En todas partes de las redes sociales, la clasificación de imágenes se lleva a cabo desde la selección de fotos de perfil en Facebook, Instagram hasta la categorización de imágenes de ropa en aplicaciones de compras como Myntra, Amazon, Flipkart, etc. La clasificación se ha convertido en una parte integral de cualquier plataforma de comercio electrónico. La clasificación también se utiliza para identificar caras criminales en la ley y las redes sociales.
En este artículo, aprenderemos cómo clasificar imágenes en Python. La clasificación de imágenes de ropa es un ejemplo de clasificación de imágenes en el aprendizaje automático, lo que significa clasificar las imágenes en sus respectivas clases de categorías. Para obtener imágenes de ropa, usaremos el conjunto de datos fashion_mnist que viene con TensorFlow . Este conjunto de datos contiene imágenes de ropa de 10 categorías diferentes. Es un reemplazo para el conjunto de datos MNIST para principiantes que consta de dígitos escritos a mano. Sabremos más al respecto a medida que avancemos.
Implementación paso a paso
Paso 1: Importación de las librerías necesarias para la clasificación
- TensorFlow : para desarrollar y entrenar el modelo usando python
- NumPy : para la manipulación de arrays
- Matplotlib: para la visualización de datos
Python3
# importing the necessary libraries import tensorflow as tf import numpy as np import matplotlib.pyplot as plt
Paso 2: Cargar y explorar los datos
Luego cargamos el conjunto de datos fashion_mnist y vemos las formas de los datos de entrenamiento y prueba. Es evidente que hay 60.000 imágenes de entrenamiento para entrenar los datos y 10.000 imágenes de prueba para probar en el modelo. En total contiene 70.000 imágenes en diez categorías, es decir, ‘Camiseta/top’, ‘Pantalones’, ‘Jersey’, ‘Vestido’, ‘Abrigo’, ‘Sandalia’, ‘Camisa’, ‘Zapatillas’, ‘Bolso’, ‘Botín’.
Python3
# storing the dataset path
clothing_fashion_mnist = tf.keras.datasets.fashion_mnist
# loading the dataset from tensorflow
(x_train, y_train),
(x_test, y_test) = clothing_fashion_mnist.load_data()
# displaying the shapes of training and testing dataset
print('Shape of training cloth images: ',
x_train.shape)
print('Shape of training label: ',
y_train.shape)
print('Shape of test cloth images: ',
x_test.shape)
print('Shape of test labels: ',
y_test.shape)
Producción:

Las etiquetas consisten en una array de números enteros que va del 0 al 9. Dado que los nombres de las clases no se agregan en el conjunto de datos fashion_mnist , almacenamos los nombres de las clases reales en una variable para usarlos más tarde para la visualización de datos. A partir de la salida, podemos ver que el valor del píxel se encuentra en el rango de 0 a 255.
Python3
# storing the class names as it is # not provided in the dataset label_class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot'] # display the first images plt.imshow(x_train[0]) plt.colorbar() # to display the colourbar plt.show()
Producción:
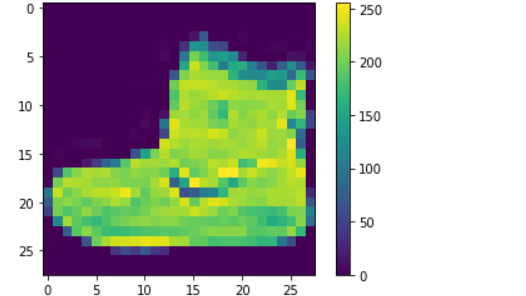
Paso 3: preprocesamiento de los datos
El siguiente código normaliza los datos, ya que podemos ver que los valores de los píxeles se encuentran en el rango de 0 a 255. Por lo tanto, debemos dividir cada uno por 255 para escalar el valor entre 0 y 1.
Python3
x_train = x_train / 255.0 # normalizing the training data x_test = x_test / 255.0 # normalizing the testing data
Paso 4: visualización de datos
El siguiente código muestra las primeras 20 imágenes de ropa con sus etiquetas de clase, asegurándonos de que vamos en la dirección correcta para construir el modelo. Aquí trazamos x_train con mapa de colores como binario y agregamos los nombres de clase de cada uno de la array label_class_names que hemos almacenado previamente.
Python3
plt.figure(figsize=(15, 5)) # figure size i = 0 while i < 20: plt.subplot(2, 10, i+1) # showing each image with colourmap as binary plt.imshow(x_train[i], cmap=plt.cm.binary) # giving class labels plt.xlabel(label_class_names[y_train[i]]) i = i+1 plt.show() # plotting the final output figure
Producción:

Paso 5: Construcción del modelo
Aquí construimos nuestro modelo creando capas de red neuronal. El tf.keras.layers.Flatten() convierte las imágenes de una array bidimensional en una array unidimensional y tf.keras.layers.Dense, tiene ciertos parámetros que se aprenden durante la fase de entrenamiento.
Python3
# Building the model model = tf.keras.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(10) ])
Paso 6: Compilar el modelo
Aquí compilamos el modelo usando adam Optimizer , SparseCategoricalCrossentropy como función de pérdida y metrics=[‘accuracy’] .
Python3
# compiling the model cloth_model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy( from_logits=True), metrics=['accuracy'])
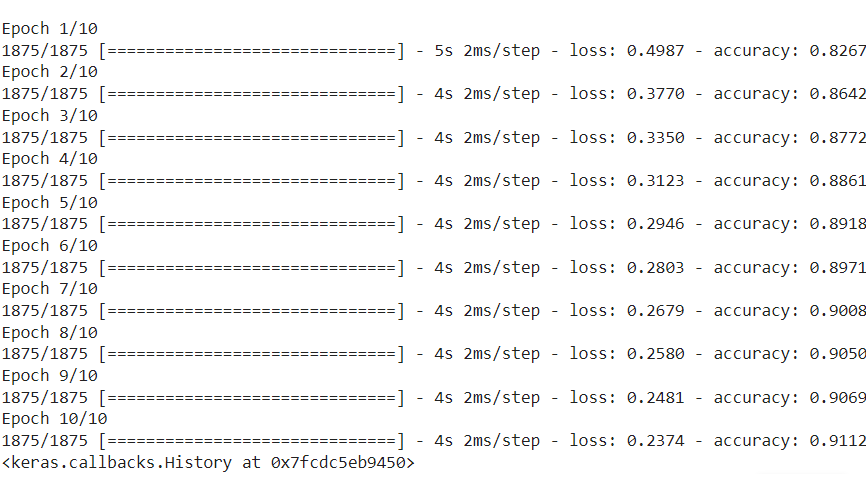
Paso 7: Entrenamiento de los datos en el modelo construido
Ahora introduciremos x_train, y_train, es decir, los datos de entrenamiento en nuestro modelo ya compilado. El método model.fit() ayuda a ajustar los datos de entrenamiento en nuestro modelo.
Python3
# Fitting the model to the training data cloth_model.fit(x_train, y_train, epochs=10)
Producción:
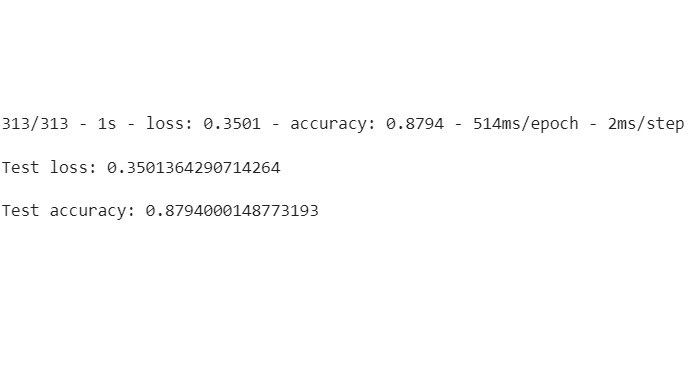
Paso 8: Evaluar la pérdida y precisión del modelo
Aquí veremos qué tan bueno es nuestro modelo al calcular la pérdida y la precisión del modelo. A partir del resultado, podemos ver que la puntuación de precisión en los datos de prueba es menor que la de los datos de entrenamiento. Así que es un modelo sobreajustado.
Python3
# calculating loss and accuracy score
test_loss, test_acc = cloth_model.evaluate(x_test,
y_test,
verbose=2)
print('\nTest loss:', test_loss)
print('\nTest accuracy:', test_acc)
Producción
Paso 9: hacer predicciones en un modelo entrenado con datos de prueba
Ahora podemos usar el conjunto de datos de prueba para hacer predicciones sobre el modelo construido. Intentamos predecir la primera imagen de prueba, es decir , x_test[0] usando predicciones[0], lo que resultó en la etiqueta de prueba 9 , es decir , Botines. Hemos agregado la función Softmax() para convertir los logits de salida lineal en probabilidad, ya que es mucho más fácil de calcular.
Python3
# using Softmax() function to convert
# linear output logits to probability
prediction_model = tf.keras.Sequential(
[cloth_model, tf.keras.layers.Softmax()])
# feeding the testing data to the probability
# prediction model
prediction = prediction_model.predict(x_test)
# predicted class label
print('Predicted test label:', np.argmax(prediction[0]))
# predicted class label name
print(label_class_names[np.argmax(prediction[0])])
# actual class label
print('Actual test label:', y_test[0])
Producción:

Paso 10: Visualización de datos de etiquetas de prueba previstas frente a reales
Por último, visualizaremos nuestras primeras 24 imágenes predichas frente a las etiquetas de clase reales para ver qué tan bueno es nuestro modelo.
Python3
# assigning the figure size
plt.figure(figsize=(15, 6))
i = 0
# plotting total 24 images by iterating through it
while i < 24:
image, actual_label = x_test[i], y_test[i]
predicted_label = np.argmax(prediction[i])
plt.subplot(3, 8, i+1)
plt.tight_layout()
plt.xticks([])
plt.yticks([])
# display plot
plt.imshow(image)
# if else condition to distinguish right and
# wrong
color, label = ('green', 'Correct Prediction')
if predicted_label == actual_label else (
'red', 'Incorrect Prediction')
# plotting labels and giving color to it
# according to its correctness
plt.title(label, color=color)
# labelling the images in x-axis to see
# the correct and incorrect results
plt.xlabel(" {} ~ {} ".format(
label_class_names[actual_label],
label_class_names[predicted_label]))
# labelling the images orderwise in y-axis
plt.ylabel(i)
# incrementing counter variable
i += 1
Producción:
Como podemos ver claramente que las predicciones 12, 17 y 23 están mal clasificadas pero el resto es correcto. Dado que ningún modelo de clasificación puede ser 100% correcto en realidad, este es un modelo bastante bueno que construimos.

Publicación traducida automáticamente
Artículo escrito por rijushree100guha y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA