El análisis de agrupamiento o simplemente agrupamiento es básicamente un método de aprendizaje no supervisado que divide los puntos de datos en una serie de lotes o grupos específicos, de modo que los puntos de datos en los mismos grupos tienen propiedades similares y los puntos de datos en diferentes grupos tienen diferentes propiedades en algún sentido. Comprende muchos métodos diferentes basados en la evolución diferencial.
Por ejemplo, K-Means (distancia entre puntos), Propagación de afinidad (distancia del gráfico), Desplazamiento medio (distancia entre puntos), DBSCAN (distancia entre los puntos más cercanos), mezclas gaussianas (distancia de Mahalanobis a los centros), agrupamiento espectral (distancia del gráfico), etc. .
Fundamentalmente, todos los métodos de agrupamiento utilizan el mismo enfoque, es decir, primero calculamos las similitudes y luego lo usamos para agrupar los puntos de datos en grupos o lotes. Aquí nos centraremos en el agrupamiento espacial basado en la densidad de aplicaciones con el método de agrupamiento de ruido (DBSCAN).
Los clústeres son regiones densas en el espacio de datos, separadas por regiones de menor densidad de puntos. El algoritmo DBSCAN se basa en esta noción intuitiva de «grupos» y «ruido». La idea clave es que para cada punto de un grupo, la vecindad de un radio dado debe contener al menos un número mínimo de puntos.
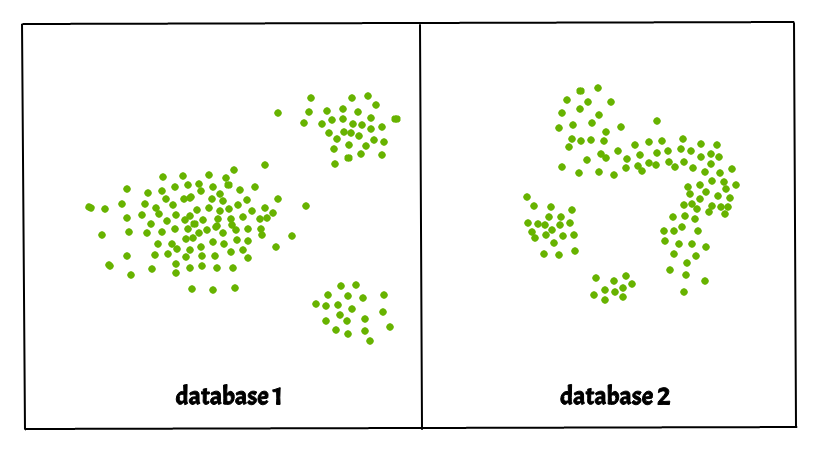
¿Por qué DBSCAN?
Los métodos de partición (K-medias, agrupamiento PAM) y el trabajo de agrupamiento jerárquico para encontrar grupos de forma esférica o grupos convexos. En otras palabras, son adecuados solo para racimos compactos y bien separados. Además, también se ven gravemente afectados por la presencia de ruido y valores atípicos en los datos.
Los datos de la vida real pueden contener irregularidades, como:
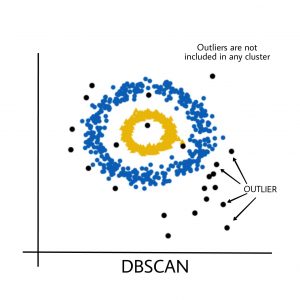
- Los clústeres pueden tener una forma arbitraria, como los que se muestran en la siguiente figura.
- Los datos pueden contener ruido.

La siguiente figura muestra un conjunto de datos que contiene grupos no convexos y valores atípicos/ruidos. Dados tales datos, el algoritmo k-means tiene dificultades para identificar estos grupos con formas arbitrarias.
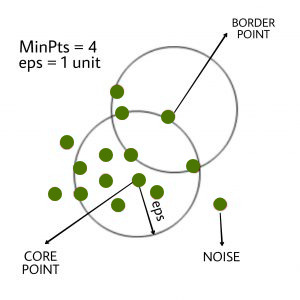
El algoritmo DBSCAN requiere dos parámetros:
- eps : define la vecindad alrededor de un punto de datos, es decir, si la distancia entre dos puntos es menor o igual a ‘eps’, entonces se consideran vecinos. Si el valor eps se elige demasiado pequeño, gran parte de los datos se considerarán atípicos. Si se elige muy grande, los grupos se fusionarán y la mayoría de los puntos de datos estarán en los mismos grupos. Una forma de encontrar el valor eps se basa en el gráfico de k-distancia .
- MinPts : número mínimo de vecinos (puntos de datos) dentro del radio de eps. Cuanto más grande sea el conjunto de datos, se debe elegir el valor más grande de MinPts. Como regla general, los MinPts mínimos se pueden derivar del número de dimensiones D en el conjunto de datos como, MinPts >= D+1. El valor mínimo de MinPts debe elegirse al menos 3.
En este algoritmo, tenemos 3 tipos de puntos de datos.
Punto central : un punto es un punto central si tiene más de puntos MinPts dentro de eps.
Punto de borde: un punto que tiene menos de MinPts dentro de eps pero está en la vecindad de un punto central.
Ruido o valor atípico : un punto que no es un punto central o un punto fronterizo.
El algoritmo DBSCAN se puede abstraer en los siguientes pasos:
- Encuentre todos los puntos vecinos dentro de eps e identifique los puntos centrales o visitados con más de vecinos MinPts.
- Para cada punto central, si aún no está asignado a un clúster, cree un nuevo clúster.
- Encuentre recursivamente todos sus puntos conectados por densidad y asígnelos al mismo grupo que el punto central.
Se dice que un punto a y b están conectados por densidad si existe un punto c que tiene un número suficiente de puntos en sus vecinos y ambos puntos a y b están dentro de la distancia eps . Este es un proceso de enstringmiento. Entonces, si b es vecino de c , c es vecino de d , d es vecino de e , que a su vez es vecino de a implica que b es vecino de a. - Iterar a través de los puntos no visitados restantes en el conjunto de datos. Aquellos puntos que no pertenecen a ningún clúster son ruido.
A continuación se muestra el algoritmo de agrupamiento DBSCAN en pseudocódigo:
DBSCAN(dataset, eps, MinPts){
# cluster index
C = 1
for each unvisited point p in dataset {
mark p as visited
# find neighbors
Neighbors N = find the neighboring points of p
if |N|>=MinPts:
N = N U N'
if p' is not a member of any cluster:
add p' to cluster C
}
Implementación del algoritmo anterior en Python:
Aquí, usaremos la biblioteca de Python sklearn para calcular DBSCAN. También usaremos la biblioteca matplotlib.pyplot para visualizar clústeres. El conjunto de datos utilizado se puede encontrar aquí .
Métricas de evaluación
Además, utilizaremos la puntuación de silueta y la puntuación de rand ajustada para evaluar los algoritmos de agrupación.
La puntuación de silueta está en el rango de -1 a 1. Una puntuación cercana a 1 denota el mejor significado de que el punto de datos i es muy compacto dentro del grupo al que pertenece y muy lejos de los otros grupos. El peor valor es -1. Los valores cercanos a 0 indican grupos superpuestos.
Absolute Rand Score está en el rango de 0 a 1. Más de 0,9 denota una excelente recuperación de grupos, por encima de 0,8 es una buena recuperación. Menos de 0,5 se considera una mala recuperación.
Ejemplo
Python3
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
from sklearn.preprocessing import StandardScaler
from sklearn import datasets
# Load data in X
X, y_true = make_blobs(n_samples=300, centers=4,
cluster_std=0.50, random_state=0)
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
# Number of clusters in labels, ignoring noise if present.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
print(labels)
# Plot result
# Black removed and is used for noise instead.
unique_labels = set(labels)
colors = ['y', 'b', 'g', 'r']
print(colors)
for k, col in zip(unique_labels, colors):
if k == -1:
# Black used for noise.
col = 'k'
class_member_mask = (labels == k)
xy = X[class_member_mask & core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=col,
markeredgecolor='k',
markersize=6)
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=col,
markeredgecolor='k',
markersize=6)
plt.title('number of clusters: %d' % n_clusters_)
plt.show()
#evaluation metrics
sc = metrics.silhouette_score(X, labels)
print("Silhouette Coefficient:%0.2f"%sc)
ari = adjusted_rand_score(y_true, labels)
print("Adjusted Rand Index: %0.2f"%ari)
Producción:
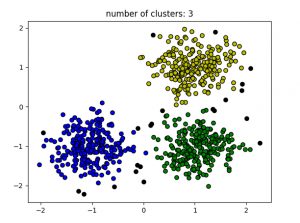
Silhouette Coefficient:0.13 Adjusted Rand Index: 0.31
Los puntos negros representan valores atípicos. Al cambiar los eps y los MinPts , podemos cambiar la configuración del clúster.
Ahora, la pregunta que debe plantearse es: ¿por qué deberíamos usar DBSCAN cuando K-Means es el método ampliamente utilizado en el análisis de conglomerados?
Desventaja de K-MEANS:
K-Means solo forma grupos esféricos. Este algoritmo falla cuando los datos no son esféricos (es decir, la misma varianza en todas las direcciones).
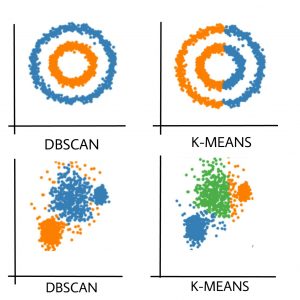
El algoritmo K-Means es sensible a valores atípicos. Los valores atípicos pueden sesgar los clústeres en K-Means en gran medida.
El algoritmo K-Means requiere uno para especificar el número de grupos a priori, etc.
Básicamente, el algoritmo DBSCAN supera todos los inconvenientes mencionados anteriormente del algoritmo K-Means. El algoritmo DBSCAN identifica la región densa agrupando puntos de datos que están cerrados entre sí en función de la medición de la distancia.
La implementación de Python del algoritmo anterior sin usar la biblioteca sklearn se puede encontrar aquí dbscan_in_python .
Publicación traducida automáticamente
Artículo escrito por Debomit Dey y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA