del conjunto de prueba. Por lo tanto, SVM se ha implementado con éxito en R.
Publicación traducida automáticamente
Artículo escrito por Akashkumar17 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA