¿Qué es una unidad de procesamiento de tensores?
Con el aprendizaje automático ganando relevancia e importancia todos los días, los microprocesadores convencionales han demostrado ser incapaces de manejarlo de manera efectiva, ya sea entrenamiento o procesamiento de redes neuronales. Las GPU, con su arquitectura altamente paralela diseñada para un procesamiento gráfico rápido, demostraron ser mucho más útiles que las CPU para este propósito, pero faltaban un poco. Por lo tanto, para combatir esta situación, Google desarrolló un circuito integrado acelerador de IA que sería utilizado por su marco TensorFlow AI. Este dispositivo ha sido denominado TPU (Unidad de procesamiento de tensores). El chip ha sido diseñado para Tensorflow Framework .
¿Qué es TensorFlow Framework?
TensorFlow es una biblioteca de código abierto desarrollada por Google para su uso interno. Su uso principal es en aprendizaje automático y programación de flujo de datos. Los cálculos de TensorFlow se expresan como gráficos de flujo de datos con estado. El nombre TensorFlow se deriva de las operaciones que dichas redes neuronales realizan en arrays de datos multidimensionales. Estas arrays se denominan «tensores». TensorFlow está disponible para distribuciones de Linux, Windows y MacOS.
Arquitectura TPU
El siguiente diagrama explica la arquitectura física de las unidades en una TPU:
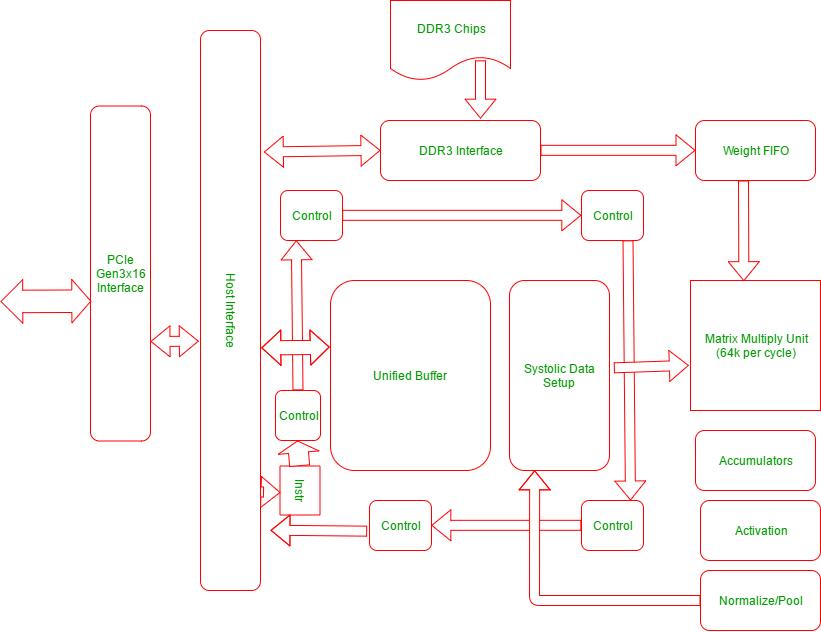
La TPU incluye los siguientes recursos computacionales:
- Unidad multiplicadora de array (MXU) : 65, 536 unidades de multiplicación y suma de 8 bits para operaciones de array.
- Búfer unificado (UB) : 24 MB de SRAM que funcionan como registros
- Unidad de Activación (AU): Funciones de activación cableadas.
Hay 5 conjuntos principales de instrucciones de alto nivel diseñados para controlar cómo funcionan los recursos anteriores. Son los siguientes:
| Instrucción de TPU | Función |
|---|---|
| Read_Host_Memory | Leer datos de la memoria |
| Leer_pesos | Leer pesos de la memoria |
| ArrayMultiplicar/Convolucionar | Multiplicar o convolucionar con los datos y pesos, acumular los resultados |
| Activar | Aplicar funciones de activación |
| Write_Host_Memory | Escribir resultado en la memoria |
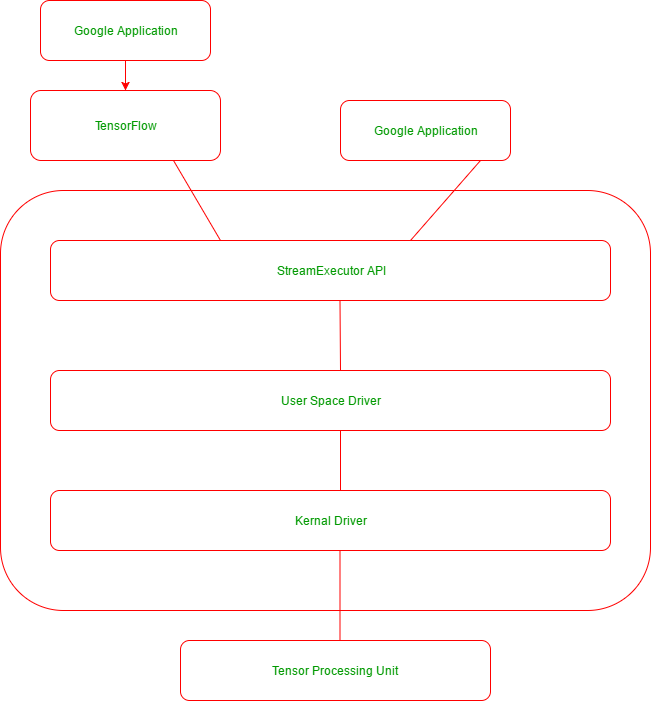
El siguiente es el diagrama de la pila de aplicaciones que mantienen las aplicaciones de Google que usan TensorFlow y TPU:
Ventajas de TPU
Las siguientes son algunas ventajas notables de las TPU:
- Acelera el rendimiento del cálculo de álgebra lineal, que se usa mucho en aplicaciones de aprendizaje automático.
- Minimiza el tiempo de precisión cuando entrena modelos de redes neuronales grandes y complejos.
- Los modelos que antes tardaban semanas en entrenarse en otras plataformas de hardware pueden converger en horas en las TPU.
Cuándo usar una TPU
Los siguientes son los casos en los que las TPU se adaptan mejor al aprendizaje automático:
- Modelos dominados por cálculos matriciales.
- Modelos sin operaciones personalizadas de TensorFlow dentro del ciclo de entrenamiento principal.
- Modelos que entrenan durante semanas o meses
- Modelos más grandes y muy grandes con tamaños de lote efectivos muy grandes.
Referencias:
https://cloud.google.com/blog/big-data/2017/05/an-in-depth-look-at-googles-first-tensor-processing-unit-tpu
https://cloud.google .com/tpu/docs/tpus