Muchos algoritmos de aprendizaje automático requieren que los datos sean numéricos. Entonces, antes de entrenar un modelo, necesitamos convertir datos categóricos en forma numérica. Hay varios métodos de codificación categóricos disponibles. Catboost es uno de ellos. Catboost es un codificador categórico basado en objetivos. Es un codificador supervisado que codifica columnas categóricas según el valor objetivo. Admite objetivos binomiales y continuos.
La codificación de destino es una técnica popular utilizada para la codificación categórica. Reemplaza una característica categórica con el valor promedio del objetivo correspondiente a esa categoría en el conjunto de datos de entrenamiento combinado con la probabilidad del objetivo en todo el conjunto de datos. Pero esto introduce una fuga de objetivo ya que el objetivo se utiliza para predecir el objetivo. Dichos modelos tienden a estar sobreajustados y no se generalizan bien en circunstancias no vistas.
Un codificador CatBoost es similar a la codificación de destino, pero también implica un principio de ordenación para superar este problema de fuga de destino. Utiliza el principio similar a la validación de datos de series temporales. Los valores de la estadística objetivo se basan en el historial observado, es decir, la probabilidad objetivo para la característica actual se calcula solo a partir de las filas (observaciones) anteriores.
Los valores de características categóricas se codifican mediante la siguiente fórmula:

TargetCount : Suma del valor objetivo para esa característica categórica en particular (hasta la actual).
Prior : Es un valor constante determinado por (suma de los valores objetivo en todo el conjunto de datos)/(número total de observaciones (es decir, filas) en el conjunto de datos)
FeatureCount : Número total de características categóricas observadas hasta la actual con el mismo valor que la actual.
Con este enfoque, las primeras observaciones en el conjunto de datos siempre tienen estadísticas objetivo con una varianza mucho mayor que las sucesivas. Para reducir este efecto, se utilizan muchas permutaciones aleatorias de los mismos datos para calcular las estadísticas objetivo y la codificación final se calcula promediando estas permutaciones. Entonces, si el número de permutaciones es lo suficientemente grande, los valores finales codificados obedecen a la siguiente ecuación:
TargetCount : Suma del valor objetivo para esa característica categórica en particular en todo el conjunto de datos.
Prior : Es un valor constante determinado por (suma de los valores objetivo en todo el conjunto de datos)/(número total de observaciones (es decir, filas) en el conjunto de datos)
FeatureCount : número total de características categóricas observadas en todo el conjunto de datos con el mismo valor que el actual.
Por ejemplo, si tenemos una columna de características categóricas con valores
color=[“rojo”, “azul”, “azul”, “verde”, “rojo”, “rojo”, “negro”, “negro”, “azul”, “verde”] y columna de destino con valores, destino =[1, 2, 3, 2, 3, 1, 4, 4, 2, 3]
Entonces, antes será 25/10 = 2.5
Para la categoría «roja», TargetCount será 1+3+1 = 5 y FeatureCount = 3
Y por lo tanto, el valor codificado para «rojo» será (5+2.5) /(3+1)=1.875
Sintaxis:
category_encoders.cat_boost.CatBoostEncoder(verbose=0, cols=None, drop_invariant=False, return_df=True, handle_unknown='value', handle_missing='value', random_state=None, sigma=None, a=1)
Parámetros:
- verbose : Verbosidad de la salida, es decir, si imprimir la salida del procesamiento en la pantalla o no. 0 para no imprimir, valor positivo para imprimir las salidas del procesamiento intermedio.
- cols : una lista de características (columnas) que se codificarán. De forma predeterminada, es Ninguno , lo que indica que se deben codificar todas las columnas con un tipo de datos de objeto .
- drop_invariant : True significa eliminar columnas con variación cero (mismo valor para cada fila). Falso, por defecto.
- return_df : True para devolver un marco de datos de pandas desde la transformación, False devolverá una array numpy en su lugar. Cierto, por defecto.
- handle_missing : forma de manejar los valores faltantes (no completados). error genera un error de valor faltante, return_nan devuelve NaN y value devuelve la media objetivo. El valor predeterminado es el valor.
- handle_unknown : Manera de manejar valores desconocidos (indefinidos). Las opciones son las mismas que las del parámetro handle_missing .
- sigma : Se utiliza para disminuir el sobreajuste. Los datos de entrenamiento se agregan con un ruido de distribución normal, mientras que los datos de prueba no se tocan. sigma es la desviación estándar de esa distribución normal.
- a : Valor flotante para el suavizado aditivo. Es necesario para escenarios en los que los atributos o puntos de datos no estaban presentes en el conjunto de datos de entrenamiento pero pueden estar presentes en el conjunto de datos de prueba. De forma predeterminada, se establece en 1. Si no es 1, la ecuación de codificación después de incluir este parámetro de suavizado toma la siguiente forma:

El codificador está disponible como CatBoostEncoder en la biblioteca de codificaciones categóricas . Este codificador funciona de manera similar a los transformadores scikit-learn con los métodos .fit_transform() , .fit() y .transform() .
Ejemplo:
Python3
# import libraries
import category_encoders as ce
import pandas as pd
# Make dataset
train = pd.DataFrame({
'color': ["red", "blue", "blue", "green", "red",
"red", "black", "black", "blue", "green"],
'interests': ["sketching", "painting", "instruments",
"sketching", "painting", "video games",
"painting", "instruments", "sketching",
"sketching"],
'height': [68, 64, 87, 45, 54, 64, 67, 98, 90, 87],
'grade': [1, 2, 3, 2, 3, 1, 4, 4, 2, 3], })
# Define train and target
target = train[['grade']]
train = train.drop('grade', axis = 1)
# Define catboost encoder
cbe_encoder = ce.cat_boost.CatBoostEncoder()
# Fit encoder and transform the features
cbe_encoder.fit(train, target)
train_cbe = cbe_encoder.transform(train)
# We can use fit_transform() instead of fit()
# and transform() separately as follows:
# train_cbe = cbe_encoder.fit_transform(train,target)
Producción:
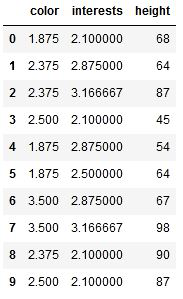
Conjunto de datos después de la codificación Catboost (train_cbe)
Publicación traducida automáticamente
Artículo escrito por hemavatisabu y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA