El tema del aprendizaje por refuerzo ha crecido absolutamente en los últimos años desde los asombrosos resultados con los viejos juegos de Atari, la victoria de Deep Minds con los impresionantes avances de AlphaGo en la manipulación de brazos robóticos que incluso supera a los jugadores profesionales en 1v1 dota. Desde el impresionante avance en el desafío de clasificación de ImageNet en 2012, los éxitos del aprendizaje profundo supervisado han seguido acumulándose, y personas de todos los ámbitos de la vida han comenzado a usar redes neuronales profundas para resolver una variedad de problemas nuevos, incluido cómo aprender comportamiento inteligente. en entornos dinámicos complejos.
¿Por qué el aprendizaje supervisado es diferente del aprendizaje por refuerzo?
Como resultado, el aprendizaje supervisado se usa en la mayoría de las aplicaciones de aprendizaje automático. Esto significa que proporciona una entrada a su modelo de red neuronal y sabe qué salida debe crear su modelo. Como resultado, puede calcular gradientes utilizando un enfoque de retropropagación para entrenar la red para producir los resultados deseados. Entonces, supongamos que quiere enseñarle a una red neuronal a jugar ping en un entorno supervisado, conseguiría un buen jugador humano para jugar pong durante un par de horas y crearía un conjunto de datos donde registra todos los fotogramas que el humano ve en la pantalla, así como las acciones que realiza en respuesta a esos fotogramas. Entonces, sea lo que sea que esté impulsando la flecha hacia arriba o hacia abajo, podemos alimentar esos marcos de entrada en una red neuronal muy simple, que puede producir dos comportamientos simples en la salida. Elegirá la acción arriba o abajo,
Sin embargo, hay dos inconvenientes significativos en este enfoque:
- El aprendizaje supervisado requiere la creación de un conjunto de datos para entrenar, lo que no siempre es una tarea fácil.
- Si entrena su modelo de red neuronal para simplemente imitar bien las acciones del jugador humano, su agente nunca podrá ser mejor jugando al pong que ese jugador humano. Por ejemplo, si desea entrenar una red neuronal para que sea mejor jugando al ping que ese jugador humano.
Funcionamiento del aprendizaje por refuerzo:
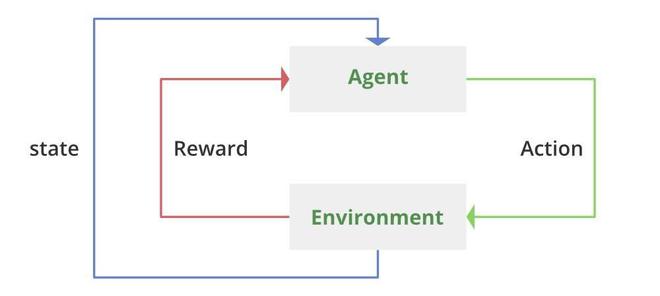
Existe, afortunadamente, y se conoce como aprendizaje por refuerzo. Como resultado, el marco y el aprendizaje por refuerzo son sorprendentemente similares al marco de aprendizaje supervisado. Entonces todavía tenemos un marco de entrada, lo ejecutamos a través de un modelo de red neuronal y la red produce una acción de salida, ya sea hacia arriba o hacia abajo. Pero ahora no conocemos la etiqueta de destino, por lo que no sabemos si deberíamos haber subido o bajado en cualquier caso, ya que no tenemos un conjunto de datos para entrenar. La red de políticas es la red en el aprendizaje por refuerzo que convierte marcos de entrada en acciones de salida. Una estrategia conocida como Gradientes de políticaes ahora una de las formas más sencillas de entrenar una red de políticas. En gradientes de políticas, la estrategia es comenzar con una red completamente aleatoria. Alimentas un marco desde el motor del juego a esa red. Genera un aumento aleatorio con una actividad de la que eres consciente, ya sea hacia arriba o hacia abajo. volver al motor del juego con esa acción El bucle continúa mientras el motor del juego genera el siguiente cuadro y la red, en este ejemplo, podría ser una red completamente conectada.
Sin embargo, también puede usar convoluciones allí, y la salida de su red ahora consistirá en dos números: la probabilidad de subir y la probabilidad de bajar. Mientras entrena, tomará muestras de la distribución para que no siempre esté repitiendo exactamente las mismas actividades. Esto ayudará a su agente a explorar el mundo de manera más aleatoria, con la esperanza de descubrir mayores recompensas y, lo que es más importante, un mejor comportamiento. Como queremos que nuestro agente pueda aprender completamente por sí mismo, la única información que le daremos es el marcador del juego. Entonces, cada vez que nuestro agente marca un gol, recibe una recompensa de +1, y si el oponente marca un gol, nuestro agente recibe una penalización de menos 1, y el objetivo principal del agente es optimizar su política para obtener la mayor recompensa posible. Entonces, para capacitar a nuestra red de políticas, Lo primero que haremos será recopilar una gran cantidad de datos. Simplemente ejecute algunos de esos marcos de juego en su red, seleccione acciones aleatorias y vuelva a introducirlas en el motor para generar una serie de juegos de pong aleatorios. Obviamente, debido a que nuestro agente aún no ha aprendido nada valioso, perderá la mayoría de esos juegos, pero el punto es que nuestro agente podría tener suerte y seleccionar una serie completa de acciones que realmente lo lleven a un gol al azar. En este caso, nuestro agente será recompensado y es importante recordar que para cada episodio, independientemente de si deseamos una recompensa positiva o negativa, ya podemos calcular los gradientes que harán que las acciones de nuestro agente sean más probables en el futuro. esto es critico, como gradientes de política emplearemos gradientes normales para aumentar la probabilidad de esos actos en el futuro para cada episodio cuando tengamos una recompensa positiva. Cuando obtengamos un negativo, aplicaremos el mismo gradiente, pero lo multiplicaremos por menos uno, y este signo menos asegurará que todas las acciones que hicimos en un episodio particularmente horrible sean menos probables en el futuro. Como resultado, al entrenar nuestra red de políticas, los actos que conducen a recompensas negativas se irán filtrando gradualmente, mientras que las acciones que conducen a buenas recompensas serán cada vez más probables, por lo que, en cierto modo, nuestro agente está aprendiendo a jugar al pong.
El inconveniente de los gradientes de política:
Entonces, podemos utilizar gradientes de políticas para entrenar una red neuronal para jugar al ping pong. Pero hay algunos inconvenientes sustanciales al emplear esta estrategia, como siempre los hay. Volvamos al pong una vez más. Imagina que tu agente ha estado practicando durante un tiempo y en realidad es bastante bueno jugando al pong, haciendo rebotar la pelota de un lado a otro, pero luego comete un error al final del episodio. Permite el paso del balón y recibe penalti. El problema con los gradientes de políticas es que asumen que debido a que perdimos ese episodio, todos los actos que hicimos allí deben haber sido malos, y esto disminuirá la probabilidad de repetir esos actos en el futuro.
Dilema de asignación de crédito:
Pero tenga en cuenta que durante la mayoría de las partes de ese episodio, lo hicimos extremadamente bien, por lo que no queremos reducir la posibilidad de esos comportamientos, lo que se conoce como el dilema de la asignación de créditos .en el aprendizaje por refuerzo. Es la situación en la que, si obtienes una recompensa al final de tu episodio, ¿cuáles fueron los actos particulares que llevaron a ese premio específico? Este problema se debe totalmente al hecho de que tenemos una configuración de recompensa escasa. Entonces, en lugar de recibir una recompensa por cada acción individual, solo recibimos una recompensa después de un episodio completo, y nuestro agente debe averiguar qué elemento de su secuencia de acción está causando la recompensa que finalmente recibe, como en el ejemplo de punk. Por ejemplo, nuestro agente debe entender que solo las actividades que preceden inmediatamente al impacto de la pelota son realmente cruciales; todo lo demás después de que la pelota haya volado es irrelevante para el pago final. Como resultado de esta configuración de recompensa escasa, los algoritmos de aprendizaje por refuerzo a menudo se muestran ineficientes,
Algoritmos de aprendizaje de refuerzo de venganza de Montezuma
Al comparar la eficiencia de los algoritmos de aprendizaje por refuerzo con el aprendizaje humano, resulta que la configuración de recompensa escasa falla por completo en algunas circunstancias extremas. En el juego Montezuma’s Revenge, la misión del agente es sortear una serie de escaleras, saltar sobre una calavera, recuperar una llave y luego viajar a la puerta para pasar al siguiente nivel. El problema es que al realizar actos aleatorios, su agente nunca verá una sola recompensa porque sabe que la secuencia de actividades requerida para obtener esa recompensa es demasiado complicada. Con acciones aleatorias, nunca llegará allí y su gradiente de política nunca recibirá una sola recompensa positiva, por lo que no tendrá idea de qué hacer. Lo mismo ocurre con la robótica, donde podría querer entrenar un brazo robótico para recoger un objeto y apilarlo encima de otra cosa. El robot promedio tiene aproximadamente siete articulaciones que se pueden mover, por lo que tiene mucho espacio de acción. Si solo le otorga una recompensa positiva cuando ha apilado con éxito un bloque al realizar una exploración aleatoria, nunca verá ninguno de los beneficios. También vale la pena señalar cómo se compara esto con los logros habituales de aprendizaje profundo supervisado que vemos en áreas como la visión artificial. La razón por la que la visión por computadora funciona tan bien es que cada cuadro de entrada tiene una etiqueta de destino, lo que permite un descenso de gradiente muy eficiente utilizando técnicas como la retropropagación. En un escenario de aprendizaje por refuerzo, por otro lado, estás lidiando con el gran problema de nunca verá ninguno de los beneficios. También vale la pena señalar cómo se compara esto con los logros habituales de aprendizaje profundo supervisado que vemos en áreas como la visión artificial. La razón por la que la visión por computadora funciona tan bien es que cada cuadro de entrada tiene una etiqueta de destino, lo que permite un descenso de gradiente muy eficiente utilizando técnicas como la retropropagación. En un escenario de aprendizaje por refuerzo, por otro lado, estás lidiando con el gran problema de nunca verá ninguno de los beneficios. También vale la pena señalar cómo se compara esto con los logros habituales de aprendizaje profundo supervisado que vemos en áreas como la visión artificial. La razón por la que la visión por computadora funciona tan bien es que cada cuadro de entrada tiene una etiqueta de destino, lo que permite un descenso de gradiente muy eficiente utilizando técnicas como la retropropagación. En un escenario de aprendizaje por refuerzo, por otro lado, estás lidiando con el gran problema deajuste de recompensa escasa . Por eso, a pesar de que algo tan simple como apilar un bloque encima de otro parece bastante difícil incluso para el aprendizaje profundo de última generación, el método habitual para resolver el problema de las escasas recompensas ha sido utilizar recompensa la conformación.

La venganza de Moctezuma
Chip de recompensa:
La práctica de crear manualmente una función de recompensa que tiene que dirigir su política a algún comportamiento deseado se conoce como chip de recompensa . Por ejemplo, en Montezuma’s Revenge, puede ofrecerle a su agente un premio cada vez que evite la calavera o alcance la llave, y estas recompensas adicionales alentarán a su política a comportarse de cierta manera.
Si bien esto obviamente facilita que su política converja en el comportamiento previsto, la configuración de recompensas tiene una serie de inconvenientes:
- Para empezar, el modelado de recompensas es un proceso específico que debe completarse para cada entorno nuevo en el que desee entrenar una política. Si usa el punto de referencia de Atari como ejemplo, tendría que crear un sistema de recompensas diferente para cada uno de esos juegos, que simplemente no es escalable.
- El segundo problema es que la configuración de recompensas está plagada de lo que se conoce como el problema de alineación. Cuando se trata de dar forma a su función de recompensa, resulta que la forma de recompensa es bastante difícil en muchas circunstancias. Su agente ideará algún plan ingenioso para asegurarse de que recibe una gran suma de dinero sin hacer nada. En cierto modo, la política simplemente se adapta demasiado a esa función de recompensa única que diseñó, en lugar de generalizarse al comportamiento anticipado que tenía en mente.
Hay muchos ejemplos divertidos de modelado de recompensas que salió mal. Por ejemplo, si un agente fue entrenado para saltar y la función de recompensa era la distancia entre sus pies y el suelo, el agente aprendió a desarrollar un cuerpo muy alto y a hacer una especie de voltereta hacia atrás para asegurarse de que sus pies estuvieran muy lejos del suelo. . Mire las ecuaciones a continuación para una función de recompensa con forma para un trabajo de control robótico para tener una idea de cuán difícil puede ser dar forma a la recompensa.



Uno solo puede imaginar cuánto esfuerzo dedicaron los investigadores a desarrollar este mecanismo de recompensa exacto para lograr el comportamiento deseado.
Finalmente, en algunas circunstancias, como AlphaGo, no desea realizar ninguna configuración de recompensa porque limitará su política al comportamiento humano, lo que no siempre es deseable. Entonces, el dilema en el que nos encontramos ahora es que sabemos que es difícil entrenar en un entorno escasamente poblado, pero también es difícil crear una función de recompensa, lo que no siempre queremos hacer. Muchas fuentes de Internet describen el aprendizaje por refuerzo como una especie de salsa mágica de IA que le permite al agente aprender de sí mismo o mejorar su forma anterior, pero la realidad es que la mayoría de estos avances son el resultado del trabajo de algunas de las mentes más brillantes del mundo. Este Dia. Hay mucha ingeniería dura detrás de escena, así que creo que uno de los aspectos más difíciles de navegar por nuestro panorama digital es separar la realidad de la ficción en este mar de clickbait alimentado por el negocio de la publicidad. El robot Atlas de Boston Dynamics es un gran ejemplo de lo que estoy hablando. Entonces, si sales a la calle y le preguntas a mil personas quién tiene los robots más avanzados en la actualidad, lo más probable es que señalen a Atlas de Boston Dynamics porque todos han visto el video de él haciendo una voltereta hacia atrás. Sin embargo, si considera en qué es realmente bueno Boston Dynamics, es muy poco probable que haya mucho aprendizaje profundo si observa sus artículos anteriores en el historial de investigación. No me malinterpreten, están haciendo mucha robótica avanzada, pero no hay mucho comportamiento autónomo o toma de decisiones inteligente en esos robots, así que no me malinterpretes. Boston Dynamics es una excelente empresa de robótica, pero las impresiones que han generado en los medios pueden resultar desconcertantes para muchas personas que desconocen lo que sucede detrás de escena. No obstante, dado el estado actual de la investigación, no debemos desdeñar los posibles peligros que estas tecnologías pueden plantear. Es genial que más personas se interesen en la investigación de seguridad de la IA porque las preocupaciones como las armas autónomas y la vigilancia generalizada deben manejarse con seriedad. La única esperanza que tenemos es que el derecho internacional pueda mantenerse al día con los tremendos avances tecnológicos que estamos presenciando. Por otro lado, creo que los medios se centran demasiado en los aspectos negativos de estas tecnologías simplemente porque la gente tiene miedo de lo que no entiende, y el miedo vende más anuncios que utopías. La mayoría de los avances tecnológicos, si no todos, son buenos a largo plazo, siempre que podamos garantizar que ningún monopolio pueda preservar o imponer su dominio mediante el uso malicioso de la IA.
Referencias:
- Gudimella, A., Story, R., Shaker, M., Kong, R., Brown, M., Shnayder, V. y Campos, M. (2017). Aprendizaje de refuerzo profundo para la manipulación diestra con redes de conceptos. preimpresión de arXiv arXiv:1709.06977 .
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA