En este artículo vamos a ver cómo crear datos simulados para su clasificación en Python.
Usaremos la biblioteca sklearn que proporciona varios generadores para simular datos de clasificación.
Clasificación de etiqueta única
Aquí vamos a ver la clasificación single-label, para ello utilizaremos algunas técnicas de visualización.
Ejemplo 1: Usando make_circles()
make_circles genera datos de clasificación binaria 2d con un límite de decisión esférico.
Python3
from sklearn.datasets import make_circles import pandas as pd import matplotlib.pyplot as plt X, y = make_circles(n_samples=200, shuffle=True, noise=0.1, random_state=42) plt.scatter(X[:, 0], X[:, 1], c=y) plt.show()
Producción:
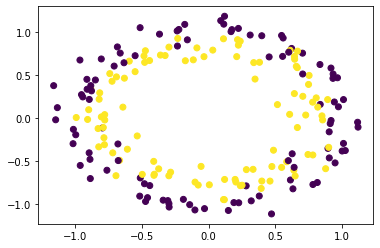
Ejemplo 2: Usando make_moons()
make_moons() genera datos de clasificación binaria 2d en forma de dos semicírculos intercalados.
Python3
from sklearn.datasets import make_moons import pandas as pd import matplotlib.pyplot as plt X, y = make_moons(n_samples=200, shuffle=True, noise=0.15, random_state=42) plt.scatter(X[:, 0], X[:, 1], c=y) plt.show()
Producción:
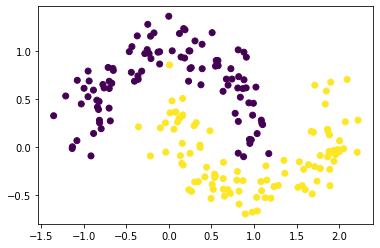
Ejemplo 3. Usar make_blobs()
make_blobs() genera datos en forma de blobs que se pueden usar para agrupar
Python3
from sklearn.datasets import make_blobs import pandas as pd import matplotlib.pyplot as plt X, y = make_blobs(n_samples=200, n_features=2, centers=3, shuffle=True, random_state=42) plt.scatter(X[:, 0], X[:, 1], c=y) plt.show()
Producción:
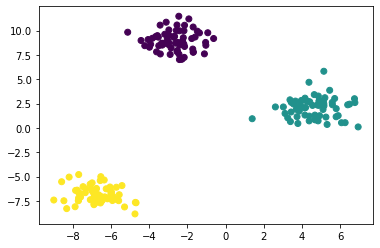
Ejemplo 4. Usando make_classification()
make_classification() genera un problema de clasificación aleatorio de n clases
Python3
from sklearn.datasets import make_classification import pandas as pd import matplotlib.pyplot as plt X, y = make_classification(n_samples=100, n_features=5, n_classes=2, n_informative=2, n_redundant=2, n_repeated=0, shuffle=True, random_state=42) pd.concat([pd.DataFrame(X), pd.DataFrame( y, columns=['Label'])], axis=1)
Producción:
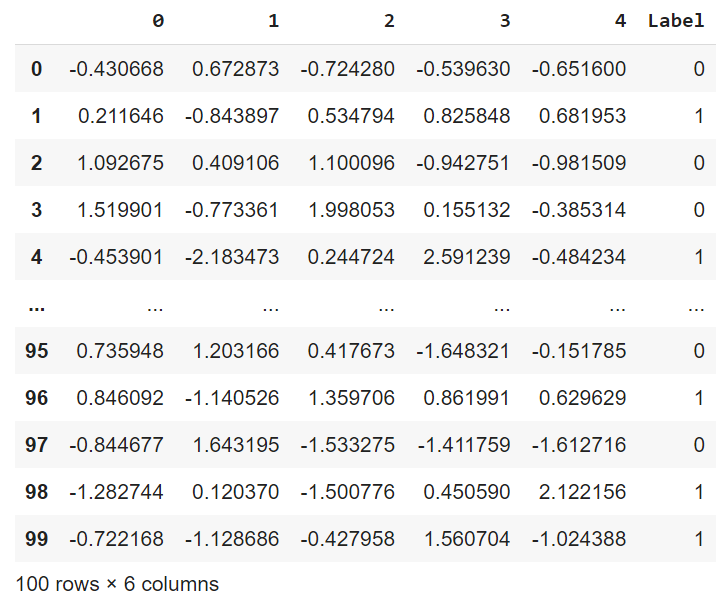
Clasificación de etiquetas múltiples
make_multilabel_classification() genera un problema aleatorio de clasificación de múltiples etiquetas.
Python3
from sklearn.datasets import make_multilabel_classification import pandas as pd import matplotlib.pyplot as plt X, y = make_multilabel_classification(n_samples=100, n_features=5, n_classes=2, n_labels=1, allow_unlabeled=False, random_state=42) pd.concat([pd.DataFrame(X), pd.DataFrame(y, columns=['L1', 'L2'])], axis=1)
Producción:
Publicación traducida automáticamente
Artículo escrito por dhwani_agarwal y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA