Este artículo proporcionará un procedimiento básico sobre cómo un principiante debe abordar un proyecto de Machine Learning y describir los pasos fundamentales involucrados. En el problema, nos centraremos en la clasificación de las flores de iris. Puede obtener información sobre el conjunto de datos aquí .
Muchos profesores y sitios web abordan este problema para demostrar los diversos matices involucrados en un proyecto de aprendizaje automático porque:
- Todos los atributos son numéricos y todos los atributos son de la misma escala y unidades.
- El problema en cuestión es un problema de clasificación y, por lo tanto, nos da la opción de explorar muchas métricas de evaluación.
- El conjunto de datos involucrado es pequeño y limpio y, por lo tanto, se puede manejar fácilmente.
Demostramos los siguientes pasos y los describimos en consecuencia a lo largo del camino.
Paso 1: Importación de las bibliotecas requeridas
Python3
import pandas as pd from pandas.plotting import scatter_matrix import matplotlib.pyplot as plt from sklearn import model_selection from sklearn.metrics import classification_report, confusion_matrix, accuracy_score from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn.neighbors import KNeighborsClassifier
Paso 2: cargando los datos
Python3
# dataset (csv file) path url = "https://raw.githubusercontent.com /jbrownlee/Datasets/master/iris.csv" # selectng necessary feature features = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class'] # reading the csv data = pd.read_csv(url, names = features)
Paso 3: Resumen de los datos
Este paso generalmente implica los siguientes pasos:
a) Echar un vistazo a los datos
Python3
data.head()
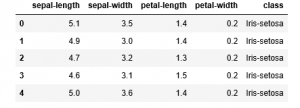
b) Hallar las dimensiones de los Datos
Python3
data.shape
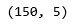
c) Resumen estadístico de todos los atributos
Python3
print(data.describe())
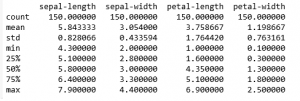
d) Clase de distribución de los Datos
Python3
print((data.groupby('class')).size())

Paso 4: Visualización de los datos
Este paso generalmente implica los siguientes pasos:
a) Trazado de gráficos univariados
Esto se hace para comprender la naturaleza de cada atributo.
Python3
data.plot(kind ='box', subplots = True, layout =(2, 2), sharex = False, sharey = False) plt.show()
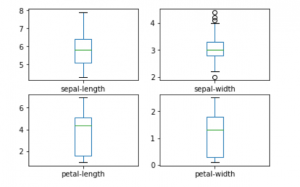
Python3
data.hist() plt.show()
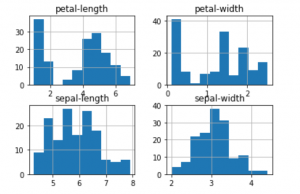
b) Trazado de gráficos multivariados
Esto se hace para comprender las relaciones entre diferentes características.
Python3
scatter_matrix(data) plt.show()
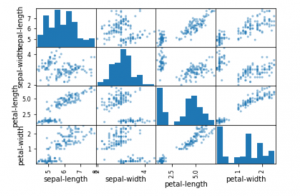
Paso 5: Entrenamiento y evaluación de nuestros modelos
Este paso normalmente contiene los siguientes pasos:
a) Dividir los datos de entrenamiento y prueba
Esto se hace para que una parte de los datos se oculte del algoritmo de aprendizaje.
Python3
y = data['class']
X = data.drop('class', axis = 1)
X_train, X_test, y_train, y_test = model_selection.train_test_split(
X, y, test_size = 0.25, random_state = 0)
print(X.head())
print('')
print(y.head())
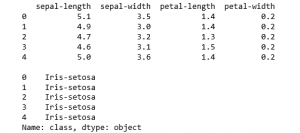
b) Construcción y validación cruzada del modelo
Python3
algorithms = []
scores = []
names = []
algorithms.append(('Logistic Regression', LogisticRegression()))
algorithms.append(('K-Nearest Neighbours', KNeighborsClassifier()))
algorithms.append(('Decision Tree Classifier', DecisionTreeClassifier()))
for name, algo in algorithms:
k_fold = model_selection.KFold(n_splits = 10, random_state = 0)
# Applying k-cross validation
cvResults = model_selection.cross_val_score(algo, X_train, y_train,
cv = k_fold, scoring ='accuracy')
scores.append(cvResults)
names.append(name)
print(str(name)+' : '+str(cvResults.mean()))

c) Comparar visualmente los resultados de los diferentes algoritmos
Python3
fig = plt.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(scores)
ax.set_xticklabels(names)
plt.show()

Paso 6: Hacer predicciones y evaluar las predicciones
Python3
for name, algo in algorithms:
clf = algo
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
pred_score = accuracy_score(y_test, y_pred)
print(str(name)+' : '+str(pred_score))
print('')
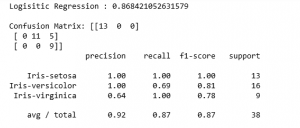
print('Confusion Matrix: '+str(confusion_matrix(y_test, y_pred)))
print(classification_report(y_test, y_pred))
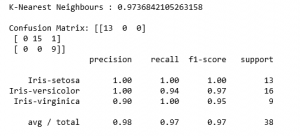
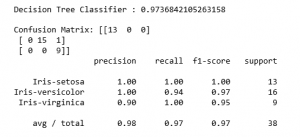
Referencia: https://machinelearningmastery.com/machine-learning-in-python-step-by-step/
Publicación traducida automáticamente
Artículo escrito por AlindGupta y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA