Aquí discutiremos cómo dividir un conjunto de datos en conjuntos de entrenamiento y prueba en Python. La división de prueba de tren se utiliza para estimar el rendimiento de los algoritmos de aprendizaje automático que se aplican a los algoritmos/aplicaciones basados en predicciones. Este método es un procedimiento rápido y fácil de realizar, de modo que podemos comparar los resultados de nuestro propio modelo de aprendizaje automático con los resultados de la máquina. De forma predeterminada, el conjunto de prueba se divide en el 30 % de los datos reales y el conjunto de entrenamiento se divide en el 70 % de los datos reales.
Necesitamos dividir un conjunto de datos en conjuntos de entrenamiento y prueba para evaluar qué tan bien funciona nuestro modelo de aprendizaje automático. El conjunto de trenes se utiliza para ajustar el modelo y se conocen las estadísticas del conjunto de trenes. El segundo conjunto se denomina conjunto de datos de prueba, este conjunto se utiliza únicamente para predicciones.
División de conjuntos de datos:
Scikit-learn alias sklearn es la biblioteca más útil y sólida para el aprendizaje automático en Python. La biblioteca scikit-learn nos proporciona el módulo model_selection en el que tenemos la función divisora train_test_split().
Sintaxis :
train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)
Parámetros:
- *arrays: entradas como listas, arrays, marcos de datos o arrays
- test_size: este es un valor flotante cuyo valor oscila entre 0.0 y 1.0. representa la proporción de nuestro tamaño de prueba. su valor predeterminado es ninguno.
- train_size: este es un valor flotante cuyo valor oscila entre 0.0 y 1.0. representa la proporción del tamaño de nuestro tren. su valor predeterminado es ninguno.
- random_state: este parámetro se usa para controlar la mezcla aplicada a los datos antes de aplicar la división. actúa como una semilla.
- Shuffle: este parámetro se usa para mezclar los datos antes de dividirlos. Su valor predeterminado es verdadero.
- estratificar: este parámetro se utiliza para dividir los datos de forma estratificada.
Ejemplo:
Para ver o descargar el archivo CSV utilizado en el ejemplo, haga clic aquí .

Código :
Python3
# import modules
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# read the dataset
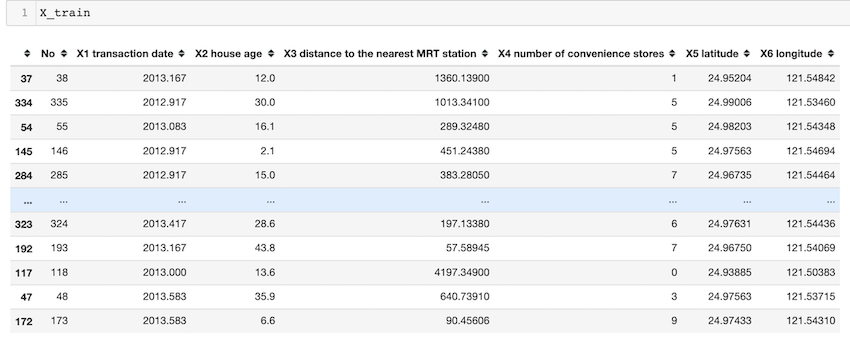
df = pd.read_csv('Real estate.csv')
# get the locations
X = df.iloc[:, :-1]
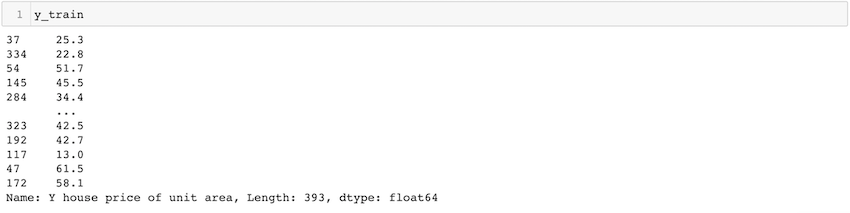
y = df.iloc[:, -1]
# split the dataset
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.05, random_state=0)
En el ejemplo anterior, importamos el paquete pandas y el paquete sklearn . después de eso, para importar el archivo CSV, usamos el método read_csv() . La variable df ahora contiene el marco de datos. en el ejemplo, «precio de la vivienda» es la columna que tenemos que predecir, por lo que tomamos esa columna como yy el resto de las columnas como nuestra variable X. test_size = 0.05 especifica que solo el 5% de todos los datos se toman como nuestro conjunto de prueba y el 95% como nuestro conjunto de tren. El estado aleatorio nos ayuda a obtener la misma división aleatoria cada vez.
Salida :
Publicación traducida automáticamente
Artículo escrito por isitapol2002 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA