¿Sabía que un conjunto de algoritmos informáticos puede procesar una transmisión de video de una manera que les permite detectar actividades delictivas, controlar los atascos de tráfico e incluso detectar automáticamente eventos en transmisiones deportivas? Gracias a la aplicación del aprendizaje automático (ML), la idea de adquirir tantos datos de un simple video no parece tan poco realista. En este artículo, analizaremos la aplicación de la lógica prediseñada de un algoritmo de aprendizaje automático para la detección y segmentación de objetos en un video.
En particular, hablamos de cómo configurar Google Colaboratory para resolver tareas de procesamiento de video con aprendizaje automático. Aprenderá a usar este servicio de Google y la GPU NVIDIA Tesla K80 gratuita que proporciona para lograr sus propios objetivos en el entrenamiento de redes neuronales. Este artículo será útil para las personas que se están familiarizando con el aprendizaje automático y están considerando trabajar con el reconocimiento de imágenes y el procesamiento de videos.
Procesamiento de imágenes con recursos de hardware limitados
La tarea es reconocer personas en una grabación de video con la ayuda de algoritmos de aprendizaje automático (ML). Decidimos comenzar con lo básico. Primero, consideremos qué es realmente una grabación de video.
Desde un punto de vista técnico, cualquier grabación de video consiste en una serie de imágenes fijas en un formato particular que se comprime con un códec de video. En consecuencia, el reconocimiento de objetos en una transmisión de video se reduce a dividir la transmisión en imágenes o cuadros separados y aplicarles un algoritmo de reconocimiento de imágenes ML preentrenado.
Para hacer esto, decidimos usar una red neuronal del repositorio Mask_R-CNN para clasificar imágenes individuales. El repositorio contiene una implementación de una red neuronal convolucional en Python3, TensorFlow y Keras. Veamos qué salió de este plan.
Muestra de máscara_RCNN
Desarrollamos e implementamos una muestra simple de Mask_RCNN que recibió una imagen como entrada y reconoció objetos en ella. Creamos una muestra sobre la base de la descripción demo.ipynb tomada del repositorio Mask_R-CNN. Aquí está el código de nuestra muestra:
import os, sys
import random
import math
import numpy as np
import skimage.io
import matplotlib
import matplotlib.pyplot as plt
os.chdir("/content/drive/My Drive/Colab Notebooks/MRCNN_pure")
sys.path.append("/content/drive/My Drive/Colab Notebooks/MRCNN_pure")
# Root directory of the project
ROOT_DIR = os.path.abspath(".")
# Import Mask RCNN
sys.path.append(ROOT_DIR) # To find local version of the library
from mrcnn import utils
import mrcnn.model as modellib
from mrcnn import visualize
# Import COCO config
sys.path.append(os.path.join(ROOT_DIR, "samples/coco/")) # To find local version
import coco
# Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
# Local path to trained weights file
COCO_MODEL_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5")
# Download COCO trained weights from Releases if needed
if not os.path.exists(COCO_MODEL_PATH):
utils.download_trained_weights(COCO_MODEL_PATH)
# Directory of images to run detection on
IMAGE_DIR = os.path.join(ROOT_DIR, "images")
class InferenceConfig(coco.CocoConfig):
# Set batch size to 1 since we'll be running inference on
# one image at a time. Batch size = GPU_COUNT * IMAGES_PER_GPU
GPU_COUNT = 1
IMAGES_PER_GPU = 1
config = InferenceConfig()
config.display()
# Create model object in inference mode.
model = modellib.MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=config)
# Load weights trained on MS-COCO
model.load_weights(COCO_MODEL_PATH, by_name=True)
# COCO Class names
# Index of the class in the list is its ID. For example, to get ID of
# the teddy bear class, use: class_names.index('teddy bear')
class_names = ['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane',
'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird',
'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear',
'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie',
'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard',
'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed',
'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote',
'keyboard', 'cell phone', 'microwave', 'oven', 'toaster',
'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']
# Load a random image from the images folder
file_names = next(os.walk(IMAGE_DIR))[2]
image = skimage.io.imread(os.path.join(IMAGE_DIR, random.choice(file_names)))
# Run detection
results = model.detect([image], verbose=1)
# Visualize results
r = results[0]
visualize.display_instances(image, r['rois'], r['masks'],
r['class_ids'],class_names, r['scores'])
En este ejemplo, /content/drive/My Drive/Colab Notebooks/MRCNN_pure es la ruta a nuestro repositorio con Mask_R-CNN. Como resultado, obtuvimos lo siguiente:
Esta parte del código de demostración examina la carpeta de imágenes, selecciona aleatoriamente una imagen y la carga en nuestro modelo de red neuronal para su clasificación:
# Load a random image from the images folder file_names = next(os.walk(IMAGE_DIR))[2] image = skimage.io.imread(os.path.join(IMAGE_DIR, random.choice(file_names))) # Run detection results = model.detect([image], verbose = 1)
Modifiquemos la muestra Mask_R-CNN para que reconozca todas las imágenes en la carpeta de imágenes:
# Load a random image from the images folder file_names = next(os.walk(IMAGE_DIR))[2] for file_name in file_names: image = skimage.io.imread(os.path.join(IMAGE_DIR, file_name)) # Run detection results = model.detect([image], verbose = 1) # Visualize results r = results[0] visualize.display_instances(image, r['rois'], r['masks'], r['class_ids'],class_names, r['scores'])
Después de ejecutar el código de demostración durante cinco minutos, la consola mostró el siguiente resultado:
…
Procesando 1 imágenes
forma de imagen: (415, 640, 3) min: 0.00000 max: 255.00000 uint8
molded_images forma: (1, 1024, 1024, 3) min: -123.70000 max: 151.10000 float64
image_metas forma: (1, 93) min : 0.00000 máx.: 1024.00000 float64
forma de anclas: (1, 261888, 4) mín.: -0.35390 máx.: 1.29134 float32
Falla de segmentación (núcleo volcado)
Inicialmente, ejecutamos el código de demostración en una computadora con un Intel Core i5 y 8 GB de RAM sin una tarjeta gráfica discreta. El código fallaba cada vez en diferentes lugares, pero la mayoría de las veces fallaba en el marco de TensorFlow durante la asignación de memoria. Además, cualquier intento de ejecutar cualquier otro software durante el proceso de reconocimiento de imágenes ralentizaba la computadora hasta el punto de ser inútil.
Por lo tanto, nos enfrentamos a un problema grave: cualquier experimento para familiarizarnos con ML requería una tarjeta gráfica potente y más recursos de hardware. Sin esto, no podríamos ejecutar ninguna otra tarea mientras reconocíamos una gran cantidad de imágenes.
Aumentando nuestros recursos de hardware con Google Colaboratory
Decidimos ampliar nuestros recursos de hardware utilizando el servicio Colaboratory de Google, también conocido como Colab. Google Colab es un servicio gratuito en la nube que proporciona el uso de una CPU y una GPU, así como una instancia de máquina virtual preconfigurada. En concreto, Google ofrece la GPU NVIDIA Tesla K80 con 12 GB de memoria de vídeo dedicada, lo que convierte a Colab en una herramienta perfecta para experimentar con redes neuronales.
Antes de explicar cómo trabajar con este servicio de Google, nos gustaría destacar otras características beneficiosas de Colaboratory.
Al elegir Colab para sus experimentos de aprendizaje automático, obtendrá:
– soporte para Python 2.7 y Python 3.6 para que pueda mejorar sus habilidades de codificación;
– la capacidad de trabajar con el cuaderno Jupyter para que pueda crear, editar y compartir sus archivos .ipynb;
– la capacidad de conectarse a un tiempo de ejecución de Jupyter usando su máquina local;
– muchas bibliotecas preinstaladas, incluidas TensorFlow , Keras y OpenCV , así como la posibilidad de interactuar con sus bibliotecas personalizadas en Google Colaboratory;
– funcionalidad de carga para que pueda agregar su modelo entrenado;
– integración con GitHub para que pueda cargar cuadernos públicos de GitHub o guardar una copia de su archivo Colab en GitHub;
– visualización simple con bibliotecas tan populares como matplotlib ;
–formularios que se pueden utilizar para parametrizar código;
– la capacidad de almacenar cuadernos de Google Colab en su Google Drive.
Para comenzar a usar la GPU de Google Colab, solo necesita proporcionar acceso a su secuencia de comandos .ipynb que está implementada en un contenedor de Docker. El contenedor Docker se le asigna solo durante 12 horas. Todas las secuencias de comandos creadas por usted se almacenan de manera predeterminada en su Google Drive en la sección Cuadernos de Colab, que se crea automáticamente cuando se conecta a Colaboratory. Después de la expiración de 12 horas, se eliminarán todos sus datos en el contenedor. Puede evitar esto montando su Google Drive en su contenedor y trabajando con él. De lo contrario, el sistema de archivos de la imagen de Docker estará disponible solo por un período de tiempo limitado.
Configuración de Google Colab
Primero expliquemos cómo puede crear su cuaderno .ipynb. Abra Google Colaboratory aquí , seleccione la sección Google Drive y haga clic en NUEVO CUADERNO PYTHON 3:
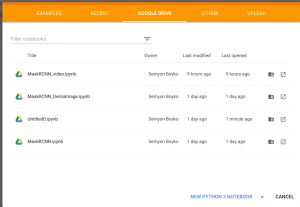
Cambia el nombre de tu cuaderno como quieras haciendo clic en el nombre del archivo. Ahora debe elegir su hardware. Para hacer esto, simplemente vaya a la sección Editar, busque Configuración del portátil, seleccione GPU como acelerador de hardware y guarde los cambios haciendo clic en GUARDAR.
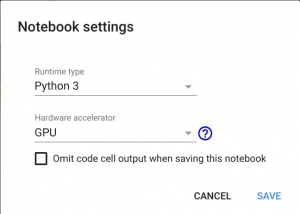
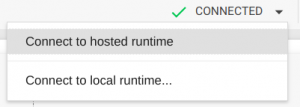
Después de guardar la nueva configuración, estará disponible un contenedor Docker con una tarjeta gráfica discreta. Se le notificará sobre esto con un mensaje «Conectado» en la parte superior derecha de la página:
![]()
Si no ve este mensaje, seleccione Conectar con tiempo de ejecución alojado.
Ahora puede montar su Google Drive en este contenedor para reubicar el código fuente y guardar los resultados de su trabajo en el contenedor. Para hacer esto, simplemente copie el código a continuación en la primera celda de la tabla y presione el botón Reproducir (o Shift + Enter).
Monte Google Drive ejecutando este código:
# from google.colab import drive
drive.mount('/content/drive')
Recibirá una solicitud de autorización. Haga clic en el enlace, autorice, copie el código de verificación, péguelo en el cuadro de texto en su script .ipynb y presione Entrar. Si la autorización es exitosa, su Google Drive se montará en la ruta /content/drive/My Drive. Para seguir el árbol de archivos, seleccione Archivos en el menú de la izquierda.
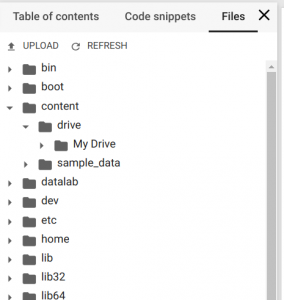
Ahora tiene un contenedor Docker con la GPU Tesla K80, su Google Drive como almacenamiento de archivos y el cuaderno .ipynb para la ejecución de scripts.
Uso de Google Colab para el reconocimiento de objetos
Ahora describiremos cómo ejecutar nuestra muestra Mask_R-CNN para el reconocimiento de objetos en Google Colab. Subimos el repositorio Mask_RCNN a nuestro Google Drive siguiendo la ruta /content/drive/My Drive/Colab Notebooks/.
Luego agregamos nuestro código de muestra al script .ipynb. Cuando haga esto, no olvide cambiar su ruta a la carpeta Mask_RCNN de esta manera:
os.chdir("/content/drive/My Drive/Colab Notebooks/MRCNN_pure")
sys.path.append("/content/drive/My Drive/Colab Notebooks/MRCNN_pure")
Si hace todo bien, los resultados de la ejecución del código le proporcionarán una imagen donde se detectan y reconocen todos los objetos.
También puede modificar el código de muestra para que procese todas las imágenes de prueba:
import os, sys
import random
import math
import numpy as np
import skimage.io
import matplotlib
import matplotlib.pyplot as plt
os.chdir("/content/drive/My Drive/Colab Notebooks/MRCNN_pure")
sys.path.append("/content/drive/My Drive/Colab Notebooks/MRCNN_pure")
# Root directory of the project
ROOT_DIR = os.path.abspath(".")
# Import Mask RCNN
sys.path.append(ROOT_DIR) # To find local version of the library
from mrcnn import utils
import mrcnn.model as modellib
from mrcnn import visualize
# Import COCO config
sys.path.append(os.path.join(ROOT_DIR, "samples/coco/")) # To find local version
import coco
# Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
# Local path to trained weights file
COCO_MODEL_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5")
# Download COCO trained weights from Releases if needed
if not os.path.exists(COCO_MODEL_PATH):
utils.download_trained_weights(COCO_MODEL_PATH)
# Directory of images to run detection on
IMAGE_DIR = os.path.join(ROOT_DIR, "images")
class InferenceConfig(coco.CocoConfig):
# Set batch size to 1 since we'll be running inference on
# one image at a time. Batch size = GPU_COUNT * IMAGES_PER_GPU
GPU_COUNT = 1
IMAGES_PER_GPU = 1
config = InferenceConfig()
config.display()
# Create model object in inference mode.
model = modellib.MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=config)
# Load weights trained on MS-COCO
model.load_weights(COCO_MODEL_PATH, by_name=True)
# COCO Class names
# Index of the class in the list is its ID. For example, to get ID of
# the teddy bear class, use: class_names.index('teddy bear')
class_names = ['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane',
'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird',
'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear',
'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie',
'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard',
'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed',
'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote',
'keyboard', 'cell phone', 'microwave', 'oven', 'toaster',
'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']
# Load a random image from the images folder
file_names = next(os.walk(IMAGE_DIR))[2]
for file_name in file_names:
image = skimage.io.imread(os.path.join(IMAGE_DIR, file_name))
# Run detection
results = model.detect([image], verbose=1)
# Visualize results
r = results[0]
visualize.display_instances(image, r['rois'], r['masks'],
r['class_ids'],class_names, r['scores'])
Usando la detección de objetos en Google Colab, recibimos los resultados con objetos reconocidos rápidamente, mientras que nuestra computadora continuó funcionando como de costumbre incluso durante el proceso de reconocimiento de imágenes.
Uso de Google Colab para el procesamiento de videos
Veamos cómo aplicamos este método para reconocer personas en una transmisión de video. Subimos un archivo de video de prueba a nuestro Google Drive. Para entrenar nuestro script para que funcione con una transmisión de video, usamos OpenCV, una popular biblioteca de visión por computadora de código abierto.
No necesitamos todo el código que leyó e implementó el modelo de reconocimiento en una imagen. Entonces, en lugar de abrir el archivo de video, ejecutamos la transmisión de video y movemos su puntero al cuadro 1,000 ya que no hay objetos para reconocer en la introducción de la grabación.
import cv2 ... VIDEO_STREAM = "/content/drive/My Drive/Colab Notebooks/Millery.avi" VIDEO_STREAM_OUT = "/content/drive/My Drive/Colab Notebooks/Result.avi" ... # initialize the video stream and pointer to output video file vs = cv2.VideoCapture(VIDEO_STREAM) writer = None vs.set(cv2.CAP_PROP_POS_FRAMES, 1000);
Luego procesamos 20 000 fotogramas con nuestro modelo de red neuronal. El objeto OpenCV nos permite obtener imágenes por cuadro del archivo de video usando el método read(). La imagen recibida se pasa al método model.detect() y los resultados se visualizan con la función visualize.display_instances().
Sin embargo, enfrentamos un problema: la función display_instances() del repositorio Mask_RCNN refleja los objetos detectados en la imagen, pero la imagen no regresa. Decidimos simplificar la función display_instances() y hacer que devuelva la imagen con los objetos mostrados:
def display_instances(image, boxes, masks, ids, names, scores):
"""
take the image and results and apply the mask, box, and Label
"""
n_instances = boxes.shape[0]
colors = visualize.random_colors(n_instances)
if not n_instances:
print('NO INSTANCES TO DISPLAY')
else:
assert boxes.shape[0] == masks.shape[-1] == ids.shape[0]
for i, color in enumerate(colors):
if not np.any(boxes[i]):
continue
y1, x1, y2, x2 = boxes[i]
label = names[ids[i]]
score = scores[i] if scores is not None else None
caption = '{} {:.2f}'.format(label, score) if score else label
mask = masks[:, :, i]
image = visualize.apply_mask(image, mask, color)
image = cv2.rectangle(image, (x1, y1), (x2, y2), color, 2)
image = cv2.putText(
image, caption, (x1, y1), cv2.FONT_HERSHEY_COMPLEX, 0.7, color, 2
)
return image
Después del procesamiento, los cuadros deben volver a unirse en un nuevo archivo de video. También podemos hacer esto con la biblioteca OpenCV. Todo lo que tenemos que hacer es asignar el objeto VideoWriter de la biblioteca OpenCV:
fourcc = cv2.VideoWriter_fourcc(*"XVID") writer = cv2.VideoWriter(VIDEO_STREAM_OUT, fourcc, 30, (masked_frame.shape[1], masked_frame.shape[0]), True)
usando el tipo de video que proporcionamos para la entrada. Obtenemos el tipo de archivo de video con la ayuda del comando ffprobe :
ffprobe Result.avi
…
Duración: N/A, inicio: 0.000000, tasa de bits: N/A
Transmisión #0:0: Video: mpeg4 (Perfil simple) (XVID / 0x44495658), yuv420p, 640×272 [SAR 1:1 DAR 40:17], 30 fps, 30 tbr, 30 tbn, 30 tbc
El objeto recibido se puede utilizar para la grabación por cuadro: escritor.escribir(masked_frame).
Al comienzo de la secuencia de comandos, debemos especificar las rutas a los archivos de video de destino para su procesamiento: VIDEO_STREAM y VIDEO_STREAM_OUT.
Aquí está el script completo que desarrollamos para el reconocimiento de video:
from google.colab import drive
drive.mount('/content/drive')
import os, sys
import random
import math
import numpy as np
import skimage.io
import matplotlib
import matplotlib.pyplot as plt
import cv2
from matplotlib.patches import Polygon
os.chdir("/content/drive/My Drive/Colab Notebooks/MRCNN_pure")
sys.path.append("/content/drive/My Drive/Colab Notebooks/MRCNN_pure")
VIDEO_STREAM = "/content/drive/My Drive/Colab Notebooks/Millery.avi"
VIDEO_STREAM_OUT = "/content/drive/My Drive/Colab Notebooks/Result.avi"
# Root directory of the project
ROOT_DIR = os.path.abspath(".")
# Import Mask RCNN
sys.path.append(ROOT_DIR) # To find local version of the library
from mrcnn import utils
import mrcnn.model as modellib
from mrcnn import visualize
# Import COCO config
sys.path.append(os.path.join(ROOT_DIR, "samples/coco/")) # To find local version
import coco
# Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
# Local path to trained weights file
COCO_MODEL_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5")
# Download COCO trained weights from Releases if needed
if not os.path.exists(COCO_MODEL_PATH):
utils.download_trained_weights(COCO_MODEL_PATH)
# Directory of images to run detection on
IMAGE_DIR = os.path.join(ROOT_DIR, "images")
class InferenceConfig(coco.CocoConfig):
# Set batch size to 1 since we'll be running inference on
# one image at a time. Batch size = GPU_COUNT * IMAGES_PER_GPU
GPU_COUNT = 1
IMAGES_PER_GPU = 1
def display_instances(image, boxes, masks, ids, names, scores):
"""
take the image and results and apply the mask, box, and Label
"""
n_instances = boxes.shape[0]
colors = visualize.random_colors(n_instances)
if not n_instances:
print('NO INSTANCES TO DISPLAY')
else:
assert boxes.shape[0] == masks.shape[-1] == ids.shape[0]
for i, color in enumerate(colors):
if not np.any(boxes[i]):
continue
y1, x1, y2, x2 = boxes[i]
label = names[ids[i]]
score = scores[i] if scores is not None else None
caption = '{} {:.2f}'.format(label, score) if score else label
mask = masks[:, :, i]
image = visualize.apply_mask(image, mask, color)
image = cv2.rectangle(image, (x1, y1), (x2, y2), color, 2)
image = cv2.putText(
image, caption, (x1, y1), cv2.FONT_HERSHEY_COMPLEX, 0.7, color, 2
)
return image
config = InferenceConfig()
config.display()
# Create model object in inference mode.
model = modellib.MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=config)
# Load weights trained on MS-COCO
model.load_weights(COCO_MODEL_PATH, by_name=True)
# COCO Class names
# Index of the class in the list is its ID. For example, to get ID of
# the teddy bear class, use: class_names.index('teddy bear')
class_names = ['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane',
'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird',
'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear',
'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie',
'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard',
'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed',
'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote',
'keyboard', 'cell phone', 'microwave', 'oven', 'toaster',
'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']
# Initialize the video stream and pointer to output video file
vs = cv2.VideoCapture(VIDEO_STREAM)
writer = None
vs.set(cv2.CAP_PROP_POS_FRAMES, 1000);
i = 0
while i < 20000:
# read the next frame from the file
(grabbed, frame) = vs.read()
i += 1
# If the frame was not grabbed, then we have reached the end
# of the stream
if not grabbed:
print ("Not grabbed.")
break;
# Run detection
results = model.detect([frame], verbose=1)
# Visualize results
r = results[0]
masked_frame = display_instances(frame, r['rois'], r['masks'], r['class_ids'],
class_names, r['scores'])
# Check if the video writer is None
if writer is None:
# Initialize our video writer
fourcc = cv2.VideoWriter_fourcc(*"XVID")
writer = cv2.VideoWriter(VIDEO_STREAM_OUT, fourcc, 30,
(masked_frame.shape[1], masked_frame.shape[0]), True)
# Write the output frame to disk
writer.write(masked_frame)
# Release the file pointers
print("[INFO] cleaning up...")
writer.release()
Conclusión:
En este artículo, le mostramos cómo aprovechamos Google Colab y le explicamos cómo puede hacer lo siguiente:
Use una GPU Tesla K80 gratuita proporcionada por Google Colab
Clasifique imágenes con la red neuronal Mask_RCNN y Google Colab
Clasifique objetos en una transmisión de video usando Mask_RCNN, Google Colab y la biblioteca OpenCV
Publicación traducida automáticamente
Artículo escrito por RyanThompson y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA