KNN es un algoritmo de aprendizaje automático que se usa tanto para problemas de clasificación (usando KNearestClassifier) como de regresión (usando KNearestRegressor). En el algoritmo KNN, K es el hiperparámetro . Elegir el valor correcto de K importa. Se dice que un modelo de aprendizaje automático tiene una complejidad de modelo alta si el modelo construido tiene un sesgo bajo y una varianza alta.
Lo sabemos,
- Alto sesgo y baja varianza = modelo de ajuste insuficiente.
- Sesgo bajo y varianza alta = modelo sobreajustado. [ Modelo de alta complejidad indicado ].
- Low Bias y Low Variance = Modelo de mejor ajuste. [Esto es preferible].
- Alta precisión de entrenamiento y Baja precisión de la prueba (precisión fuera de la muestra) = Varianza alta = Modelo sobreajustado = Más complejidad del modelo.
- Precisión de entrenamiento baja y precisión de prueba baja (precisión fuera de la muestra) = sesgo alto = modelo de ajuste insuficiente.
Código: Para comprender cómo el valor K en el algoritmo KNN afecta la complejidad del modelo.
# This code may not run on GFG ide
# As required modules are not found.
# Import required modules
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
from sklearn.neighbors import KNeighborsRegressor
from sklearn.model_selection import train_test_split
import numpy as np
# Synthetically Create Data Set
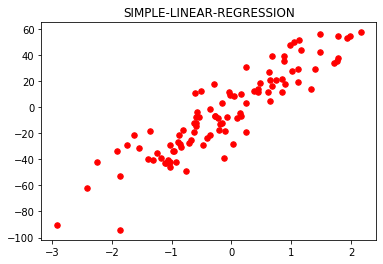
plt.figure()
plt.title('SIMPLE-LINEAR-REGRESSION')
x, y = make_regression(
n_samples = 100, n_features = 1,
n_informative = 1, noise = 15, random_state = 3)
plt.scatter(x, y, color ='red', marker ='o', s = 30)
# Train the model.
knn = KNeighborsRegressor(n_neighbors = 7)
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size = 0.2, random_state = 0)
knn.fit(x_train, y_train)
predict = knn.predict(x_test)
print('Test Accuracy:', knn.score(x_test, y_test))
print('Training Accuracy:', knn.score(x_train, y_train))
# Plot The Output
x_new = np.linspace(-3, 2, 100).reshape(100, 1)
predict_new = knn.predict(x_new)
plt.plot(
x_new, predict_new, color ='blue',
label ="K = 7")
plt.scatter(x_train, y_train, color ='red' )
plt.scatter(x_test, predict, marker ='^', s = 90)
plt.legend()
Producción:
Test Accuracy: 0.6465919540035108 Training Accuracy: 0.8687977824212627
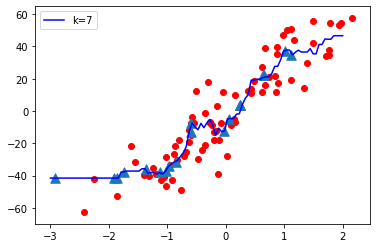
Ahora vamos a variar el valor de K (Hiperparámetro) de Bajo a Alto y observemos la complejidad del modelo
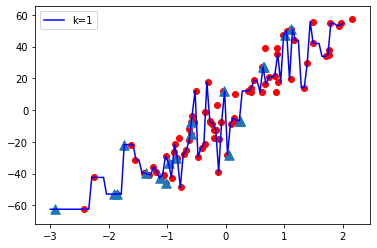
K = 1
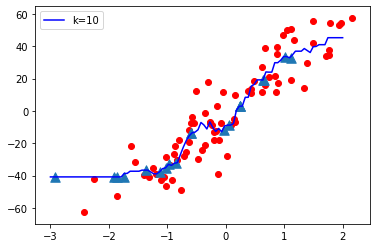
K = 10
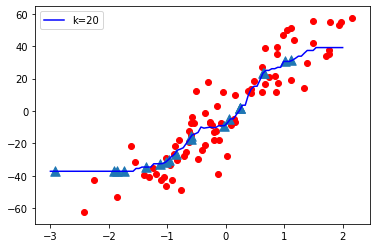
K = 20
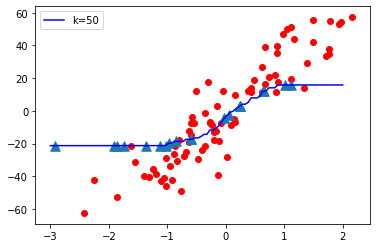
K = 50
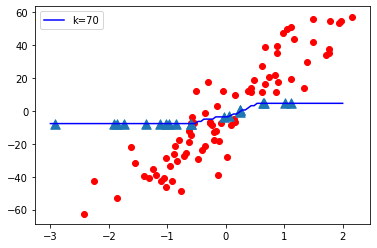
K = 70
Observaciones:
- Cuando el valor de K es pequeño, es decir, K=1, la complejidad del modelo es alta (sobreajuste o alta varianza).
- Cuando el valor de K es muy grande, es decir, K = 70, la complejidad del modelo disminuye (ajuste insuficiente o alto sesgo).
Conclusión:
A medida que el valor K se vuelve pequeño, la complejidad del modelo aumenta y, a medida que el valor K se vuelve grande, la complejidad del modelo disminuye.
Código: Consideremos la siguiente trama
# This code may not run on GFG
# As required modules are not found.
# To plot test accuracy and train accuracy Vs K value.
p = list(range(1, 31))
lst_test =[]
lst_train =[]
for i in p:
knn = KNeighborsRegressor(n_neighbors = i)
knn.fit(x_train, y_train)
z = knn.score(x_test, y_test)
t = knn.score(x_train, y_train)
lst_test.append(z)
lst_train.append(t)
plt.plot(p, lst_test, color ='red', label ='Test Accuracy')
plt.plot(p, lst_train, color ='b', label ='Train Accuracy')
plt.xlabel('K VALUES --->')
plt.title('FINDING BEST VALUE FOR K')
plt.legend()
Producción:
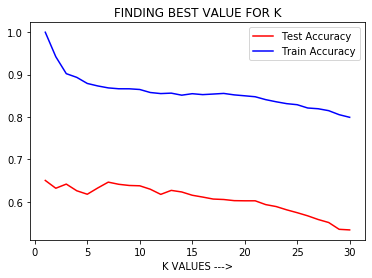
Observación:
del gráfico anterior, podemos concluir que cuando K es pequeño, es decir, K=1, la precisión del entrenamiento es alta pero la precisión de la prueba es baja, lo que significa que el modelo se ajusta en exceso (varianza alta o complejidad del modelo alta ). Cuando el valor de K es grande, es decir, K = 50, la precisión del entrenamiento es baja y la precisión de la prueba es baja, lo que significa que el modelo no se ajusta bien (sesgo alto o complejidad del modelo baja).
Por lo tanto , es necesario ajustar los hiperparámetros , es decir, para seleccionar el mejor valor de K en el algoritmo KNN para el cual el modelo tiene un sesgo bajo y una varianza baja y da como resultado un buen modelo con una precisión alta fuera de la muestra.
Podemos usar GridSearchCV o RandomSearchCv para encontrar el mejor valor del hiperparámetro K.