Todos los modelos estadísticos y de aprendizaje automático se construyen sobre la base de datos. Una entidad agrupada o compuesta que contiene lo relevante para un problema particular se llama conjunto de datos. Estos conjuntos de datos están compuestos por Variables Independientes o las características y las Variables Dependientes o las Etiquetas. Todas estas variables se pueden clasificar en dos tipos de datos: Cuantitativos y Categóricos .
En este artículo, vamos a tratar los diversos métodos para convertir variables categóricas en variables ficticias, que es una parte esencial del preprocesamiento de datos, que en sí mismo es una parte integral del aprendizaje automático o modelo estadístico. Las variables categóricas se pueden subdividir en las siguientes categorías:
- Binario o dicotómico son esencialmente las variables que pueden tener solo dos resultados, como Ganar/Perder, Activar/Desactivar, etc.
- Las variables nominales se utilizan para representar grupos sin una clasificación particular, como colores, marcas, etc.
- Las variables ordinales representan grupos con un orden de clasificación específico, como Ganadores de una carrera, Calificaciones de aplicaciones, por nombrar algunos.
Las variables ficticias actúan como indicadores de la presencia o ausencia de una categoría en una variable categórica. La convención habitual dicta que 0 representa ausencia mientras que 1 representa presencia. La conversión de variables categóricas en variables ficticias conduce a la formación de la array binaria bidimensional donde cada columna representa una categoría particular. El siguiente ejemplo aclarará aún más el proceso de conversión.
Conjunto de datos que contiene variable categórica:
| PANORAMA | LA TEMPERATURA | HUMEDAD | VENTOSO |
|---|---|---|---|
| Lluvioso | Caliente | Alto | No |
| Lluvioso | Caliente | Alto | Sí |
| Nublado | Caliente | Alto | No |
| Soleado | Templado | Alto | No |
| Soleado | Enfriar | Normal | No |
Conjunto de datos que contiene una variable ficticia:
| LLUVIOSO | NUBLADO | SOLEADO | CALIENTE | TEMPLADO | FRÍO | ALTO | NORMAL | SÍ | NO |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
| 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 |
| 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
| 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 |
Explicación:
El conjunto de datos anterior comprende cuatro columnas categóricas: PERSPECTIVA, TEMPERATURA, HUMEDAD, VIENTO.
Consideremos la columna VENTOSA que se compone de dos categorías: SÍ y NO. Entonces, en el conjunto de datos que contiene las variables ficticias, la columna WINDY se reemplaza por dos columnas, cada una de las cuales representa las categorías: SÍ y NO. Ahora comparando las filas de las columnas SÍ y NO con VENTOSA, marcamos 0 para SÍ donde está ausente y 1 donde está presente. Lo mismo se hace para la columna NO. Esta metodología se adopta para todas las columnas categóricas. Lo importante a tener en cuenta es que cada columna categórica se reemplaza por la cantidad de categorías únicas que tiene en el conjunto de datos que contiene variables ficticias.
Vamos a explorar tres enfoques para convertir variables categóricas en variables ficticias en este artículo.
Estos enfoques son los siguientes:
- Uso de LabelBinarizer de sklearn
- Usando BinaryEncoder de category_encoders
- Usando la función get_dummies() de la biblioteca pandas
Creando el conjunto de datos:
El primer paso es crear el conjunto de datos. Este conjunto de datos comprende 4 columnas categóricas que se denominan PERSPECTIVA, TEMPERATURA, HUMEDAD, VIENTO. El siguiente es el código para la creación del conjunto de datos. Creamos este conjunto de datos usando pandas.DataFrame() y el diccionario.
Python3
# code to create the dataset
# importing the libraries
import pandas as pd
# creating the dictionary
dictionary = {'OUTLOOK': ['Rainy', 'Rainy',
'Overcast', 'Sunny',
'Sunny', 'Sunny',
'Overcast', 'Rainy',
'Rainy', 'Sunny',
'Rainy', 'Overcast',
'Overcast', 'Sunny'],
'TEMPERATURE': ['Hot', 'Hot', 'Hot',
'Mild', 'Cool',
'Cool', 'Cool',
'Mild', 'Cool',
'Mild', 'Mild',
'Mild', 'Hot', 'Mild'],
'HUMIDITY': ['High', 'High', 'High',
'High', 'Normal', 'Normal',
'Normal', 'High', 'Normal',
'Normal', 'Normal', 'High',
'Normal', 'High'],
'WINDY': ['No', 'Yes', 'No', 'No', 'No',
'Yes', 'Yes', 'No', 'No',
'No', 'Yes', 'Yes', 'No',
'Yes']}
# converting the dictionary to DataFrame
df = pd.DataFrame(dictionary)
display(df)
Producción:
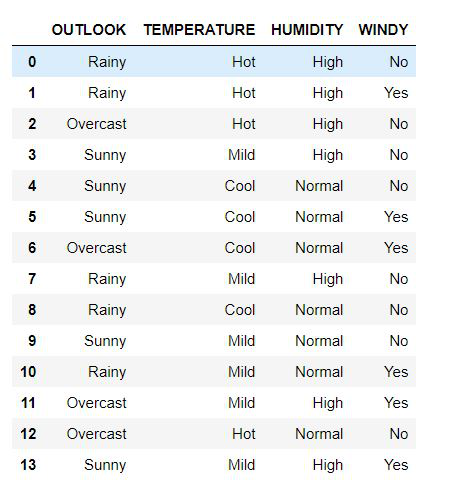
Lo anterior es el conjunto de datos que usaremos para los enfoques futuros.
Enfoque 1:
Con este enfoque, usamos LabelBinarizer de sklearn, que convierte una columna categórica en un marco de datos con variables ficticias a la vez. Este marco de datos se puede agregar al marco de datos principal en el caso de que haya más de una columna categórica.
Python3
# importing the libraries from sklearn.preprocessing import LabelBinarizer # creating a copy of the # original data frame df1 = df.copy() # creating an object # of the LabelBinarizer label_binarizer = LabelBinarizer() # fitting the column # TEMPERATURE to LabelBinarizer label_binarizer_output = label_binarizer.fit_transform( df1['TEMPERATURE']) # creating a data frame from the object result_df = pd.DataFrame(label_binarizer_output, columns = label_binarizer.classes_) display(result_df)
Producción:
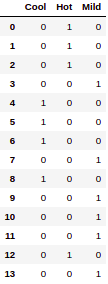
Conversión de la columna TEMPERATURA
De manera similar, también podemos transformar otras columnas categóricas.
Enfoque 2:
Usando BinaryEncoder de la biblioteca category_encoders. Con este enfoque, podemos convertir múltiples columnas categóricas en variables ficticias de una sola vez.
category_encoders: category_encoders es una biblioteca de Python desarrollada bajo la biblioteca scikit-learn-transformers. El objetivo principal de esta biblioteca es convertir variables categóricas en variables numéricas cuantificables. Hay varias ventajas de esta biblioteca, como ser fácilmente compatible con los transformadores sklearn, lo que les permite entrenarse y almacenarse fácilmente en archivos serializables como pickle para su uso posterior. Esta biblioteca también funciona muy bien para trabajar con marcos de datos, lo que es de gran utilidad cuando se trata de modelos estadísticos y de aprendizaje automático. Proporciona una gran variedad de métodos para la conversión de variables categóricas a numéricas, que también se pueden clasificar en supervisadas y no supervisadas.
Para la instalación, ejecute este comando en la terminal:
pip install category_encoders
Para Conda:
conda install -c conda-forge category_encoders
Código:
Python3
# importing the libraries import category_encoders as cat_encoder # creating a copy of the original data frame df2 = df.copy() # creating an object BinaryEncoder # this code calls all columns # we can specify specific columns as well encoder = cat_encoder.BinaryEncoder(cols = df2.columns) # fitting the columns to a data frame df_category_encoder = encoder.fit_transform( df2 ) display(df_category_encoder)
Producción:
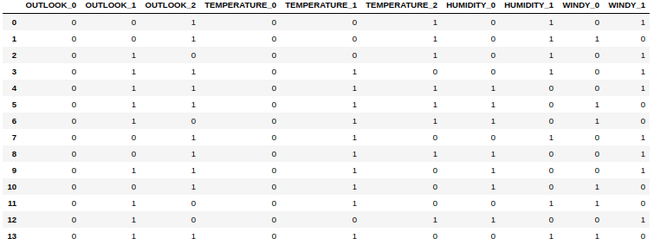
Marco de datos creado a partir de todas las columnas categóricas
Enfoque 3:
Bajo este enfoque, implementamos la forma más sencilla de realizar la conversión de todas las columnas categóricas posibles en un marco de datos a columnas ficticias utilizando el método get_dummies() de la biblioteca pandas.
Podemos especificar las columnas para obtener los ficticios de forma predeterminada, convertirá todas las columnas categóricas posibles en sus columnas ficticias.
Python3
# importing the libraries import pandas as pd # creating a copy of the original data frame df3 = df.copy() # calling the get_dummies method # the first parameter mentions the # the name of the data frame to store the # new data frame in # the second parameter is the list of # columns which if not mentioned # returns the dummies for all # categorical columns df3 = pd.get_dummies(df3, columns = ['WINDY', 'OUTLOOK']) display(df3)
Producción:
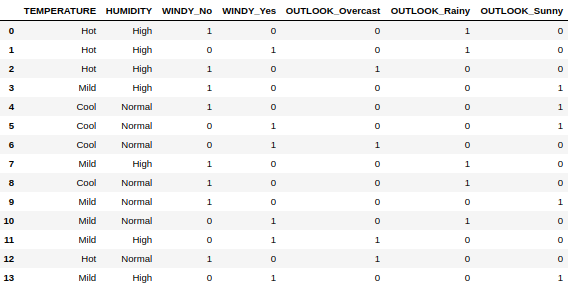
Usando get_dummies() para las columnas WINDY y OUTLOOK
Publicación traducida automáticamente
Artículo escrito por ag01harshit y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA