Prerrequisitos: Regularización en ML
Sabemos que usamos la regularización para evitar el ajuste insuficiente y el ajuste excesivo mientras entrenamos nuestros modelos de Machine Learning. Y para este propósito, utilizamos principalmente dos tipos de métodos, a saber: regularización L1 y regularización L2.
Regularizador L1 :
||w|| 1 =( |w 1 |+|w 2 |+ . . . + |w n |
Regularizador L2 :
||w|| 2 =( |w 1 | 2 +|w 2 | 2 + . . . + |w n | 2 ) 1/2
(donde w 1 ,w 2 … w n son vectores de peso dimensional ‘ d ‘)
Ahora, mientras la optimización, que se realiza en base al concepto del algoritmo de descenso de gradiente, se ve que si usamos la regularización L1, aporta escasez a nuestro vector de peso al hacer que los pesos más pequeños sean cero. Veamos cómo pero primero entendamos algunos conceptos básicos.
Vector o array dispersos: Un vector o array con un máximo de sus elementos igual a cero se denomina vector o array dispersos.

Algoritmo de descenso de gradiente :
W t =W (t-1) – η* ( ∂L(w)/∂(w) ) W(t-1)
(donde η es un valor pequeño llamado tasa de aprendizaje)
Según el algoritmo de descenso de gradiente, obtenemos nuestra respuesta cuando se produce la convergencia. La convergencia ocurre cuando el valor de W t no cambia mucho con más iteraciones, o podemos decir cuando obtenemos un mínimo, es decir (∂(Pérdida)/∂w) W(t-1) se vuelve aproximadamente igual a 0 y, por lo tanto, W t ~ W t-1 .
Supongamos que tenemos un problema de optimización de regresión lineal (podemos tomar eso para cualquier modelo), con su ecuación como:
argmin(W) [ loss + (regularizer) ] i.e. Find that W which will minimize the loss function
Aquí ignoraremos el término de pérdida y solo nos centraremos en el término de regularización para facilitarnos el análisis de nuestra tarea.
Caso 1 (L1 tomado):
Optimisation equation= argmin(W) |W| (∂|W|/∂w) = 1 thus, according to GD algorithm Wt = Wt-1 - η*1
Aquí, como podemos ver, nuestra derivada de pérdida se vuelve constante, por lo que la condición de convergencia ocurre más rápido porque solo tenemos η en nuestro término de resta y no se multiplica por ningún valor menor de W. Por lo tanto, nuestro W t tiende hacia 0 en algunas iteraciones solamente. Pero esto conseguirá dificultar en nuestra condición que se produzca la convergencia como veremos en el siguiente caso.
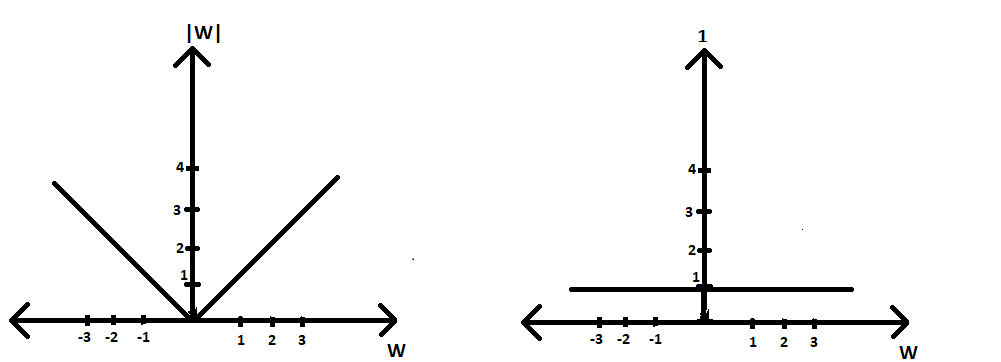
Gráfico del regularizador L1 frente a w(∂|W|/ ∂w) frente a w
Caso2 (L2 tomado) :
Optimisation equation=argmin(W) |W|2 (∂|W|2/∂W) = 2|W| thus, according to GD algorithm Wt = Wt-1 - 2*η*|W|
Por lo tanto, podemos ver que nuestro término derivado de pérdida no es constante y, por lo tanto, para valores más pequeños de W, nuestra condición de convergencia no ocurrirá más rápido (o tal vez en absoluto) porque tenemos un valor más pequeño de W que se multiplica con η y por lo tanto hace todo el término a ser restado aún más pequeño. Por lo tanto, después de algunas iteraciones, nuestro W t se convierte en un valor constante muy pequeño pero no cero. Por lo tanto, no contribuye a la escasez del vector de peso.
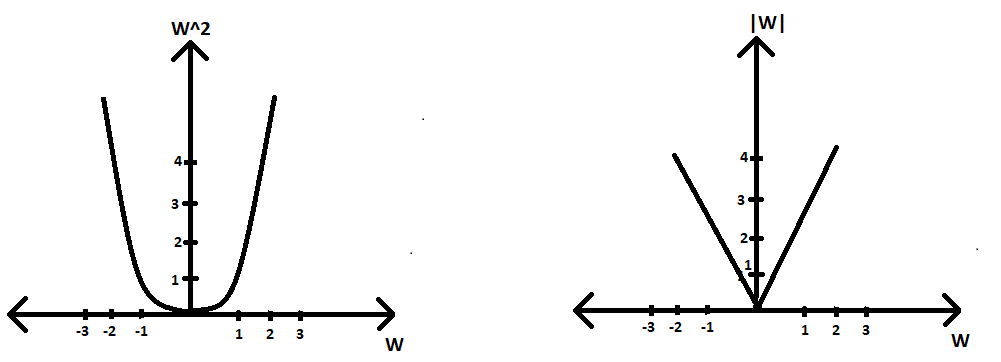
Gráfico de regularizador L2 vs w ; Lado derecho: Gráfico de ∂|W| 2 /∂W) contra w
Publicación traducida automáticamente
Artículo escrito por vishitabatra y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA