Facebook acaba de lanzar su modelo de detección de objetos de última generación el 27 de mayo de 2020. Lo llaman DERT , que significa Transformador de detección , ya que utiliza transformadores para detectar objetos. Esta es la primera vez que se utiliza un transformador para tal tarea de detección de objetos. junto con una red neuronal convolucional. Hay otros modelos de detección de objetos como la familia RCNN , YOLO(You Look Only Once) y SSD (Single Shot Detection), pero ninguno de ellos ha utilizado nunca un transformador para lograr esta tarea. La mejor parte de este modelo es que, debido al hecho de que usa un transformador, hace que la arquitectura sea muy simple, a diferencia de todas las otras técnicas mencionadas, con todo tipo de hiperparámetros y capas. Así que sin más preámbulos, comencemos.
¿Qué es la detección de objetos?
Dada una foto, si necesita determinar si la foto tiene un solo objeto en particular, puede hacerlo por clasificación. pero si también desea obtener la ubicación de ese objeto dentro de la imagen… bueno, incluso eso no es una tarea de detección de objetos… se llama clasificación y localización. Pero si hay varios objetos en una imagen y desea conocer la ubicación de todos y cada uno de los objetos, eso es detección de objetos.
Algunas de las técnicas anteriores intentan obtener una RPN (Region Proposal Network) para generar regiones potenciales que pueden contener el objeto y luego podemos usar el concepto de cajas de anclaje, NMS (non-max-suppression) y IOU para generar relevantes casillas e identificar el objeto. Aunque estos conceptos funcionan, la inferencia lleva algo de tiempo, por lo que no se logra un uso en tiempo real con alta precisión debido a su complejidad.
En un alto nivel, esto usa CNN y luego un transformador para detectar un objeto y lo hace a través de un objeto de entrenamiento bipartito. Esta es la razón principal por la que es tan simple.
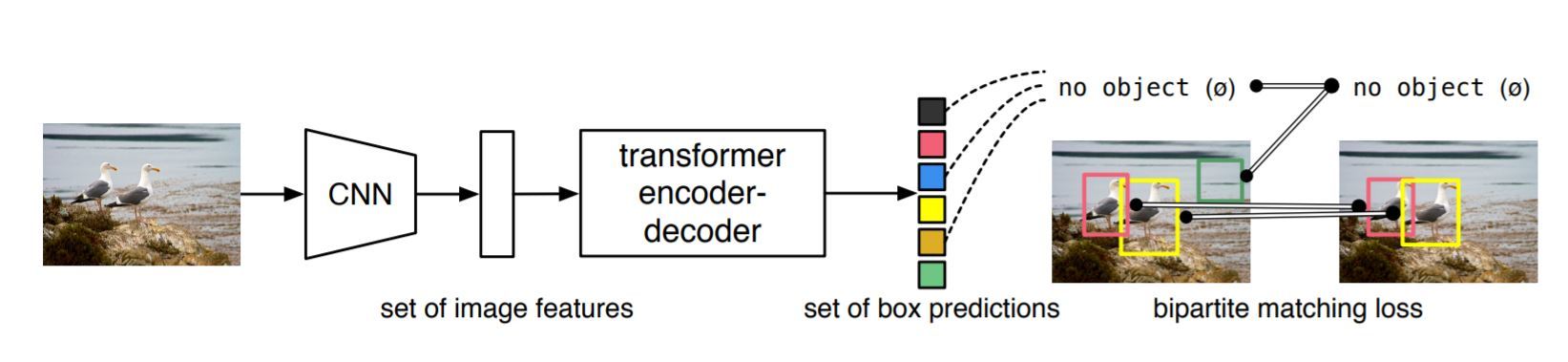
Fuente: https://arxiv.org/pdf/2005.12872.pdf
Paso 1:
Pasamos la imagen a través de un codificador de red neuronal de convolución porque CNN funciona mejor con imágenes. Entonces, después de pasar por CNN, las características de la imagen se conservan. Esta es la representación de orden superior de una imagen con muchos más canales de características.
Paso 2:
este mapa de características enriquecido de la imagen se entrega a un codificador-descodificador de transformador, que genera la predicción del conjunto de cajas. Cada una de estas cajas está formada por una tupla. La tupla será una clase y un cuadro delimitador. Nota: esto también incluye la clase NULL o Nothing y su posición también.
Ahora, este es un problema real ya que en la anotación no hay ninguna clase de objeto anotada como nada. Comparar y tratar con objetos similares uno al lado del otro es otro problema importante y en este documento se aborda mediante el uso de pérdida de coincidencia bipartita. La pérdida se compara comparando cada clase y cuadro delimitador que hay con su clase correspondiente y el cuadro que incluye la clase none, que son digamos N, con la anotación que incluye la parte añadida que no contiene nada para hacer el total de cuadros N. La asignación de lo predicho a lo real es una asignación uno a uno tal que la pérdida total se minimiza. Hay un algoritmo muy famoso llamado método húngaro para calcular estas coincidencias mínimas.
Los componentes principales:
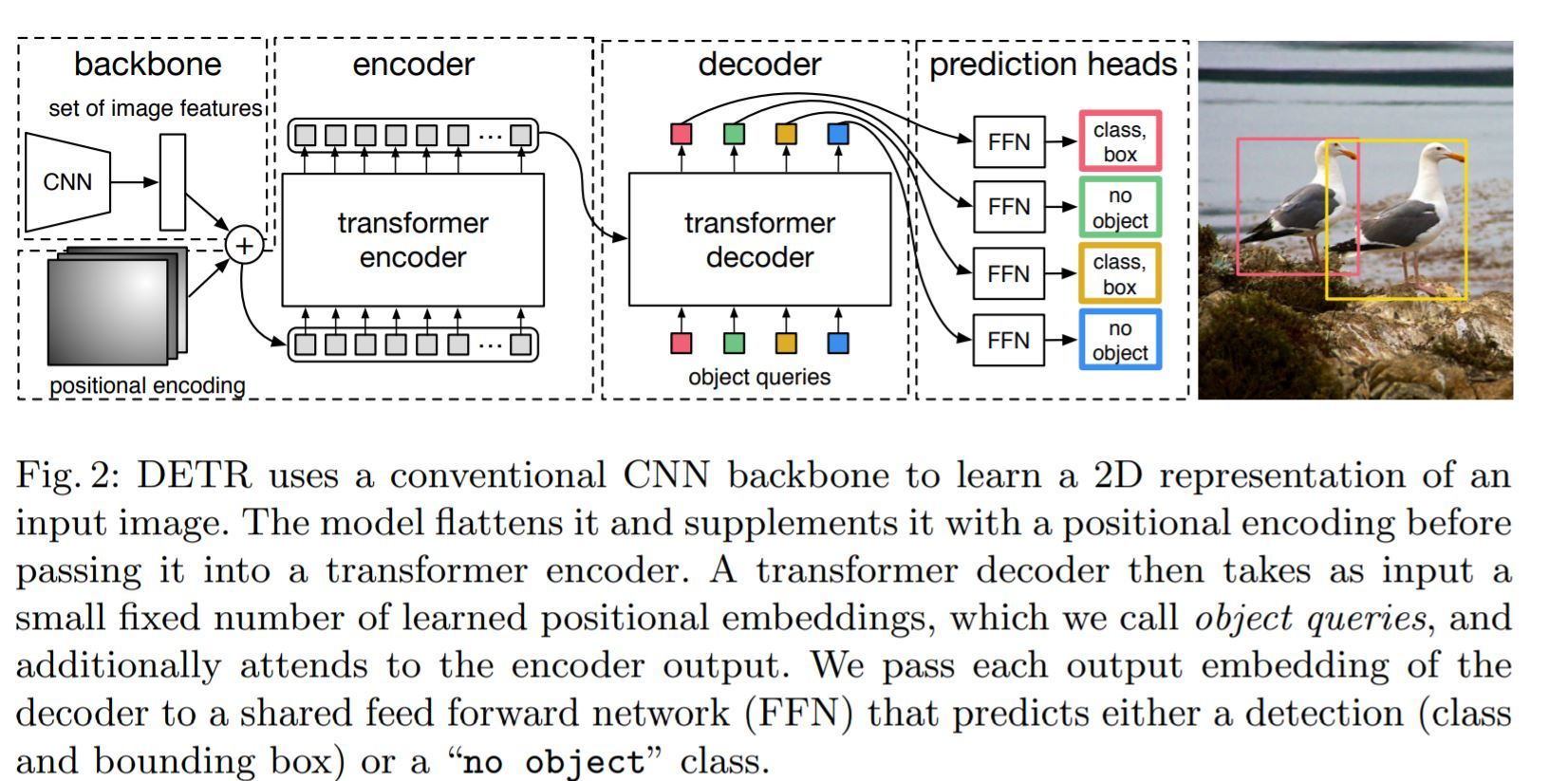
fuente: https://arxiv.org/pdf/2005.12872.pdf
La columna vertebral: se transmiten las características extraídas de una red neuronal convolucional y una codificación posicional
. El codificador del transformador: un transformador es naturalmente una unidad de procesamiento de secuencias y, por la misma razón, los tensores entrantes se aplanan. Transforma la secuencia en una secuencia igualmente larga de características.
El decodificador de transformador: admite consultas de objetos. Por lo tanto, es un decodificador como entrada lateral para la información de acondicionamiento.
Predicción Feed-Forward Network (FFN): el resultado de esto pasa por un clasificador que genera las etiquetas de clase y el resultado del cuadro delimitador discutido anteriormente
Evaluador:
la evaluación se realiza en el conjunto de datos COCOy su principal competidor fue la familia RCNN que ha dominado esta categoría durante algún tiempo y es considerada la técnica más clásica para la detección de objetos.
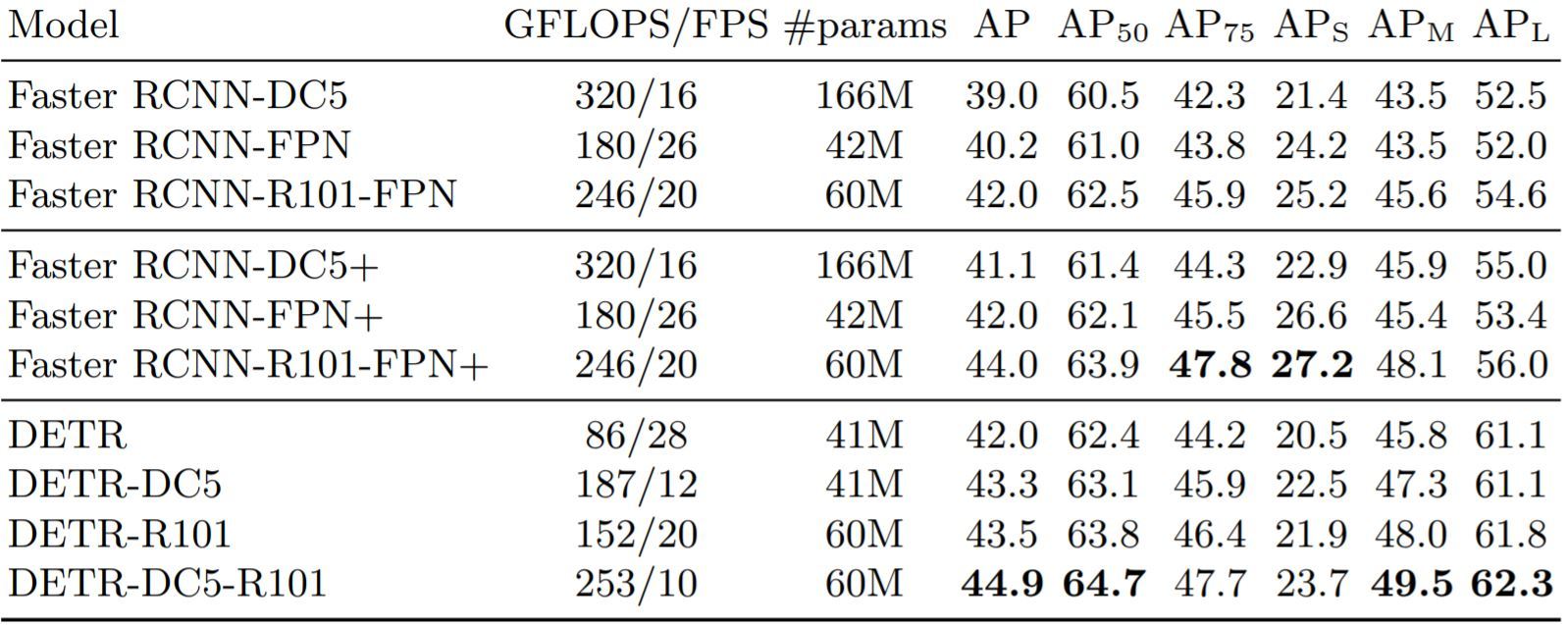
Fuente: https://arxiv.org/pdf/2005.12872.pdf
Ventajas:
- Este nuevo modelo es bastante simple y no es necesario instalar ninguna biblioteca para usarlo.
- DETR demuestra un rendimiento significativamente mejor en objetos grandes y no en un objeto pequeño que se puede mejorar aún más.
- Lo bueno es que incluso han proporcionado el código en el documento, por lo que ahora también lo implementaremos para saber qué es realmente capaz de hacer.
Código:
Python3
# Write Python3 code here import torch from torch import nn from torchvision.models import resnet50 class DETR(nn.Module): def __init__(self, num_classes, hidden_dim, nheads, num_encoder_layers, num_decoder_layers): super().__init__() # We take only convolutional layers from ResNet-50 model self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2]) self.conv = nn.Conv2d(2048, hidden_dim, 1) self.transformer = nn.Transformer(hidden_dim, heads, num_encoder_layers, num_decoder_layers) self.linear_class = nn.Linear(hidden_dim, num_classes + 1) self.linear_bbox = nn.Linear(hidden_dim, 4) self.query_pos = nn.Parameter(torch.rand(100, hidden_dim)) self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2)) self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2)) def forward(self, inputs): x = self.backbone(inputs) h = self.conv(x) H , W = h.shape[-2:] pos = torch.cat([ self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1), self.row_embed[:H].unsqueeze(1).repeat(1, W, 1), ], dim=-1).flatten(0, 1).unsqueeze(1) h = self.transformer(pos + h.flatten(2).permute(2, 0, 1), self.query_pos.unsqueeze(1)) return self.linear_class(h), self.linear_bbox(h).sigmoid() detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6) detr.eval() inputs = torch.randn(1, 3, 800, 1200) logits, bboxes = detr(inputs) <strong>Listing 1: </strong>DETR PyTorch inference code. For clarity, it uses learned positional encodings in the encoder instead of fixed, and positional encodings are added to the input only instead of at each transformer layer. Making these changes requires going beyond PyTorch implementation of transformers, which hampers readability. The entire code to reproduce the experiments will be made available before the conference.
Tomamos solo capas convolucionales del modelo ResNet-50
Código tomado del código en papel
: intente ejecutar este código en colab o simplemente vaya a este enlace, copie y ejecute el archivo completo.
Python3
import torch as th import torchvision.transforms as T import requests from PIL import Image, ImageDraw, ImageFont
Usaremos ResNet 101 como arquitectura troncal y cargaremos esta arquitectura directamente desde Pytorch Hub.
Código:
Python3
model = th.hub.load('facebookresearch/detr', 'detr_resnet101', pretrained=True)
model.eval()
model = model.cuda()
Python3
# standard PyTorch mean-std input image normalization transform = T.Compose([ T.ToTensor(), T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]) CLASSES = [ 'N/A', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table', 'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush' ]
Ingrese la URL de una imagen aquí. El que he usado es https://i.ytimg.com/vi/vrlX3cwr3ww/maxresdefault.jpg
Código:
Python3
url = input()
Visualización de la imagen
Python3
img = Image.open(requests.get(url, stream=True).raw).resize((800,600)).convert('RGB')
img
Código:
Python3
img_tens = transform(img).unsqueeze(0).cuda() with th.no_grad(): output = model(img_tens) draw = ImageDraw.Draw(img) pred_logits=output['pred_logits'][0][:, :len(CLASSES)] pred_boxes=output['pred_boxes'][0] max_output = pred_logits.softmax(-1).max(-1) topk = max_output.values.topk(15) pred_logits = pred_logits[topk.indices] pred_boxes = pred_boxes[topk.indices] pred_logits.shape
Código:
Python3
for logits, box in zip(pred_logits, pred_boxes): cls = logits.argmax() if cls >= len(CLASSES): continue label = CLASSES[cls] print(label) box = box.cpu() * th.Tensor([800, 600, 800, 600]) x, y, w, h = box x0, x1 = x-w//2, x+w//2 y0, y1 = y-h//2, y+h//2 draw.rectangle([x0, y0, x1, y1], outline='red', width=5) draw.text((x, y), label, fill='white')
Código: Visualización de la imagen detectada
Python3
img
Aquí está el enlace al cuaderno de colab y el código de github . Además, no dude en consultar el GitHub oficial para conocer los mismos
inconvenientes:
se tarda una eternidad en entrenar. Entrenó durante seis días en 8 GPU. No es tanto cuando lo comparas con el modelo de lenguaje a esta escala, ya que usan un transformador, pero aún así.
Publicación traducida automáticamente
Artículo escrito por amankrsharma3 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA