Punto de alto apalancamiento: un punto de datos se considera un punto de alto apalancamiento si tiene un valor de entrada de predictor extremo. Un valor de entrada extremo simplemente significa un valor extremadamente bajo o extremadamente alto en comparación con otros puntos de datos en todo el conjunto de datos. La razón por la que es un concepto tan importante en el aprendizaje automático es porque puede influir en gran medida en el ajuste de su modelo en un dato en particular.
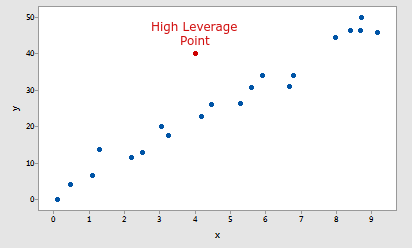
Ejemplo de un punto de alto apalancamiento
En este tutorial vamos a utilizar turicreate para entender el concepto de un alto punto de apalancamiento, así que asegúrese de tener turicreate instalado en su sistema para poder seguir el tutorial. Para más información sobre Turicreate puedes consultar este bonito artículo sobre Turicreate .
Así que entendamos este concepto paso a paso.
Paso 1: Comenzaremos importando todas las bibliotecas requeridas que necesitaremos en este tutorial.
- Turicreate para ajustar nuestro modelo de regresión.
- Matplotlib para visualizar datos.
- random para generar números aleatorios.
Python3
import turicreate import matplotlib.pyplot as plt import random
Paso 2: A continuación, generaremos algunos datos para que se ajusten a nuestro modelo y los visualizaremos usando matplotlib.
Python3
#Creating data point for this tutorial
X = [random.randrange(1, 150) for i in range(200)]
Y = [random.randrange(200, 3000) for i in range(200)]
#Creating a separate point to demonstrate high leverage points
X.append(400)
Y.append(1000)
#Creating a SArray and SFRame
Xs = turicreate.SArray(X)
Ys = turicreate.SArray(Y)
data_points = turicreate.SFrame({"X" : Xs, "Y" : Ys})
#Plotting the Data
plt.scatter(Xs, Ys)
plt.xlabel("Input")
plt.ylabel("Output")
plt.show()
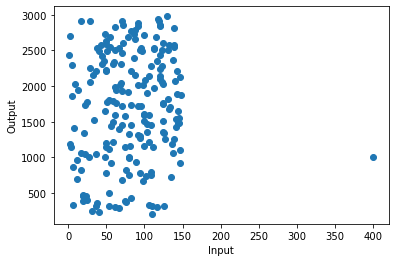
Producción
Como puede ver en la imagen, hay un punto en la coordenada (400,1000) que está muy lejos en el eje x en comparación con otros datos. Ese punto se llama punto de alto apalancamiento.
Paso 3: Ahora, ajustaremos un modelo de regresión a nuestros datos.
Python3
#Fitting a linear Regression model with the given data
model = turicreate.linear_regression.create(data_points,
target = "Y",
features = ["X"])
#Plotting the fitted model
plt.scatter(data_points["X"], data_points["Y"])
plt.xlabel("Input : X")
plt.ylabel("Output : Y")
plt.plot(data_points["X"], model.predict(data_points))
plt.show()
Producción
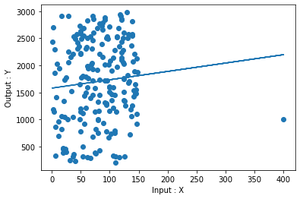
trama del ajuste
Paso 4: Ahora vuelva a ajustar el modelo de regresión, pero esta vez eliminaremos el punto de datos de alto apalancamiento .
Python3
#Training the regression model with the data that do not
#contain high leverage point
model_nohlp = turicreate.linear_regression.create(
data_points_with_no_high_leverage_points, target = "Y", features = ["X"])
#Plotting the fitted model having no high leverage point
plt.scatter(data_points_with_no_high_leverage_points["X"],
data_points_with_no_high_leverage_points["Y"])
plt.xlabel("Input : X")
plt.ylabel("Output : Y")
plt.plot(data_points_with_no_high_leverage_points["X"],
model_nohlp.predict(data_points_with_no_high_leverage_points))
plt.show()
Producción
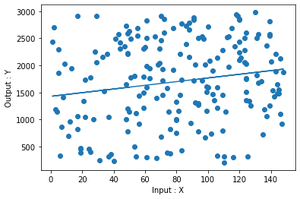
trama del ajuste
Paso 5: a partir de ahora no puede determinar la diferencia real entre los dos modelos. Entonces, visualicemos estos dos ajustes en la misma imagen para comprender mejor la diferencia.
Python3
#Plotting both the fitted model in order to compare the results better
plt.scatter(data_points["X"], data_points["Y"], label = "Data Points")
plt.xlabel("Input : X")
plt.ylabel("Output : Y")
plt.plot(data_points["X"], model.predict(data_points),
label = "Model with High leverage Point")
plt.plot(data_points_with_no_high_leverage_points["X"],
model_nohlp.predict(data_points_with_no_high_leverage_points),
label = "Model with no High Leverage point")
plt.legend()
plt.show()
Python3
#Plotting both the fitted model in order to compare the results better
plt.scatter(data_points["X"], data_points["Y"], label = "Data Points")
plt.xlabel("Input : X")
plt.ylabel("Output : Y")
plt.plot(data_points["X"], model.predict(data_points),
label="Model with High leverage Point")
plt.plot(data_points_with_no_high_leverage_points["X"],
model_nohlp.predict(data_points_with_no_high_leverage_points),
label = "Model with no High Leverage point")
plt.legend()
plt.show()
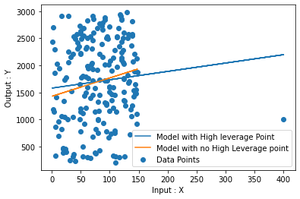
Producción
Como puede ver claramente en la trama, hay una pequeña diferencia entre las dos tramas que surge simplemente al eliminar un solo punto.
Paso 6: ahora calcularemos la diferencia real entre estos dos ajustes. Para ello, calcularemos los coeficientes de regresión de ambos modelos.
Python3
#Comparing the regression coefficients of both the models
print(f"""
Model with High Leverage Point
{model.coefficients}
-----------------------------------------------------------------------
-----------------------------------------------------------------------
Model without High Leverage Point
{model_nohlp.coefficients}
""")
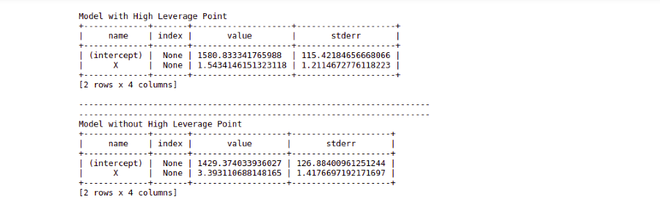
Producción
Como es claramente visible en la imagen que la diferencia entre los coeficientes de los dos modelos no es tan grande, sin embargo, en proyectos del mundo real donde hay datos reales y la cantidad de datos es realmente enorme, puede influir mucho en el ajuste de los modelo pero aún así, un analista necesita averiguar si un punto de datos es realmente de alto apalancamiento o no sin llegar a ninguna conclusión.
En este caso, estamos usando una regresión lineal simple para ajustar nuestros datos, por lo que simplemente podemos visualizar los datos en un gráfico 2D, pero no tenemos ese lujo en el caso de la regresión lineal múltiple. En esa situación, tenemos que confiar en varias medidas para ayudarnos a determinar si un punto de datos es un punto de alto apalancamiento o no.
Publicación traducida automáticamente
Artículo escrito por shawavisek35 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA