El aprendizaje automático es un subconjunto de la inteligencia artificial (IA), que se utiliza para crear sistemas inteligentes que pueden aprender sin ser programados explícitamente. En el aprendizaje automático, creamos algoritmos y modelos que utiliza un sistema inteligente para predecir resultados en función de patrones o tendencias particulares que se observan a partir de los datos proporcionados. El aprendizaje automático sigue un principio único de usar datos y los resultados de los datos para predecir las reglas que se almacenan en un modelo. Luego, este modelo se usa para predecir los resultados de un conjunto diferente de datos. En la programación R, el entorno para el aprendizaje automático se puede configurar fácilmente a través de RStudio .
Configuración de un entorno para el aprendizaje automático con Anaconda
Paso 1: Instale Anaconda ( Linux , Windows ) e inicie el navegador.
Paso 2: Abra Anaconda Navigator y haga clic en el botón Instalar para Rstudio.
Paso 3: después de la instalación, cree un nuevo entorno. Anaconda luego enviará un aviso solicitando ingresar un nombre para el nuevo entorno y el almuerzo del estudio R.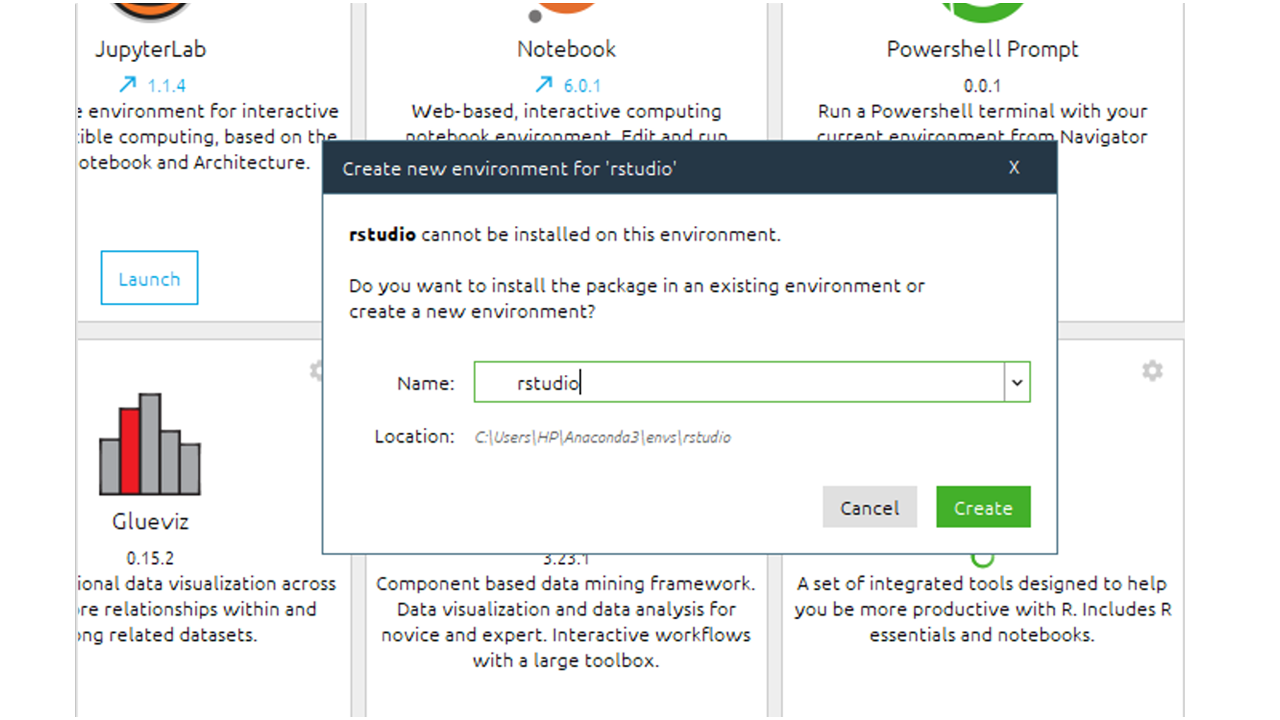
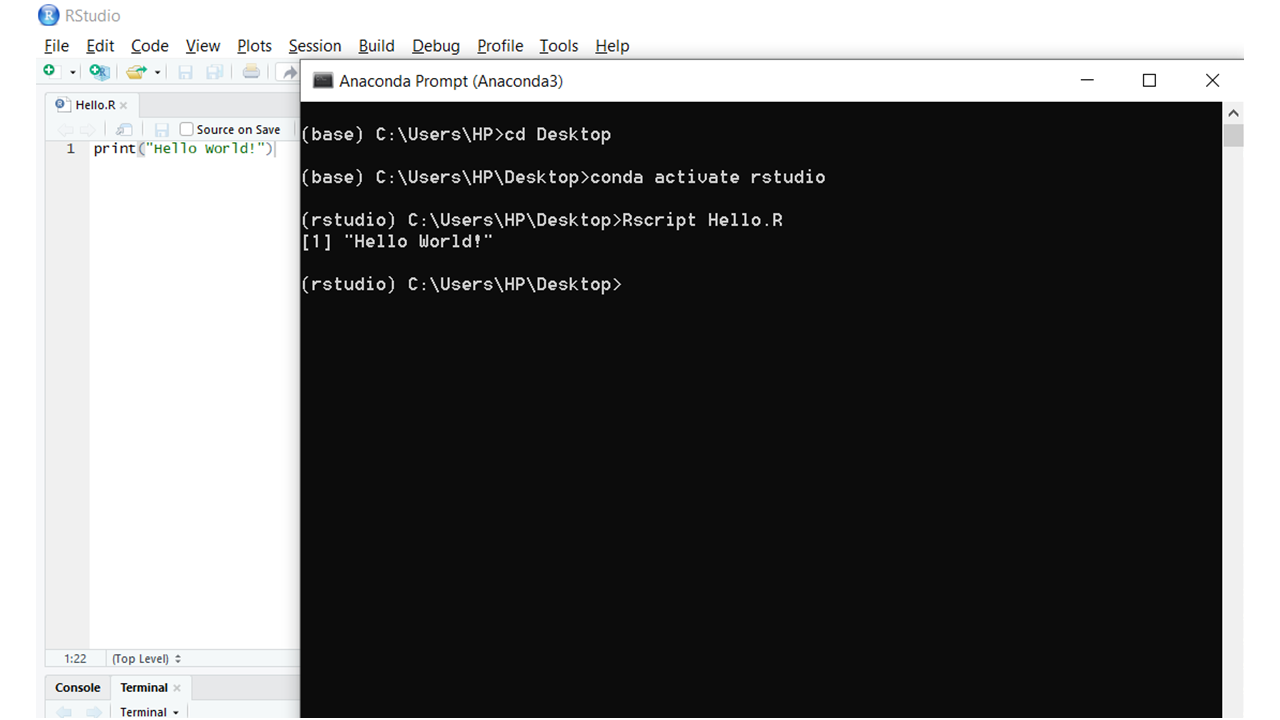
Ejecutar comandos R
Método 1: los comandos de R se pueden ejecutar desde la consola proporcionada en R Studio. Después de abrir Rstudio, simplemente escriba los comandos R en la consola.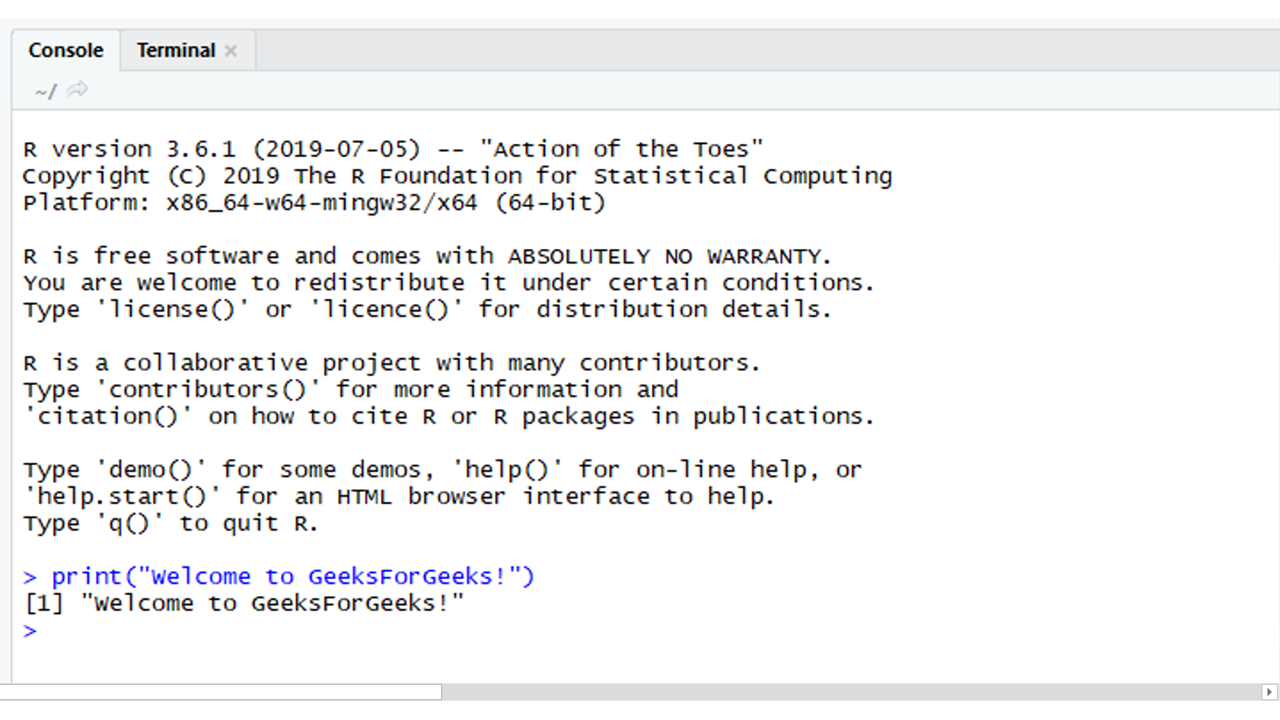
Método 2 : los comandos R se pueden almacenar en un archivo y se pueden ejecutar en un indicador de anaconda. Esto se puede lograr mediante los siguientes pasos.
- Abrir un aviso de anaconda
- Vaya al directorio donde se encuentra el archivo R
- Active el entorno anaconda usando el comando:
conda activate <ENVIRONMENT_NAME>
- Ejecute el archivo usando el comando:
Rscript <FILE_NAME>.R
Instalación de paquetes de aprendizaje automático en R
Los paquetes ayudan a que el código sea más fácil de escribir, ya que contienen un conjunto de funciones predefinidas que realizan diversas tareas. Los paquetes de aprendizaje automático más utilizados son Caret, e1071, net, kernlab y randomforest . Hay dos métodos que se pueden usar para instalar estos paquetes para su programa R.
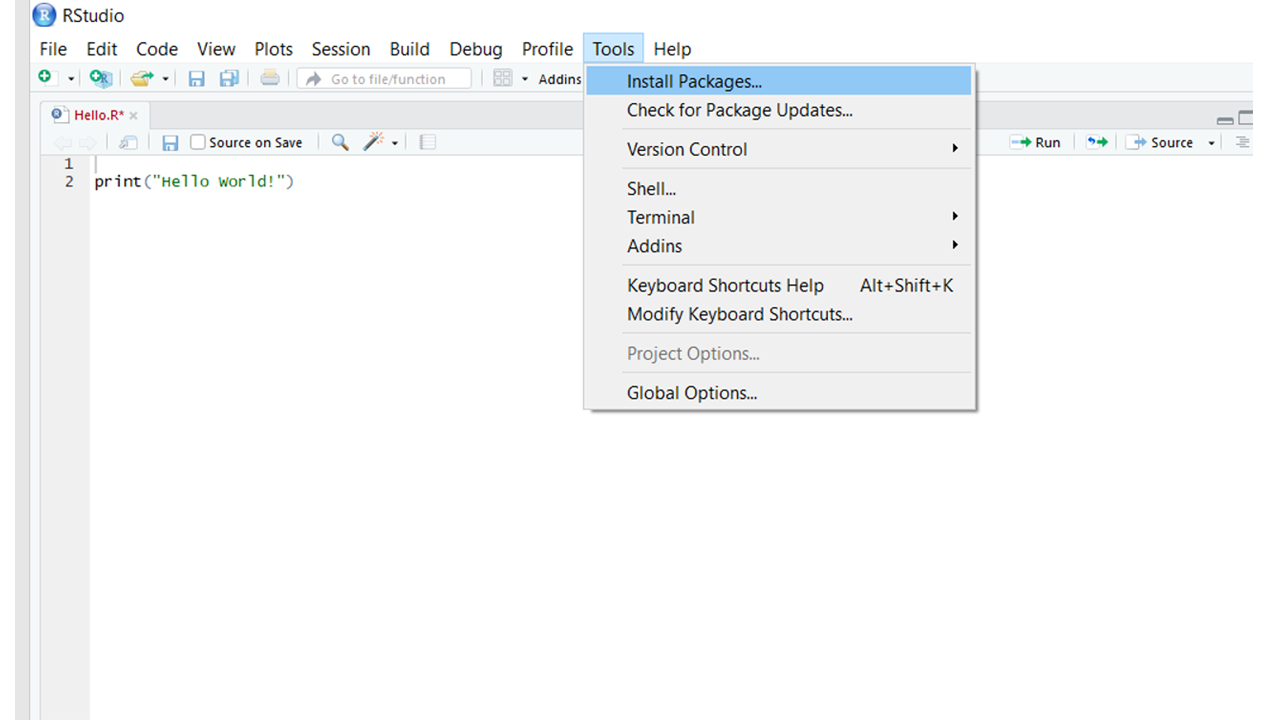
Método 1: Instalación de paquetes a través de Rstudio
- Abra Rstudio y haga clic en la opción Instalar paquetes en Herramientas que se encuentra en la barra de menú.
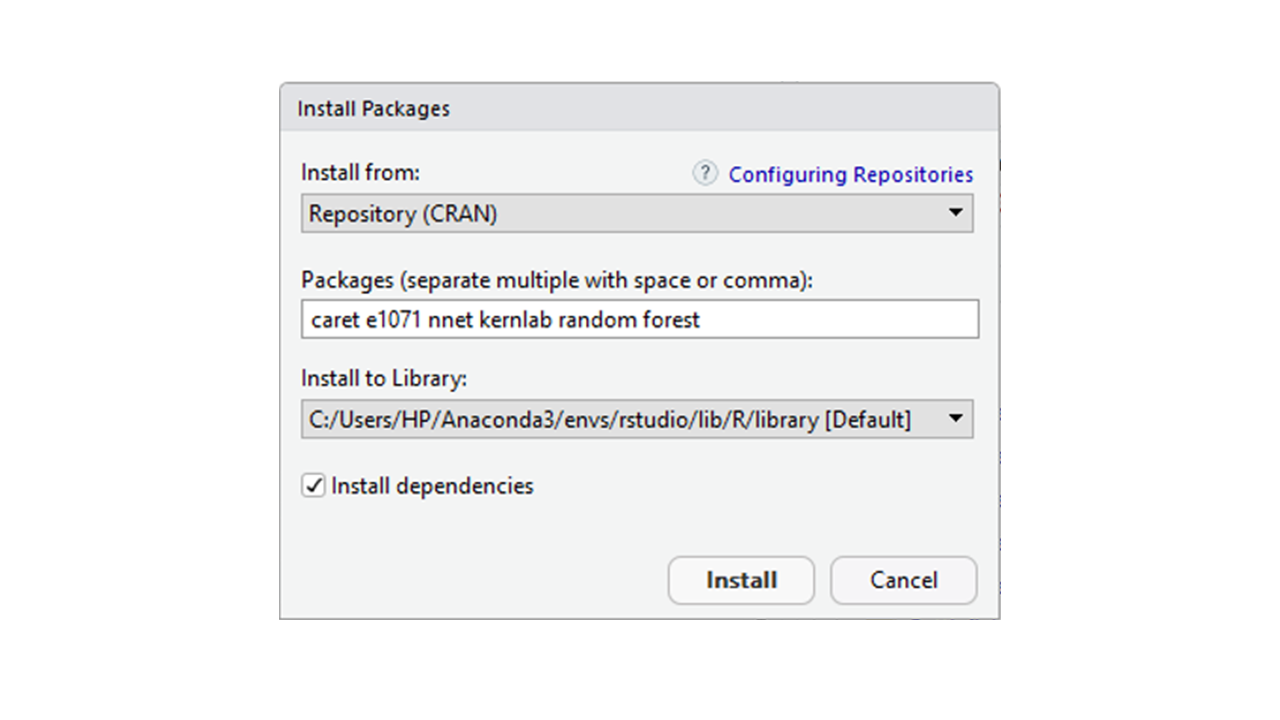
- Ingrese los nombres de todos los paquetes que desea instalar separados por espacios o comas y luego haga clic en instalar.
- Abra un aviso de Anaconda.
- Cambie el entorno al entorno que usó para Rstudio usando el comando:
conda activate <ENVIRONMENT_NAME>
- Ingrese el comando r para abrir la consola R.
- Instale los paquetes requeridos usando el comando:
install.packages(c("<PACKAGE_1>", "<PACKAGE_2>", ..., "<PACKAGE_N>"))
Método 2: Instalación de paquetes a través de la consola de Anaconda/Rstudio
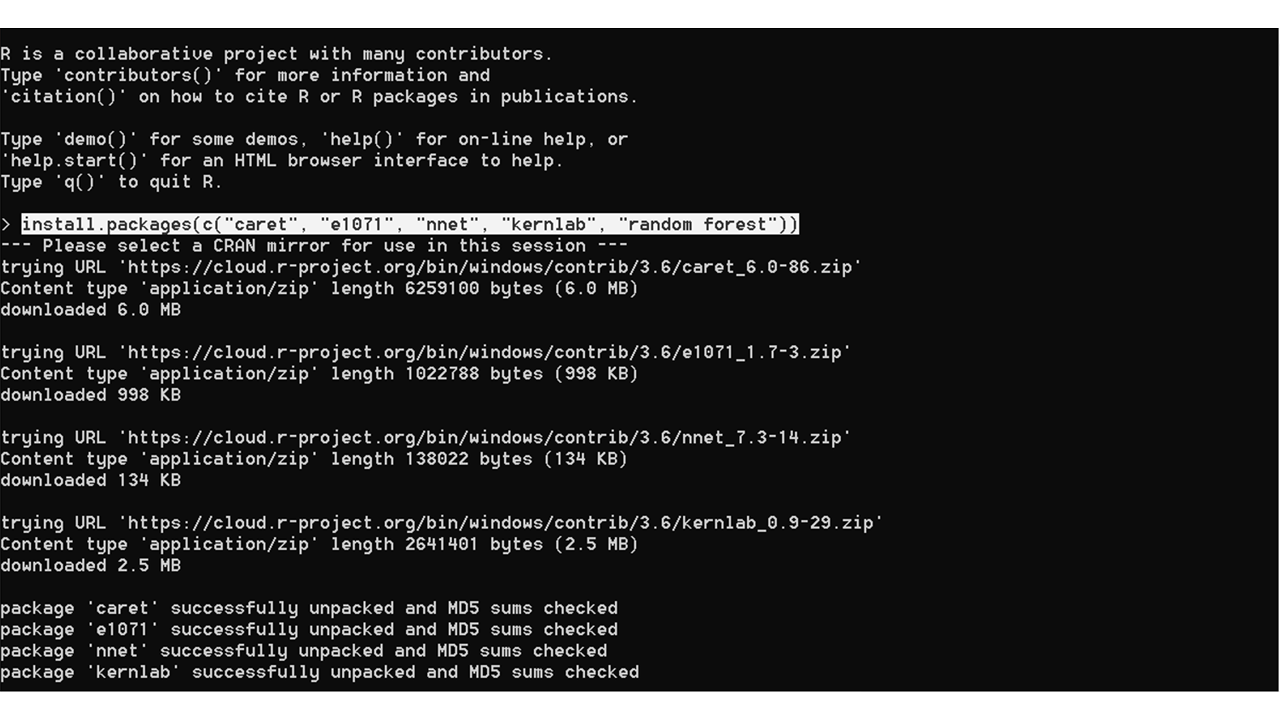
Mientras descarga los paquetes, es posible que se le pida que elija un espejo CRAN . Se recomienda elegir la ubicación más cercana a usted para una descarga más rápida.
Paquetes de aprendizaje automático en R
Hay muchas bibliotecas R que contienen una gran cantidad de funciones, herramientas y métodos para administrar y analizar datos. Cada una de estas bibliotecas tiene un enfoque particular con algunas bibliotecas que administran imágenes y datos textuales, manipulación de datos, visualización de datos, rastreo web, aprendizaje automático, etc. Aquí analicemos algunos de los paquetes importantes de aprendizaje automático demostrando un ejemplo.
Ejemplo:
Preparación del conjunto de datos:
antes de usar estos paquetes, primero importe el conjunto de datos en RStudio, limpie el conjunto de datos y divida los datos en un conjunto de datos de entrenamiento y prueba. Descarga el archivo CSV desde este enlace .
# Import the data setData <- read.csv("GenderClassification.csv", stringsAsFactors = TRUE)# Using set.seed()# Generating random numberset.seed(10) # Cleaning the data setData$Favorite.Color <- as.numeric (Data$Favorite.Color)Data$Favorite.Music.Genre <- as.numeric (Data$Favorite.Music.Genre)Data$Favorite.Beverage <- as.numeric (Data$Favorite.Beverage)Data$Favorite.Soft.Drink <- as.numeric (Data$Favorite.Soft.Drink) # Split into train and test data setTrainingSize <- createDataPartition(Data$Gender, p = 0.8, list = FALSE)TrainingData <- Data[TrainingSize,]TestingData <- Data[-TrainingSize,] |
CARET : Caret significa entrenamiento de clasificación y regresión. El paquete CARET se utiliza para realizar tareas de clasificación y regresión. Consta de muchos otros paquetes integrados.
# Using CARET package # Importing the librarylibrary(caret) # Using the train() available in# Caret packagemodel <- train(Gender ~ ., data = TrainingData, method = "svmPoly", na.action = na.omit, preProcess = c("scale", "center"), trControl = trainControl(method = "none"), tuneGrid = data.frame(degree = 1, scale = 1, C = 1))model.cv <- train(Gender ~ ., data = TrainingData, method = "svmPoly", na.action = na.omit, preProcess = c("scale", "center"), trControl = trainControl(method = "cv", number = 6), tuneGrid = data.frame(degree = 1, scale = 1, C = 1)) # Printing the modelsprint(model)print(model.cv) |
Producción: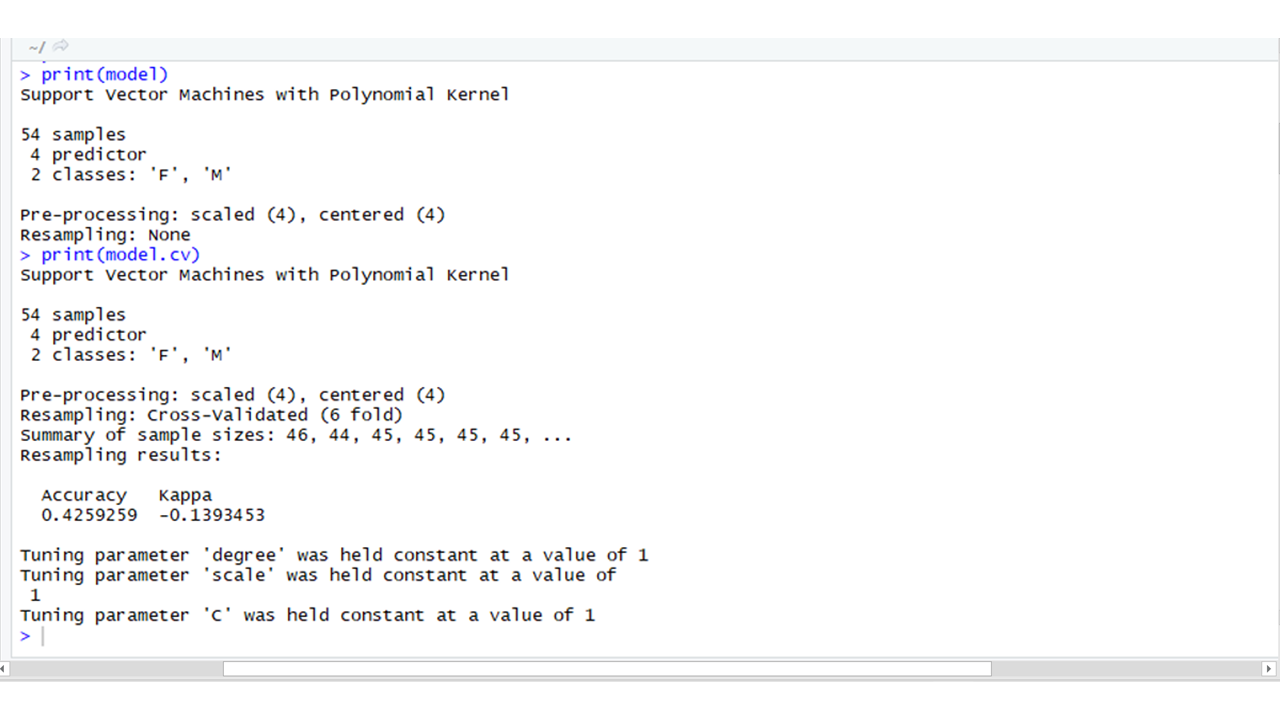
ggplot2 : R es más famoso por su biblioteca de visualización ggplot2. Proporciona un conjunto estético de gráficos que también son interactivos. El paquete ggplot2 se utiliza para crear gráficos y visualizar datos.
# Using ggplot2 # Creating a bar plot from the # Data's Favorite.Color attributeggplot(Data, aes(Favorite.Color)) + geom_bar(fill = "#0073C2FF") |
Producción: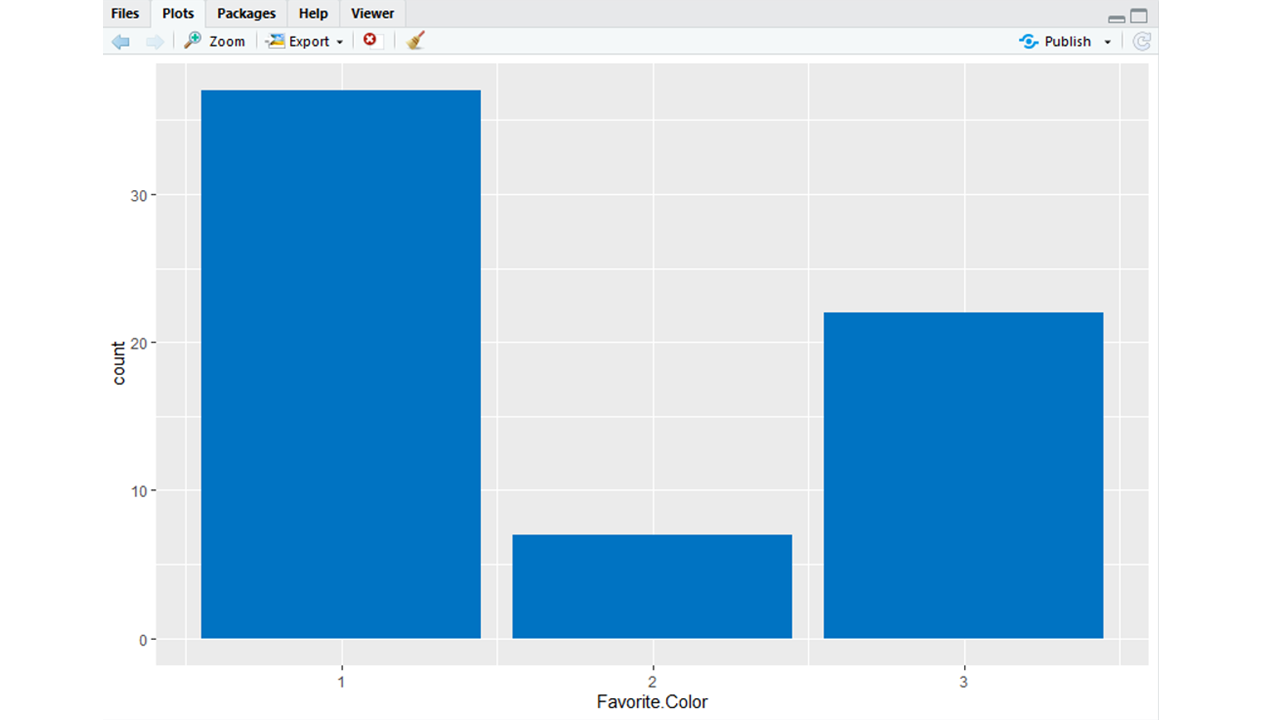
randomForest : El paquete randomForest nos permite usar el algoritmo de bosque aleatorio fácilmente.
# Using randomforset # Importing the randomForest packagelibrary(randomForest) # Using the randomForest function # From the randomForest packagemodel <- randomForest(formula = Gender ~ ., data = Data)print(model) |
Producción: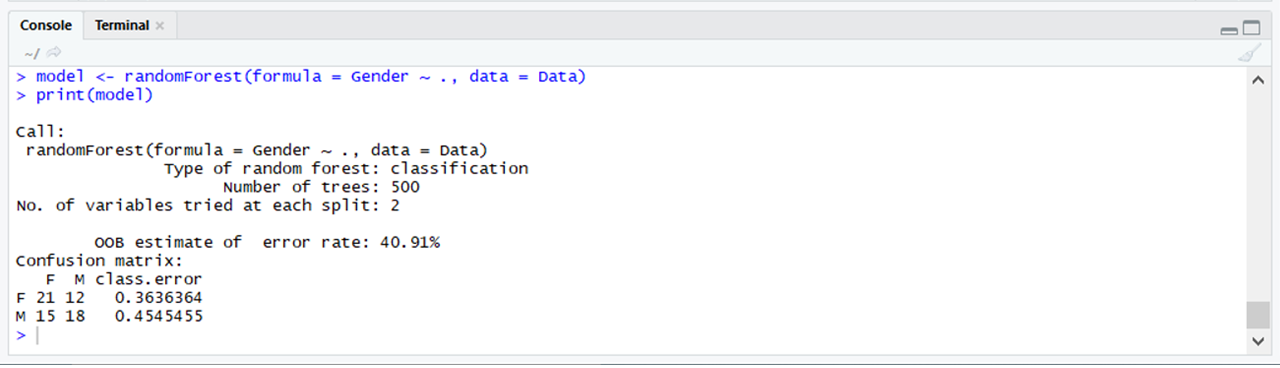
nnet : el paquete nnet utiliza redes neuronales en el aprendizaje profundo para crear capas que ayuden a entrenar y predecir modelos. La pérdida (la diferencia entre el valor real y el valor predicho) disminuye después de cada iteración del entrenamiento.
# Using nnet # Importing the nnet packagelibrary(nnet) # Using the nnet function# In the nnet package model <- nnet(formula = Gender ~ ., data = Data, size = 30)print(model) |
Producción: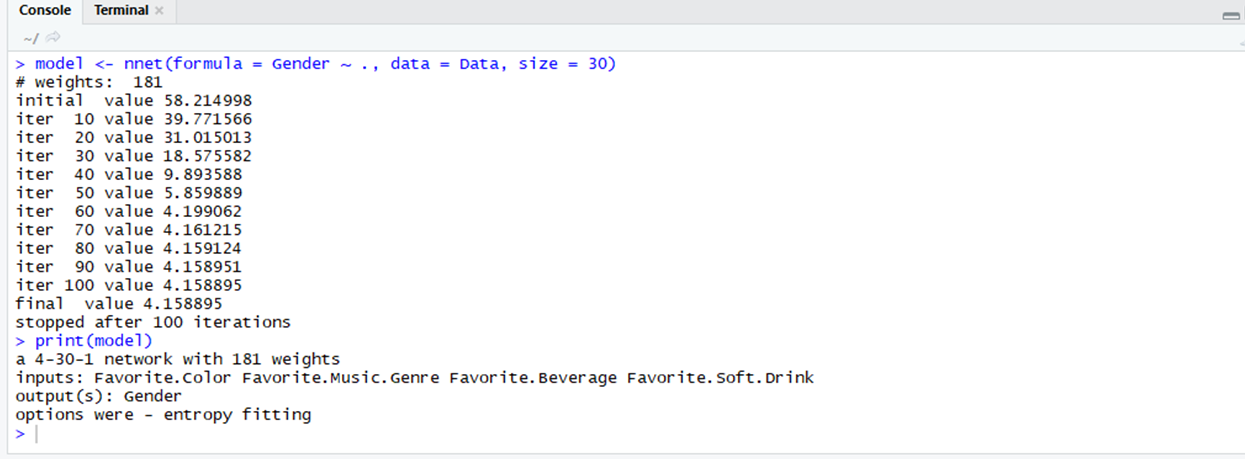
e1071 : el paquete e1071 se utiliza para implementar las máquinas de vectores de soporte, el algoritmo naive bayes y muchos otros algoritmos.
# Using e1071 # Importing the e1071 packagelibrary(e1071) # Using the svm function # In the e1071 packagemodel <- svm(formula = Gender ~ ., data = Data)print(model) |
Producción: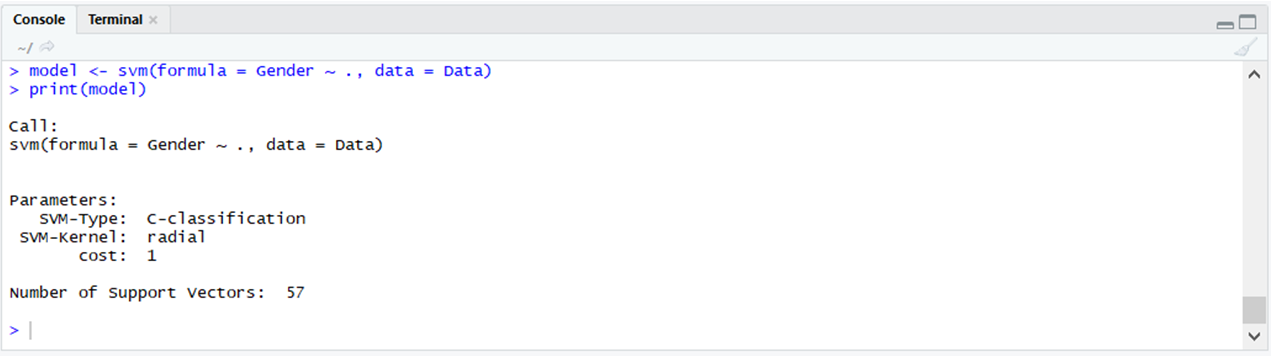
rpart : el paquete rpart se utiliza para particionar datos. Se utiliza para tareas de clasificación y regresión. El modelo resultante tiene la forma de un árbol binario.
# Using rpart # Importing the rpart packagelibrary(rpart) # Using the rpart function# To partition datapartition <- rpart(formula = Gender~., data = Data)plot(partition) |
Producción: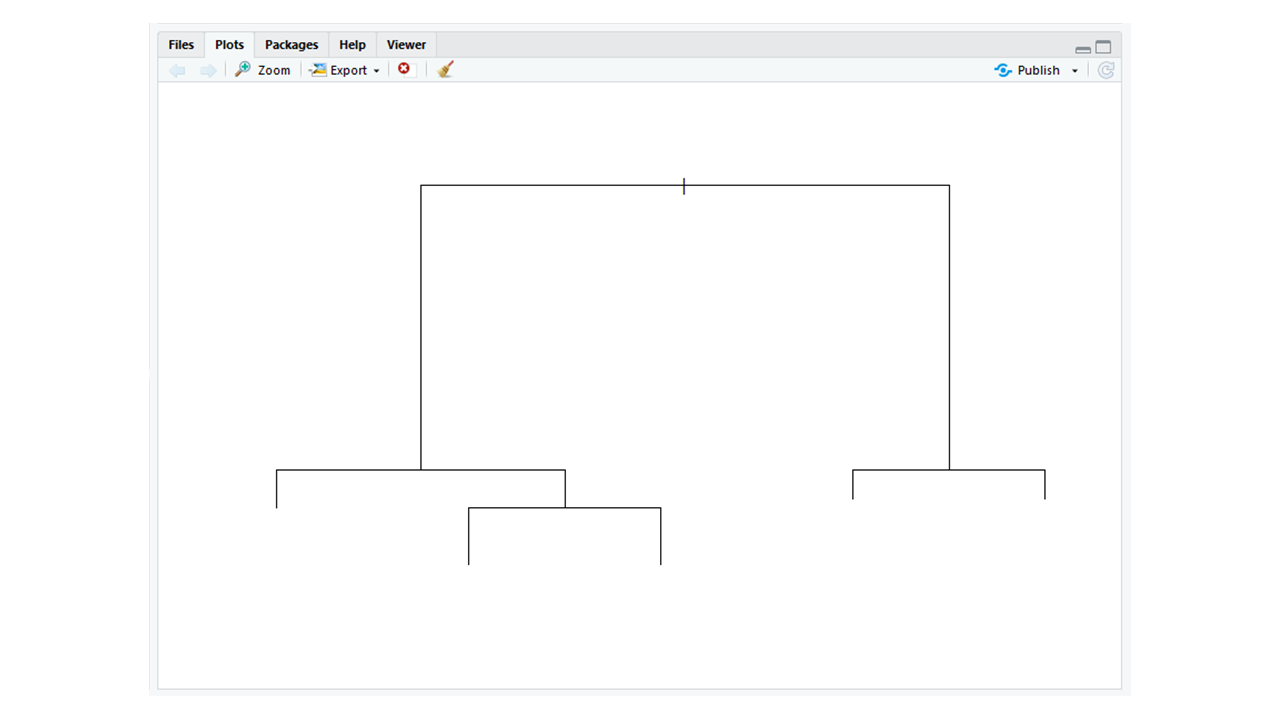
dplyr : Al igual que rpart, el paquete dplyr también es un paquete de manipulación de datos. Ayuda a manipular datos mediante el uso de funciones como filtrar, seleccionar y organizar.
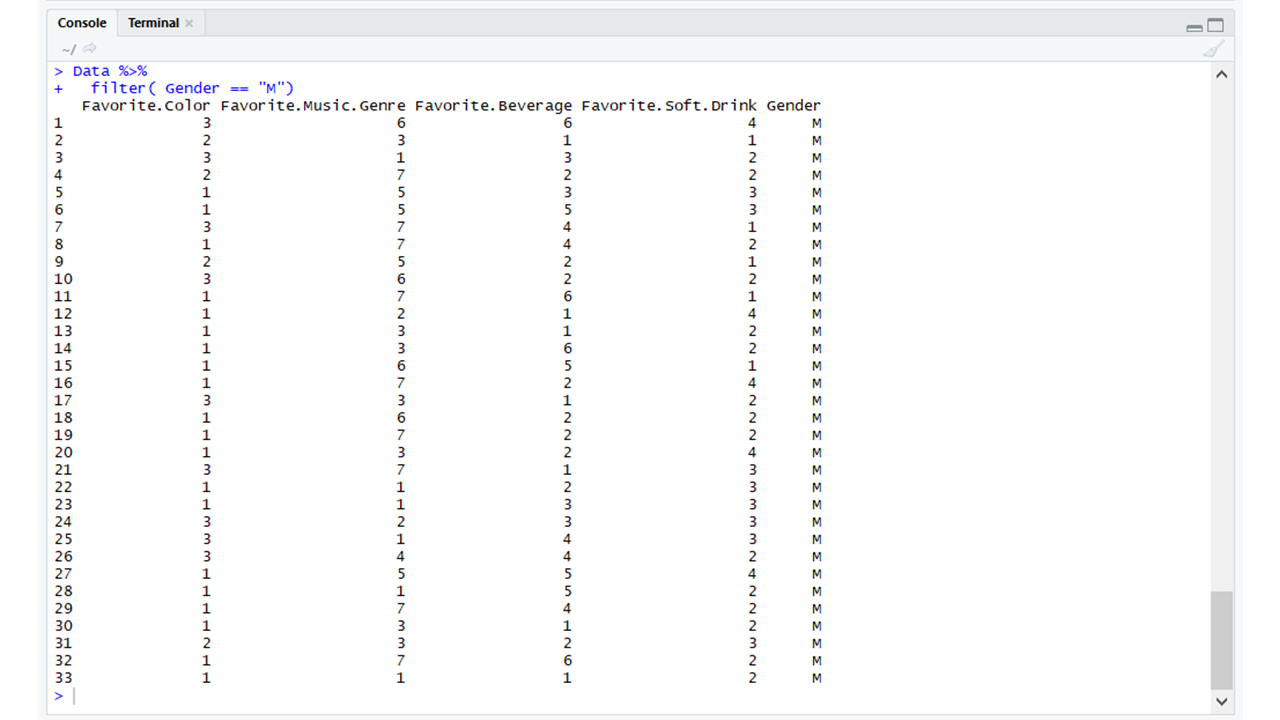
# Using dplyr # Importing the dplyr packagelibrary(dplyr) # Using the filter function# From the dplyr package Data %>% filter(Gender == "M") |
Producción: