La detección de emociones es uno de los temas más candentes en la investigación hoy en día. La tecnología de detección de emociones puede facilitar la comunicación entre máquinas y humanos. También ayudará a mejorar el proceso de toma de decisiones. Se han propuesto muchos modelos de aprendizaje automático para reconocer las emociones del texto. Pero, en este artículo, nuestro enfoque está en el modelo LSTM bidireccional. LSTM bidireccionales en resumen BiLSTM es una adición a los LSTM regulares que se utiliza para mejorar el rendimiento del modelo en problemas de clasificación de secuencias. Los BiLSTM usan dos LSTM para entrenar en entrada secuencial. El primer LSTM se usa en la secuencia de entrada tal cual. El segundo LSTM se usa en una representación inversa de la secuencia de entrada. Ayuda a complementar el contexto adicional y hace que nuestro modelo sea rápido.
El conjunto de datos que hemos utilizado es ISEAR (Encuesta internacional sobre antecedentes y reacciones emocionales). Aquí, hay un vistazo del conjunto de datos.

Conjunto de datos ISEAR
El conjunto de datos ISEAR contiene 7652 oraciones. Tiene un total de siete sentimientos que son: Alegría, Miedo, Ira, Tristeza, Culpa, Vergüenza y Disgusto.
Vayamos paso a paso para hacer el modelo que predecirá la emoción.
Paso 1: Importación de las bibliotecas requeridas
Python3
# Importing the required libraries
import keras
import numpy as np
from keras.models import Sequential,Model
from keras.layers import Dense,Bidirectional
from nltk.tokenize import word_tokenize,sent_tokenize
from keras.layers import *
from sklearn.model_selection import cross_val_score
import nltk
import pandas as pd
nltk.download('punkt')
Paso 2: El siguiente paso es cargar el conjunto de datos de nuestra máquina y preprocesarlo. En el conjunto de datos, hay algunas filas que contienen -‘Sin respuesta’. Esta frase es completamente inútil para nosotros. Entonces, eliminaremos esas filas.
Leer el conjunto de datos y preprocesarlo
Python3
df=pd.read_csv('isear.csv',header=None)
# The isear.csv contains rows with value 'No response'
# We need to remove such rows
df.drop(df[df[1] == '[ No response.]'].index, inplace = True)
Paso 3: aplique un tokenizador de palabras para convertir cada oración en una lista de palabras. Ejemplo: Si hay una oración- ‘Soy feliz’. Luego, tokenizarlo se convertirá en una lista [‘I’, ‘am’, ‘feliz’].
Palabra tokenizar
Python3
# The feel_arr will store all the sentences # i.e feel_arr is the list of all sentences feel_arr = df[1] # Each sentence in feel_arr is tokenized by the help of work tokenizer. # If I have a sentence - 'I am happy'. # After word tokenizing it will convert into- ['I','am','happy'] feel_arr = [word_tokenize(sent) for sent in feel_arr] print(feel_arr[0])
El resultado del fragmento de código anterior es este:

La salida de la palabra tokenizada
Paso 4: La longitud de cada oración es diferente. Para pasarlo por el modelo, la longitud de cada oración debe ser igual. Al visualizar el conjunto de datos, podemos ver que la longitud de la oración en el conjunto de datos no supera las 100 palabras. Entonces, ahora convertiremos cada oración a 100 palabras. Para ello, tomaremos la ayuda de relleno.
Aplicación de relleno
Python3
# Defined a function padd in which each sentence length is fixed to 100.
# If length is less than 100 , then the word- '<padd>' is append
def padd(arr):
for i in range(100-len(arr)):
arr.append('<pad>')
return arr[:100]
# call the padd function for each sentence in feel_arr
for i in range(len(feel_arr)):
feel_arr[i]=padd(feel_arr[i])
El resultado del fragmento de código anterior es este:

Salida después del relleno
5. Ahora, cada palabra debe integrarse en alguna representación numérica, ya que el modelo solo comprende dígitos numéricos. Entonces, para esto, hemos descargado un vector de guante predefinido de 50 dimensiones de Internet. Este vector se utiliza con el fin de incrustar palabras. Cada palabra se representa en un vector de 50 dimensiones.
El vector guante contiene casi todas las palabras del diccionario de inglés.
Aquí hay una idea del vector del guante.

vector de guante
La primera palabra de cada fila es el carácter que se va a incrustar. Y desde la columna hasta la última columna, está la representación numérica de ese carácter en forma de vector 50d.
Incrustación de palabras con el guante
Python3
# Glove vector contains a 50 dimensional vector corresponding to each word in dictionary.
vocab_f = 'glove.6B.50d.txt'
# embeddings_index is a dictionary which contains the mapping of
# word with its corresponding 50d vector.
embeddings_index = {}
with open(vocab_f, encoding='utf8') as f:
for line in f:
# splitting each line of the glove.6B.50d in a list of items- in which
# the first element is the word to be embedded, and from second
# to the end of line contains the 50d vector.
values = line.rstrip().rsplit(' ')
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
# Now, each word of the dataset should be embedded in 50d vector with
# the help of the dictionary form above.
# Embedding each word of the feel_arr
embedded_feel_arr = []
for each_sentence in feel_arr:
embedded_feel_arr.append([])
for word in each_sentence:
if word.lower() in embeddings_index:
embedded_feel_arr[-1].append(embeddings_index[word.lower()])
else:
# if the word to be embedded is '<padd>' append 0 fifty times
embedded_feel_arr[-1].append([0]*50)
Aquí, en el ejemplo anterior, el diccionario formado, es decir, incrustaciones_índice , contiene la palabra y su correspondiente vector de 50d, para visualizarlo imprimamos las 50 dimensiones de la palabra -‘feliz’.

Paso 6: Ahora, hemos terminado con toda la parte de preprocesamiento, y ahora debemos realizar las siguientes cosas:
- Haz una codificación one-hot de cada emoción.
- Divida el conjunto de datos en conjuntos de entrenamiento y prueba.
- Entrene el modelo en nuestro conjunto de datos.
- Pruebe el modelo en el conjunto de prueba.
Entrenando al modelo
Python3
#Converting x into numpy-array
X=np.array(embedded_feel_arr)
print(np.shape(X))
# Perform one-hot encoding on df[0] i.e emotion
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(handle_unknown='ignore')
Y = enc.fit_transform(np.array(df[0]).reshape(-1,1)).toarray()
# Split into train and test
from keras.layers import Embedding
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=42)
#Defining the BiLSTM Model
def model(X,Y,input_size1,input_size2,output_size):
m=Sequential()
# Here 100 denotes the dimensionality of output spaces.
m.add(Bidirectional(LSTM(100,input_shape=(input_size1,input_size2))))
m.add(Dropout(0.5))
m.add(Dense(output_size,activation='softmax'))
m.compile('Adam','categorical_crossentropy',['accuracy'])
m.fit(X,Y,epochs=32, batch_size=128)
return m
Entrenando al modelo
Python3
# Training the model bilstmModel=model(X_train,Y_train,100,50,7)
Este es el diagrama del modelo propuesto:
Aquí, la dimensión de entrada es 100 X 50, donde 100 es la cantidad de palabras en cada oración de entrada del conjunto de datos y 50 representa el mapeo de cada palabra en un vector 50d.
La salida de Bidireccional (LSTM) es 200 porque arriba hemos definido que la dimensionalidad del espacio de salida es 100. Como es un modelo BiLSTM, la dimensionalidad será 100*2 = 200, ya que BiLSTM contiene dos capas LSTM: una hacia adelante y la otra. otro al revés.
Después se agrega esta capa de abandono para evitar el sobreajuste. Y por último, se aplica una capa densa para convertir las 200 secuencias de salida en 7, ya que solo tenemos 7 emociones, por lo que la salida debe ser solo de siete dimensiones.
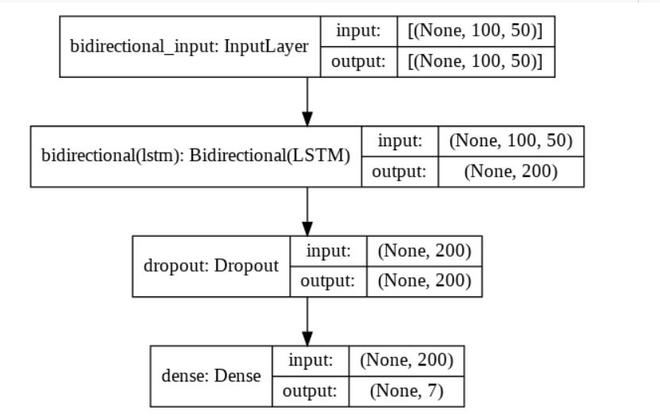
Modelo BiLSTM propuesto
Probando el modelo
Python3
#Testing the model bilstmModel.evaluate(X_test,Y_test)
Esta es la precisión cuando probamos el modelo.
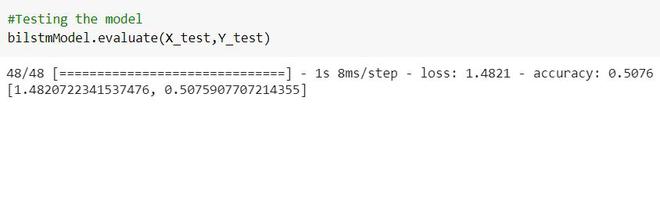
Exactitud de prueba
Para obtener el conjunto de datos y el código, haga clic aquí .