Dado un árbol enraizado (suponiendo que la raíz es 1 ) de N Nodes y Q consultas, cada uno de la forma (Val, Node) . Para cada consulta, la tarea es encontrar la cantidad de Nodes con valores más pequeños que Val en el subárbol de Node , incluido él mismo.
Tenga en cuenta que, por definición, los Nodes de este árbol son únicos.
Ejemplos:
Input: N = 7, Q = 3 Val = 4, Node = 4 Val = 7, Node = 6 Val = 5, Node = 1 Given tree:
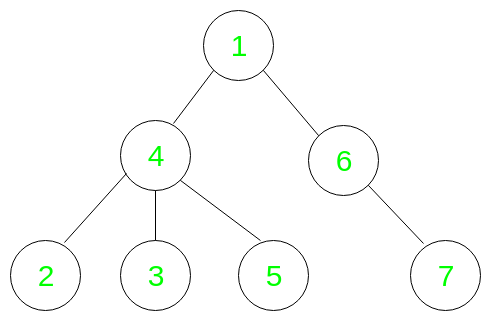
Output: 2 1 4 Explanation: For given queries: Q1 -> Val = 4, Node = 4 The required nodes are 2 and 3 Hence the output is 2 Q2 -> Val = 7, Node = 6 The required node is 6 only Hence the output is 1 Q3 -> Val = 5, Node = 1 The required nodes are 1, 2, 3 and 4 Hence the output is 4
Enfoque ingenuo: un enfoque simple para resolver este problema sería ejecutar DFS desde un Node dado para cada consulta y contar la cantidad de Nodes más pequeños que el valor dado. El padre de un Node determinado debe excluirse del DFS .
Complejidad temporal: O(N*Q) , donde Q es el número de consultas y N es el número de Nodes en el árbol.
Enfoque eficiente: podemos reducir el problema de encontrar el número de elementos en un subárbol a encontrarlos en segmentos contiguos de una array. Para generar tal representación ejecutamos un DFSdesde el Node raíz y empujar el Node a una array cuando ingresamos por primera vez y cuando salimos por última vez. Esta representación de un árbol se conoce como Euler Tour of the tree.
Por ejemplo,
El Euler Tour del árbol anterior será:
1 4 2 2 3 3 5 5 4 6 7 7 6 1
Esta representación de árbol tiene la propiedad de que el subárbol de cada Node X está contenido dentro de la primera y última aparición de X en el arreglo. Cada Node aparece exactamente dos veces. Entonces, contar el número de Nodes más pequeños que Val entre la primera y la última ocurrencia de Node nos dará el doble de la respuesta de esa consulta.
Con esta representación, las consultas se pueden procesar sin conexión en O(log(N)) por consulta mediante un árbol indexado binario .
Preprocesamiento:
- Almacenamos el índice de la primera y última aparición de cada Node en el Tour en dos arrays, inicio y final . Deje que start[X] y end[X] representen estos índices para el Node X. Esto se puede hacer en O (N)
- En Euler Tour, almacenamos la posición del elemento junto con el Node como un par (indexInTree, indexInTour) y luego ordenamos de acuerdo con indexInTree . Deje que esta array sea ordenadaTour
- De manera similar, mantenemos una array de Consultas de la forma (Val, Node) y ordenamos según Val . Deje que esta array se ordeneConsulta
- Inicialice un árbol indexado binario de tamaño 2N con todas las entradas como 0. Deje que esto sea un bit
- Luego proceda de la siguiente manera. Mantenga un puntero en sortedTour y sortedQuery
- Para cada consulta en sortedQuery desde el principio, seleccione los Nodes de sortedTour que tengan indexInTree <Val , e incremente su indexInTour en bits . Entonces la respuesta de esa consulta sería la mitad de la suma desde el inicio [Node] hasta el final [Node]
- Para la siguiente consulta en sortedQuery , seleccionamos cualquier Node previamente no seleccionado de sortedTour que tenga indexInTree < Val , e incrementamos su indexInTour en bits y respondemos la consulta como se hizo antes.
- Repitiendo este proceso para cada consulta podemos responderlas en O(Qlog(N)).
A continuación se muestra la implementación en C++ del enfoque anterior:
CPP
// C++ program Queries to find the Number of
// Nodes having Smaller Values from a Given
// Value in the Subtree of a Node
#include <bits/stdc++.h>
using namespace std;
// Takes a tree and generates a Euler tour for that
// tree in 'tour' parameter This is a modified form
// of DFS in which we push the node while entering for
// the first time and when exiting from it
void eulerTour(vector<vector<int> >& tree,
vector<int>& vst,
int root,
vector<int>& tour)
{
// Push node in tour while entering
tour.push_back(root);
// DFS
vst[root] = 1;
for (auto& x : tree[root]) {
if (!vst[x]) {
eulerTour(tree, vst, x, tour);
}
}
// Push node in tour while exiting
tour.push_back(root);
}
// Creates the start and end array as described in
// pre-processing section. Traverse the tour from
// left to right and update start for 1st occurrence
// and end for 2nd occurrence of each node
void createStartEnd(vector<int>& tour,
vector<int>& start,
vector<int>& end)
{
for (int i = 1; i < tour.size(); ++i) {
if (start[tour[i]] == -1) {
start[tour[i]] = i;
}
else {
end[tour[i]] = i;
}
}
}
// Returns a sorted array of pair containing node and
// tourIndex as described in pre-processing section
vector<pair<int, int> >
createSortedTour(vector<int>& tour)
{
vector<pair<int, int> > arr;
for (int i = 1; i < tour.size(); ++i) {
arr.push_back(make_pair(tour[i], i));
}
sort(arr.begin(), arr.end());
return arr;
}
// Binary Indexed Tree Implementation
// This function will add 1 from the position
void increment(vector<int>& bit, int pos)
{
for (; pos < bit.size(); pos += pos & -pos) {
bit[pos]++;
}
}
// It will give the range sum
int query(vector<int>& bit,
int start,
int end)
{
--start;
int s1 = 0, s2 = 0;
for (; start > 0; start -= start & -start) {
s1 += bit[start];
}
for (; end > 0; end -= end & -end) {
s2 += bit[end];
}
return s2 - s1;
}
// Function to calculate the ans for each query
map<pair<int, int>, int> cal(int N,
int Q,
vector<vector<int>> tree,
vector<pair<int, int>> queries)
{
// Preprocessing
// Creating the vector to store the tours and queries
vector<int> tour, vst(N + 1, 0),
start(N + 1, -1),
end(N + 1, -1),
bit(2 * N + 4, 0);
// For one based indexing in tour.
// Simplifies code for Binary Indexed Tree.
// We will ignore the 1st element in tour
tour.push_back(-1);
// Create Euler Tour
eulerTour(tree, vst, 1, tour);
// Create Start and End Array
createStartEnd(tour, start, end);
// Create sortedTour and sortedQuery
auto sortedTour = createSortedTour(tour);
auto sortedQuery = queries;
sort(sortedQuery.begin(), sortedQuery.end());
// For storing answers to query
map<pair<int, int>, int> queryAns;
// We maintain pointers each for sortedTour and
// sortedQuery.For each element X in sortedTour
// we first process any queries with val smaller
// than X's node and update queryptr to first
// unprocessed query.Then update the position
// of X in BIT.
int tourptr = 0, queryptr = 0;
while (queryptr < sortedQuery.size()) {
// Queries lies in the range then
while (queryptr < sortedQuery.size()
&& sortedQuery[queryptr].first
<= sortedTour[tourptr].first){
auto node = sortedQuery[queryptr].second;
// Making the query on BIT and dividing by 2.
queryAns[sortedQuery[queryptr]]
= query(bit, start[node], end[node]) / 2;
++queryptr;
}
if (tourptr < sortedTour.size()) {
increment(bit, sortedTour[tourptr].second);
++tourptr;
}
}
return queryAns;
}
// Driver Code
int main()
{
int N = 7, Q = 3;
// Tree edges
vector<vector<int> > tree = { {},
{ 4, 6 },
{ 4 },
{ 4 },
{ 1, 2, 3, 5 },
{ 4 },
{ 1, 7 },
{ 6 } };
// Queries vector
vector<pair<int, int> > queries
= { make_pair(4, 1),
make_pair(7, 6),
make_pair(5, 1) };
// Calling the function
map<pair<int, int>, int> queryAns =
cal(N, Q, tree, queries);
// Print answer in order of input.
for (auto& x : queries) {
cout << queryAns[x] << '\n';
}
return 0;
}
3 1 4
Publicación traducida automáticamente
Artículo escrito por ankurdubey521 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA