Orange es una plataforma poderosa para realizar análisis y visualización de datos, ver el flujo de datos y ser más productivo. Proporciona una plataforma limpia y de código abierto. Fue desarrollado por la Universidad de Ljubljana bajo la licencia GPLv3.
Pasos de instalación
Paso 1: En primer lugar, instalaremos pip y otras dependencias antes de instalar Orange Tool.
sudo apt install build-essential python3-dev python3-pip
Para verificar la instalación, ejecute:
pip3 –versión

Paso 2: Ahora, instala la herramienta naranja.
pip3 instalar naranja3
Nota: este comando también instalará varias bibliotecas de aprendizaje automático y PyQt5 que pueden costarle datos adicionales.
Usando la herramienta naranja
Ejecute el siguiente comando en la línea de comandos:
python3 -m Naranja.lienzo
Widgets naranjas
Estos son los componentes básicos de los flujos de trabajo de datos del entorno de programación visual. Tenemos los siguientes widgets en naranja categorizados según su funcionalidad.
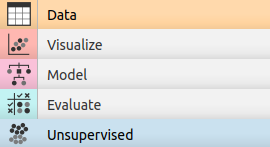
Datos
Estos widgets leen y muestran datos. Algunos ejemplos comunes son:
- Archivo: lee el archivo de datos de entrada y envía el conjunto de datos a su canal de salida.
- Importación de archivos CSV: lee archivos separados por comas y envía el conjunto de datos a su canal de salida.
- Conjuntos de datos: recupera conjuntos de datos seleccionados del servidor y los envía a la salida.
- Tabla de datos: recibe conjuntos de datos en su entrada y los presenta como una hoja de cálculo.
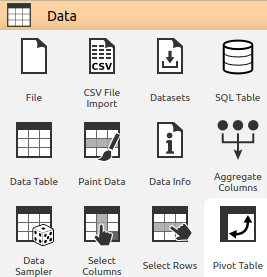
Visualizar
Estos widgets visualizan los datos dados a través de varios gráficos y barras. Algunos ejemplos comunes son:
- Box Plot: Muestra las distribuciones de los valores de los atributos.
- Distribuciones : Muestra la distribución de valores de atributos discretos o continuos.
- Gráfico de dispersión: proporciona una visualización de gráfico de dispersión bidimensional.
Modelo
Estos widgets aplican algoritmos de aprendizaje automático a los conjuntos de datos dados. Algunos ejemplos comunes son:
- Constante: Predice la clase o valor medio más frecuente del conjunto de entrenamiento.
- Regla CN2: Induce reglas a partir de datos utilizando el algoritmo CN2.
- kNN: Predice según las instancias de entrenamiento más cercanas.
- Random Forest: Predice utilizando un conjunto de árboles de decisión.
Evaluar
Estos widgets evalúan el resultado producido por el widget del modelo. Algunos ejemplos comunes son:
- Test and Score: prueba algoritmos de aprendizaje automático en datos.
- Predicciones: Muestra las predicciones de los modelos sobre los datos.
- Array de confusión: Muestra proporciones entre la clase predicha y la real.

sin supervisión
Estos widgets procesan datos no supervisados. Algunos ejemplos comunes son:
- Array de Distancia: Visualiza medidas de distancia en una array de distancia.
- Mapa de Distancia: Visualiza distancias entre objetos.
- k-Means: Aplica el algoritmo k-Means a los datos.
Publicación traducida automáticamente
Artículo escrito por ahampriyanshu y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA