En los algoritmos de agrupamiento como el agrupamiento de K-Means, tenemos que determinar el número correcto de agrupamientos para nuestro conjunto de datos. Esto asegura que los datos se dividan de manera adecuada y eficiente. Un valor apropiado de ‘k’, es decir, el número de grupos, ayuda a garantizar la granularidad adecuada de los grupos y ayuda a mantener un buen equilibrio entre la compresibilidad y la precisión de los grupos.
Consideremos dos casos:
Case 1: Treat the entire dataset as one cluster Case 2: Treat each data point as a cluster
Esto dará la agrupación más precisa debido a la distancia cero entre el punto de datos y su centro de agrupación correspondiente. Pero, esto no ayudará a predecir nuevas entradas. No habilitará ningún tipo de resumen de datos.
Por lo tanto, podemos concluir que es muy importante determinar el número «correcto» de grupos para cualquier conjunto de datos. Esta es una tarea desafiante pero muy accesible si dependemos de la forma y la escala de la distribución de datos. Un método simple para calcular el número de conglomerados es establecer el valor en aproximadamente √(n/2) para un conjunto de datos de ‘n’ puntos. En el resto del artículo, se han descrito e implementado dos métodos en Python para determinar el número de clústeres en la minería de datos.
1. Método del codo:
Este método se basa en la observación de que aumentar el número de conglomerados puede ayudar a reducir la suma de la varianza dentro del conglomerado de cada conglomerado. Tener más clústeres permite extraer grupos más finos de objetos de datos que son más similares entre sí. Para elegir el número «correcto» de conglomerados, se utiliza el punto de inflexión de la curva de la suma de las varianzas dentro del conglomerado con respecto al número de conglomerados. El primer punto de inflexión de la curva sugiere el valor correcto de ‘k’ para cualquier k > 0. Implementemos el método del codo en Python.
Paso 1: Importación de las bibliotecas
Python3
# importing the libraries import pandas as pd import matplotlib.pyplot as plt from sklearn.cluster import KMeans
Paso 2: Cargar el conjunto de datos
Hemos utilizado el conjunto de datos de Mall Customer que se puede encontrar en este enlace .
Python3
# loading the dataset
dataset = pd.read_csv('Mall_Customers.csv')
# printing first five rows of the dataset
print(dataset.head(5))
Producción:

Primeras cinco filas del conjunto de datos
Paso 3: Comprobación de cualquier valor nulo
El conjunto de datos tiene 200 filas y 5 columnas. No tiene valores nulos.
Python3
# printing the shape of dataset print(dataset.shape) # checking for any # null values present print(dataset.isnull().sum())
Producción:

Forma del conjunto de datos junto con el recuento de valores nulos
Paso 4: Extraer 2 columnas del conjunto de datos para agrupar
Extraigamos dos columnas, a saber, ‘Ingreso anual (k$)’ y ‘Puntuación de gastos (1-100)’ para continuar con el proceso.
Python3
# extracting values from two # columns for clustering dataset_new = dataset[['Annual Income (k$)', 'Spending Score (1-100)']].values
Paso 5: Determinar el número de conglomerados usando el método del codo y trazando el gráfico
Python3
# determining the maximum number of clusters
# using the simple method
limit = int((dataset_new.shape[0]//2)**0.5)
# selecting optimal value of 'k'
# using elbow method
# wcss - within cluster sum of
# squared distances
wcss = {}
for k in range(2,limit+1):
model = KMeans(n_clusters=k)
model.fit(dataset_new)
wcss[k] = model.inertia_
# plotting the wcss values
# to find out the elbow value
plt.plot(wcss.keys(), wcss.values(), 'gs-')
plt.xlabel('Values of "k"')
plt.ylabel('WCSS')
plt.show()
Producción:
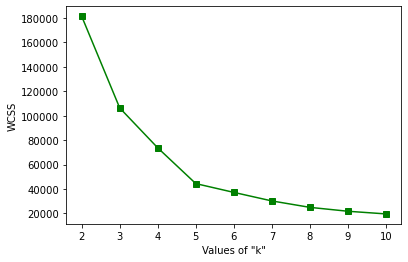
Gráfico del método del codo
A través del gráfico anterior, podemos observar que el punto de inflexión de esta curva está en el valor de k = 5. Por lo tanto, podemos decir que el número «correcto» de grupos para estos datos es 5.
2. Puntuación de la silueta:
La puntuación de silueta se utiliza para evaluar la calidad de los grupos creados mediante algoritmos de agrupación como K-Means en términos de qué tan bien se agrupan los puntos de datos con otros puntos de datos que son similares entre sí. Este método se puede utilizar para encontrar el valor óptimo de ‘k’. Esta puntuación está dentro del rango de [-1,1]. El valor de ‘k’ que tiene la puntuación de la silueta más cercana a 1 puede considerarse como el número ‘correcto’ de grupos. sklearn.metrics.silhouette _score() se usa para encontrar la puntuación en Python. Implementemos esto para el mismo conjunto de datos utilizado en el método del codo.
Paso 1: Importación de bibliotecas
Python3
# importing the libraries import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.metrics import silhouette_score
Paso 2: Cargar el conjunto de datos
Hemos utilizado el conjunto de datos del cliente del centro comercial.
Python3
# loading the dataset
dataset = pd.read_csv('Mall_Customers.csv')
# printing first five rows of the dataset
print(dataset.head(5))
Producción:
Primeras cinco filas del conjunto de datos
Paso 3: Comprobación de cualquier valor nulo
El conjunto de datos tiene 200 filas y 5 columnas. No tiene valores nulos.
Python3
# printing the shape of dataset print(dataset.shape) # checking for any # null values present print(dataset.isnull().sum())
Producción:
Forma del conjunto de datos junto con el recuento de valores nulos
Paso 4: Extraer 2 columnas del conjunto de datos para agrupar
Extraigamos dos columnas, a saber, ‘Ingreso anual (k$)’ y ‘Puntuación de gastos (1-100)’ para continuar con el proceso.
Python3
# extracting values from two # columns for clustering dataset_new = dataset[['Annual Income (k$)', 'Spending Score (1-100)']].values
Paso 5: Determinación del número de conglomerados utilizando la puntuación de silueta
El número mínimo de grupos necesarios para calcular la puntuación de la silueta es 2. Por lo tanto, el ciclo comienza desde 2.
Python3
# determining the maximum number of clusters
# using the simple method
limit = int((dataset_new.shape[0]//2)**0.5)
# determining number of clusters
# using silhouette score method
for k in range(2, limit+1):
model = KMeans(n_clusters=k)
model.fit(dataset_new)
pred = model.predict(dataset_new)
score = silhouette_score(dataset_new, pred)
print('Silhouette Score for k = {}: {:<.3f}'.format(k, score))
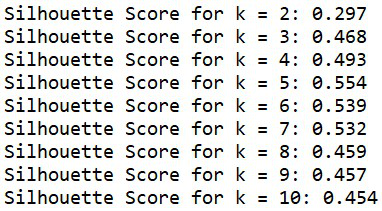
Puntuaciones de silueta para k = [2,..,10]
Como podemos observar, el valor de k = 5 tiene el valor más alto, es decir, el más cercano a +1. Entonces, podemos decir que el valor óptimo de ‘k’ es 5.
Ahora, hemos determinado y validado correctamente la cantidad de grupos para el conjunto de datos de clientes del centro comercial utilizando dos métodos: el método del codo y la puntuación de la silueta. En ambos casos, k = 5. Realicemos ahora el agrupamiento de KMeans en el conjunto de datos y tracemos los agrupamientos.
Python3
# clustering the data using Kmeans
# using k = 5
model = KMeans(n_clusters=5)
# predicting the clusters
pred = model.fit_predict(dataset_new)
# plotting all the clusters
colours = ['red', 'blue', 'green', 'yellow', 'orange']
for i in np.unique(model.labels_):
plt.scatter(dataset_new[pred==i, 0],
dataset_new[pred==i, 1],
c = colours[i])
# plotting the cluster centroids
plt.scatter(model.cluster_centers_[:, 0],
model.cluster_centers_[:, 1],
s = 200, # marker size
c = 'black')
plt.title('K Means clustering')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.show()

Grupos finales así formados
Del gráfico anterior, podemos ver que se han formado cinco grupos eficientes que son claramente separables entre sí. Los centroides del grupo también son visibles en color negro.
Publicación traducida automáticamente
Artículo escrito por riyaaggarwal y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA