TF-IDF son las siglas de Term Frequency Inverse Document Frequency of records. Se puede definir como el cálculo de cuán relevante es una palabra en una serie o corpus para un texto. El significado aumenta proporcionalmente al número de veces que aparece una palabra en el texto, pero se compensa con la frecuencia de palabras en el corpus (conjunto de datos).
- En el documento d, la frecuencia representa el número de instancias de una palabra dada t. Por lo tanto, podemos ver que cobra mayor relevancia cuando aparece una palabra en el texto, que es racional. Dado que el orden de los términos no es significativo, podemos usar un vector para describir el texto en la bolsa de modelos de términos. Para cada término específico del documento, hay una entrada cuyo valor es la frecuencia del término.
tf(t,d) = count of t in d / number of words in d
- Esto prueba el significado del texto, que es muy similar a TF, en toda la colección de corpus. La única diferencia es que en el documento d, TF es el contador de frecuencia para un término t, mientras que df es el número de ocurrencias en el conjunto de documentos N del término t. En otras palabras, el número de artículos en los que está presente la palabra es DF.
df(t) = occurrence of t in documents
- Principalmente, prueba qué tan relevante es la palabra. El objetivo clave de la búsqueda es localizar los registros apropiados que se ajusten a la demanda. Dado que tf considera todos los términos igualmente significativos, no solo es posible utilizar las frecuencias de los términos para medir el peso del término en el artículo. Primero, encuentre la frecuencia de documentos de un término t contando el número de documentos que contienen el término:
df(t) = N(t) where df(t) = Document frequency of a term t N(t) = Number of documents containing the term t
La frecuencia de los términos es el número de instancias de un término en un solo documento; aunque la frecuencia del documento es el número de documentos separados en los que aparece el término, depende de todo el corpus. Ahora veamos la definición de la frecuencia del papel inverso. El IDF de la palabra es el número de documentos del corpus separados por la frecuencia del texto.
idf(t) = N/ df(t) = N/N(t)
Se supone que la palabra más común se considera menos significativa, pero el elemento (los enteros más definidos) parece demasiado duro. Luego tomamos el logaritmo (con base 2) de la frecuencia inversa del papel. Entonces el si del término t se convierte en:
idf(t) = log(N/ df(t))
- Tf-idf es una de las mejores métricas para determinar qué tan significativo es un término para un texto en una serie o un corpus. tf-idf es un sistema de ponderación que asigna un peso a cada palabra de un documento en función de su frecuencia de término (tf) y la frecuencia recíproca del documento (tf) (idf). Las palabras con puntuaciones más altas de peso se consideran más significativas.
Por lo general, el peso tf-idf consta de dos términos:
tf-idf(t, d) = tf(t, d) * idf(t)
En python, los valores tf-idf se pueden calcular utilizando el método TfidfVectorizer() en el módulo sklearn .
Sintaxis:
sklearn.feature_extraction.text.TfidfVectorizer (entrada)
Parámetros:
- entrada : se refiere al documento de parámetros pasado, puede ser un nombre de archivo, archivo o contenido en sí mismo.
Atributos:
- vocabulario _ : Devuelve un diccionario de términos como claves y valores como índices de características.
- idf_ : Devuelve el vector de frecuencia de documento inverso del documento pasado como parámetro.
Devoluciones:
- fit_transform(): Devuelve una array de términos junto con valores tf-idf.
- get_feature_names(): Devuelve una lista
Enfoque paso a paso:
- Importar módulos.
Python3
# import required module from sklearn.feature_extraction.text import TfidfVectorizer
- Recopile strings de documentos y cree un corpus que tenga una colección de strings de los documentos d0, d1 y d2 .
Python3
# assign documents d0 = 'Geeks for geeks' d1 = 'Geeks' d2 = 'r2j' # merge documents into a single corpus string = [d0, d1, d2]
- Obtenga valores tf-idf del método fit_transform() .
Python3
# create object tfidf = TfidfVectorizer() # get tf-df values result = tfidf.fit_transform(string)
- Muestra los valores idf de las palabras presentes en el corpus.
Python3
# get idf values
print('\nidf values:')
for ele1, ele2 in zip(tfidf.get_feature_names(), tfidf.idf_):
print(ele1, ':', ele2)
Producción:
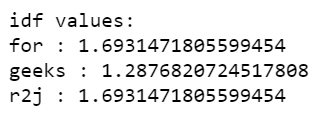
- Muestra los valores tf-idf junto con la indexación.
Python3
# get indexing
print('\nWord indexes:')
print(tfidf.vocabulary_)
# display tf-idf values
print('\ntf-idf value:')
print(result)
# in matrix form
print('\ntf-idf values in matrix form:')
print(result.toarray())
Producción:

La variable de resultado consta de palabras únicas, así como los valores tf-if. Se puede elaborar utilizando la siguiente imagen:
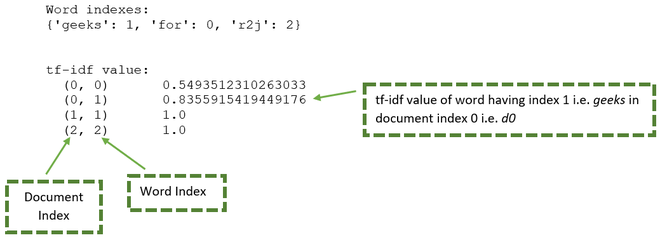
A partir de la imagen de arriba se puede generar la siguiente tabla:
| Documento | Palabra | Índice de documentos | Índice de palabras | valor tf-idf |
|---|---|---|---|---|
| d0 | por | 0 | 0 | |
| d0 | frikis | 0 | 1 | |
| d1 | frikis | 1 | 1 | 1.000 |
| d2 | r2j | 2 | 2 | 1.000 |
A continuación se muestran algunos ejemplos que muestran cómo calcular los valores tf-idf de las palabras de un corpus:
Ejemplo 1: A continuación se muestra el programa completo basado en el enfoque anterior:
Python3
# import required module
from sklearn.feature_extraction.text import TfidfVectorizer
# assign documents
d0 = 'Geeks for geeks'
d1 = 'Geeks'
d2 = 'r2j'
# merge documents into a single corpus
string = [d0, d1, d2]
# create object
tfidf = TfidfVectorizer()
# get tf-df values
result = tfidf.fit_transform(string)
# get idf values
print('\nidf values:')
for ele1, ele2 in zip(tfidf.get_feature_names(), tfidf.idf_):
print(ele1, ':', ele2)
# get indexing
print('\nWord indexes:')
print(tfidf.vocabulary_)
# display tf-idf values
print('\ntf-idf value:')
print(result)
# in matrix form
print('\ntf-idf values in matrix form:')
print(result.toarray())
Producción:

Ejemplo 2: aquí, los valores tf-idf se calculan a partir de un corpus que tiene valores únicos.
Python3
# import required module
from sklearn.feature_extraction.text import TfidfVectorizer
# assign documents
d0 = 'geek1'
d1 = 'geek2'
d2 = 'geek3'
d3 = 'geek4'
# merge documents into a single corpus
string = [d0, d1, d2, d3]
# create object
tfidf = TfidfVectorizer()
# get tf-df values
result = tfidf.fit_transform(string)
# get indexing
print('\nWord indexes:')
print(tfidf.vocabulary_)
# display tf-idf values
print('\ntf-idf values:')
print(result)
Producción:

Ejemplo 3: En este programa, los valores tf-idf se calculan a partir de un corpus que tiene documentos similares.
Python3
# import required module
from sklearn.feature_extraction.text import TfidfVectorizer
# assign documents
d0 = 'Geeks for geeks!'
d1 = 'Geeks for geeks!'
# merge documents into a single corpus
string = [d0, d1]
# create object
tfidf = TfidfVectorizer()
# get tf-df values
result = tfidf.fit_transform(string)
# get indexing
print('\nWord indexes:')
print(tfidf.vocabulary_)
# display tf-idf values
print('\ntf-idf values:')
print(result)
Producción:
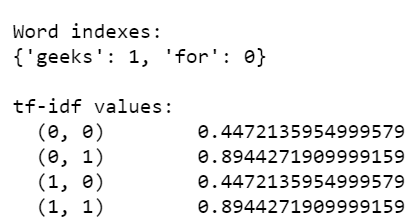
Ejemplo 4: a continuación se muestra el programa en el que intentamos calcular el valor tf-idf de una sola palabra geeks que se repite varias veces en varios documentos.
Python3
# import required module
from sklearn.feature_extraction.text import TfidfVectorizer
# assign corpus
string = ['Geeks geeks']*5
# create object
tfidf = TfidfVectorizer()
# get tf-df values
result = tfidf.fit_transform(string)
# get indexing
print('\nWord indexes:')
print(tfidf.vocabulary_)
# display tf-idf values
print('\ntf-idf values:')
print(result)
Producción:

Publicación traducida automáticamente
Artículo escrito por riturajsaha y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA