Requisito previo: clasificación por fusión , clasificación por inserción
Merge Sort :es un algoritmo externo y se basa en la estrategia divide y vencerás. En estaclasificación:
- Los elementos se dividen en dos subarreglos (n/2) una y otra vez hasta que solo queda un elemento.
- La ordenación por combinación utiliza almacenamiento adicional para ordenar la array auxiliar.
- La ordenación por combinación usa tres arreglos donde dos se usan para almacenar cada mitad, y el tercero externo se usa para almacenar la lista ordenada final al fusionar los otros dos y luego cada arreglo se ordena recursivamente.
- Por último, todas las sub-arrays se fusionan para que sea un tamaño de elemento ‘n’ de la array.
A continuación se muestra la imagen para ilustrar Merge Sort :
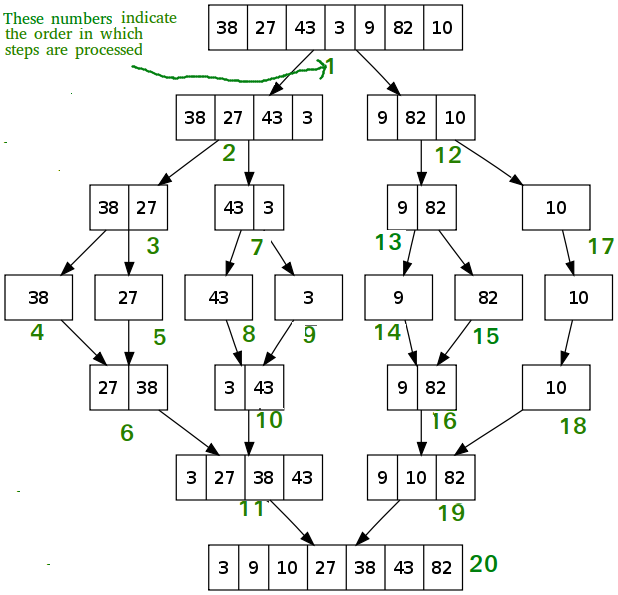
La clasificación por inserción es un algoritmo de clasificación en el que los elementos se toman de un elemento sin clasificar, se insertan en orden ordenado delante de los demás elementos y se repiten hasta que todos los elementos estén en orden. El algoritmo es simple de implementar y generalmente consta de dos bucles: un bucle externo para seleccionar elementos y un bucle interno para iterar a través de la array. Funciona según el principio de clasificar los naipes en nuestras manos.
A continuación se muestra la imagen para ilustrar la ordenación por inserción :

Diferencia entre la ordenación por fusión y la ordenación por inserción :
- Complejidad de tiempo: en combinación, ordene el peor de los casos: O(N*log N) , caso promedio: O(N*log N) y mejor caso: O(N*log N) ,
mientras que
en inserción ordene el peor de los casos: O (N 2 ) , Caso promedio: O(N 2 ) , y Mejor caso: O(N) . - Complejidad del espacio: la ordenación por fusión es recursiva y ocupa la complejidad del espacio auxiliar de O(N) , por lo que no se puede preferir en lugar donde la memoria es un problema, mientras
que la ordenación por inserción solo toma la complejidad del espacio auxiliar de O(1) . Ordena toda la array simplemente usando una variable adicional. - Conjuntos de datos: se prefiere Merge Sort para grandes conjuntos de datos. Sucede que comparar todos los elementos presentes en la array, por lo tanto, no es muy útil para conjuntos de datos pequeños,
mientras que la
ordenación por inserción se prefiere para menos elementos. Se vuelve rápido cuando los datos ya están ordenados o casi ordenados porque omite los valores ordenados. - Eficiencia: considerando la complejidad de tiempo promedio de ambos algoritmos, podemos decir que Merge Sort es eficiente en términos de tiempo y Insertion Sort es eficiente en términos de espacio.
- Método de clasificación: la clasificación por combinación es un método de clasificación externo en el que los datos que se van a clasificar no se pueden acomodar en la memoria y se necesita memoria auxiliar para la clasificación,
mientras que la clasificación por
inserción se basa en la idea de que se consume un elemento de los elementos de entrada . en cada iteración para encontrar su posición correcta, es decir, la posición a la que pertenece en una array ordenada. - Estabilidad: la ordenación por combinación es estable ya que dos elementos con el mismo valor aparecen en el mismo orden en la salida ordenada que en la array no ordenada de entrada,
mientras que la ordenación por
inserción toma tiempo O (N 2 ) en ambas estructuras de datos ( arreglo y lista vinculada ). Si la CPU tiene una función de movimiento de bloque de memoria eficiente, entonces la array puede ser más rápida. De lo contrario, probablemente no haya tanta diferencia horaria.
Representación tabular:
| Parámetros | Ordenar por fusión | Tipo de inserción |
|---|---|---|
| Complejidad en el peor de los casos | O(N*log N) | O(N 2 ) |
| Complejidad promedio del caso | O(N*log N) | O(N 2 ) |
| Complejidad del mejor caso | O(N*log N) | EN) |
| Complejidad del espacio auxiliar | EN) | O(1) |
| funciona bien en | En un gran conjunto de datos. | En un pequeño conjunto de datos. |
| Eficiencia | comparativamente eficiente. | comparativamente ineficiente. |
| Clasificación in situ | No | Sí |
| Paradigma del algoritmo | Divide y conquistaras | Enfoque incremental |
| Usos | Se utiliza para ordenar listas enlazadas en O(N*log N), para problemas de conteo de inversiones, clasificación externa, etc. | Se utiliza cuando el número de elementos es pequeño. También puede ser útil cuando la array de entrada está casi ordenada, solo unos pocos elementos están fuera de lugar en una array grande completa. |
Publicación traducida automáticamente
Artículo escrito por MohdArsalan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA