Si alguna vez quiso escribir un programa o software grande, el error de novato más común es saltar directamente e intentar escribir todo el código necesario en un solo programa y luego intentar depurarlo o extenderlo más tarde.
Este tipo de enfoque está condenado al fracaso y, por lo general, requeriría volver a escribir desde cero.
Entonces, para abordar este escenario, podemos tratar de dividir el problema en múltiples subproblemas y luego tratar de abordarlo uno por uno.
Al hacerlo, no solo facilita nuestra tarea, sino que también nos permite lograr la abstracción del programador de alto nivel y también promueve la reutilización del código.
Si revisa cualquier proyecto de código abierto de GitHub o GitLab o cualquier otro sitio similar, podemos ver cómo el gran programa está «descentralizado» en muchos submódulos donde cada módulo individual contribuye a una función crítica específica de el programa y también varios miembros de la comunidad de código abierto se unen para contribuir o mantener dicho(s) archivo(s) o repositorio.
Ahora, la gran pregunta radica en cómo «desglosar» no teóricamente sino PROGRAMÁTICAMENTE .
Veremos varios tipos de tales divisiones en lenguajes populares como C/C++, Python y Java.
C/C++
Para fines ilustrativos,
Supongamos que tenemos todas las inserciones básicas de listas enlazadas dentro de un solo programa. Dado que hay muchos métodos (funciones), no podemos abarrotar el programa escribiendo todas las definiciones de métodos encima de la función principal obligatoria. Pero incluso si lo hiciéramos, puede surgir el problema de ordenar los métodos, donde un método debe estar antes que otro y así sucesivamente.
Entonces, para resolver este problema, podemos declarar todos los prototipos al comienzo del programa, seguidos del método principal y debajo de él, podemos definirlos en cualquier orden en particular:
Programa:
FullLinkedList.c
// Full Linked List Insertions
#include <stdio.h>
#include <stdlib.h>
//--------------------------------
// Declarations - START:
//--------------------------------
struct Node;
struct Node* create_node(int data);
void b_insert(struct Node** head, int data);
void n_insert(struct Node** head, int data, int pos);
void e_insert(struct Node** head, int data);
void display(struct Node* temp);
//--------------------------------
// Declarations - END:
//--------------------------------
int main()
{
struct Node* head = NULL;
int ch, data, pos;
printf("Linked List: \n");
while (1) {
printf("1.Insert at Beginning");
printf("\n2.Insert at Nth Position");
printf("\n3.Insert At Ending");
printf("\n4.Display");
printf("\n0.Exit");
printf("\nEnter your choice: ");
scanf("%d", &ch);
switch (ch) {
case 1:
printf("Enter the data: ");
scanf("%d", &data);
b_insert(&head, data);
break;
case 2:
printf("Enter the data: ");
scanf("%d", &data);
printf("Enter the Position: ");
scanf("%d", &pos);
n_insert(&head, data, pos);
break;
case 3:
printf("Enter the data: ");
scanf("%d", &data);
e_insert(&head, data);
break;
case 4:
display(head);
break;
case 0:
return 0;
default:
printf("Wrong Choice");
}
}
}
//--------------------------------
// Definitions - START:
//--------------------------------
struct Node {
int data;
struct Node* next;
};
struct Node* create_node(int data)
{
struct Node* temp
= (struct Node*)
malloc(sizeof(struct Node));
temp->data = data;
temp->next = NULL;
return temp;
}
void b_insert(struct Node** head, int data)
{
struct Node* new_node = create_node(data);
new_node->next = *head;
*head = new_node;
}
void n_insert(struct Node** head, int data, int pos)
{
if (*head == NULL) {
b_insert(head, data);
return;
}
struct Node* new_node = create_node(data);
struct Node* temp = *head;
for (int i = 0; i < pos - 2; ++i)
temp = temp->next;
new_node->next = temp->next;
temp->next = new_node;
}
void e_insert(struct Node** head, int data)
{
if (*head == NULL) {
b_insert(head, data);
return;
}
struct Node* temp = *head;
while (temp->next != NULL)
temp = temp->next;
struct Node* new_node = create_node(data);
temp->next = new_node;
}
void display(struct Node* temp)
{
printf("The elements are:\n");
while (temp != NULL) {
printf("%d ", temp->data);
temp = temp->next;
}
printf("\n");
}
//--------------------------------
// Definitions - END
//--------------------------------
Compilando el código: Podemos compilar el programa anterior mediante:
gcc linkedlist.c -o linkedlist
¡Y funciona!
Problemas subyacentes en el código anterior:
Ya podemos ver los problemas subyacentes con el programa, no es nada fácil trabajar con el código, ni individualmente ni en grupo.
Si alguien quisiera trabajar con el programa anterior, algunos de los muchos problemas que enfrenta esa persona son:
- Necesita revisar el archivo fuente completo para mejorar o mejorar alguna funcionalidad.
- No se puede reutilizar fácilmente el programa como marco para otros proyectos.
- El código está muy desordenado y no es nada atractivo, por lo que es muy difícil navegar por el código.
En el caso de proyectos grupales o programas grandes, se garantiza que el enfoque anterior mejorará el gasto general, la energía y la tasa de fallas.
El enfoque correcto:
Vemos que estas líneas comienzan en cada programa C/C++ que comienza con «#include».
Esto significa incluir todas las funciones declaradas bajo el encabezado «biblioteca» (archivos .h) y posiblemente definidas en los archivos biblioteca.c/cpp .
Estas líneas son procesadas por el preprocesador durante la compilación.
Podemos intentar crear manualmente una biblioteca de este tipo para nuestro propio propósito.
Cosas importantes para recordar:
- Los archivos “.h” contienen solo declaraciones de prototipos (como funciones, estructuras) y variables globales.
- Los archivos “.c/.cpp” contienen la implementación real (Definiciones de declaración en los archivos de encabezado)
- Al compilar todos los archivos fuente, asegúrese de que no haya múltiples definiciones de las mismas funciones, variables, etc. para el mismo proyecto. (MUY IMPORTANTE)
- Use funciones estáticas para restringir al archivo donde se declaran.
- Use la palabra clave extern para usar variables que hagan referencia a archivos externos.
- Si usa C++, tenga cuidado con los espacios de nombres, use siempre namespace_name::function() para evitar colisiones.
Dividir el programa en códigos más pequeños:
al observar el programa anterior, podemos ver cómo este gran programa se puede dividir en partes pequeñas adecuadas y luego trabajar en él fácilmente.
El programa anterior tiene esencialmente 2 funciones principales:
1) Crear, insertar y almacenar datos en Nodes.
2) Mostrar los Nodes
Así que puedo dividir el programa en consecuencia de tal manera que:
1) Archivo principal -> Programa de controlador, Nice Wrapper de los módulos de inserción y donde usamos los archivos adicionales.
2) Insertar -> Aquí se encuentra la implementación real.
Teniendo en cuenta los Puntos Importantes mencionados, el programa se divide en:
linkedlist.c -> Contiene el programa del controlador
insert.c -> Contiene el código para la inserciónlinkedlist.h -> Contiene las declaraciones de Node necesarias
insert.h -> Contiene las declaraciones de inserción de Node necesarias
En cada archivo de encabezado, comenzamos con:
#ifndef FILENAME_H #define FILENAME_H Declarations... #endif
La razón por la que escribimos nuestras declaraciones entre #ifndef, #define y #endif es para evitar múltiples declaraciones de identificadores como tipos de datos, variables, etc. cuando se invoca el mismo archivo de encabezado en un nuevo archivo que pertenece al mismo proyecto.
Para este programa de muestra:
insert.h -> Contiene la declaración de inserción del Node y también la declaración del propio Node.
Una cosa muy importante que debe recordar es que el compilador puede ver las declaraciones en el archivo de encabezado, pero si intenta escribir un código que INVOLUCRE la definición de la declaración declarada en otro lugar, se producirá un error, ya que el compilador compila cada archivo .c individualmente antes de proceder a la etapa de vinculación. .
linkedlist.h -> Un archivo de ayuda que contiene Node y sus declaraciones de visualización que se incluirán para los archivos que las usan.
insert.c -> Incluya la declaración del Node a través de #include «linkedlist.h», que contiene la declaración y también todas las demás definiciones de métodos declarados en insert.h.
linkedlist.c -> Simple Wrapper que contiene un bucle infinito que solicita al usuario que inserte datos enteros en las posiciones requeridas, y también contiene el método que muestra la lista.
Una última cosa a tener en cuenta es que, la inclusión insensata de archivos entre sí puede dar lugar a múltiples redefiniciones y dar como resultado un error.
Teniendo en cuenta lo anterior, debe dividir cuidadosamente en subprogramas adecuados.
linkedlist.h
// linkedlist.h
#ifndef LINKED_LIST_H
#define LINKED_LIST_H
struct Node {
int data;
struct Node* next;
};
void display(struct Node* temp);
#endif
insert.h
// insert.h #ifndef INSERT_H #define INSERT_H struct Node; struct Node* create_node(int data); void b_insert(struct Node** head, int data); void n_insert(struct Node** head, int data, int pos); void e_insert(struct Node** head, int data); #endif
insert.c
// insert.c
#include "linkedlist.h"
// "" to tell the preprocessor to look
// into the current directory and
// standard library files later.
#include <stdlib.h>
struct Node* create_node(int data)
{
struct Node* temp = (struct Node*)malloc(sizeof(struct Node));
temp->data = data;
temp->next = NULL;
return temp;
}
void b_insert(struct Node** head, int data)
{
struct Node* new_node = create_node(data);
new_node->next = *head;
*head = new_node;
}
void n_insert(struct Node** head, int data, int pos)
{
if (*head == NULL) {
b_insert(head, data);
return;
}
struct Node* new_node = create_node(data);
struct Node* temp = *head;
for (int i = 0; i < pos - 2; ++i)
temp = temp->next;
new_node->next = temp->next;
temp->next = new_node;
}
void e_insert(struct Node** head, int data)
{
if (*head == NULL) {
b_insert(head, data);
return;
}
struct Node* temp = *head;
while (temp->next != NULL)
temp = temp->next;
struct Node* new_node = create_node(data);
temp->next = new_node;
}
linkedlist.c
// linkedlist.c
// Driver Program
#include "insert.h"
#include "linkedlist.h"
#include <stdio.h>
void display(struct Node* temp)
{
printf("The elements are:\n");
while (temp != NULL) {
printf("%d ", temp->data);
temp = temp->next;
}
printf("\n");
}
int main()
{
struct Node* head = NULL;
int ch, data, pos;
printf("Linked List: \n");
while (1) {
printf("1.Insert at Beginning");
printf("\n2.Insert at Nth Position");
printf("\n3.Insert At Ending");
printf("\n4.Display");
printf("\n0.Exit");
printf("\nEnter your choice: ");
scanf("%d", &ch);
switch (ch) {
case 1:
printf("Enter the data: ");
scanf("%d", &data);
b_insert(&head, data);
break;
case 2:
printf("Enter the data: ");
scanf("%d", &data);
printf("Enter the Position: ");
scanf("%d", &pos);
n_insert(&head, data, pos);
break;
case 3:
printf("Enter the data: ");
scanf("%d", &data);
e_insert(&head, data);
break;
case 4:
display(head);
break;
case 0:
return 0;
default:
printf("Wrong Choice");
}
}
}
Finalmente, los guardamos todos y compilamos de la siguiente manera.
gcc insert.c linkedlist.c -o linkedlistListo, se compiló con éxito, solo hagamos una verificación rápida de cordura, por si acaso:
Producción:
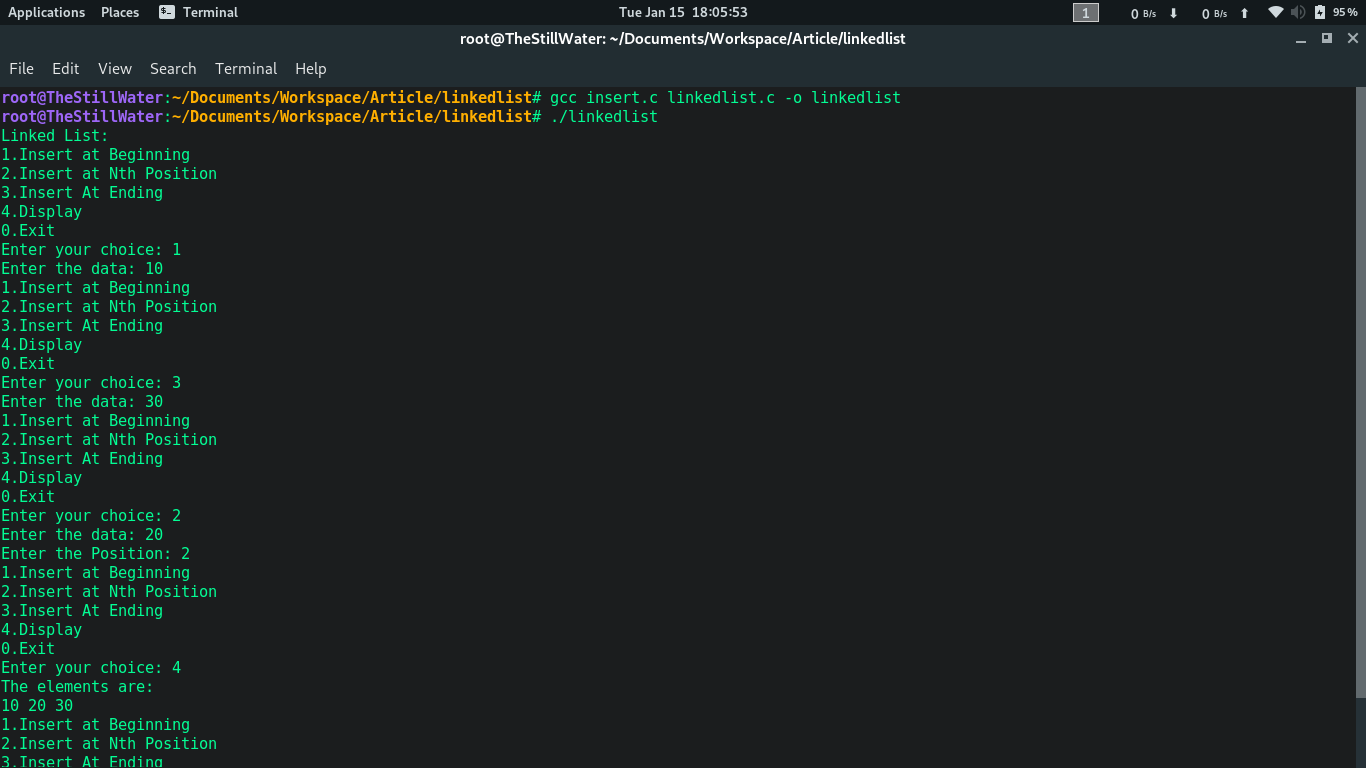
Sigue siendo prácticamente igual para C++, dejando de lado los cambios habituales de implementación/características del lenguaje.
Python
Aquí no es tan difícil. Por lo general, lo primero que se debe hacer es crear un entorno virtual . Es imprescindible para evitar la ruptura de un montón de scripts debido a varias dependencias de versión y demás. Por ejemplo, es posible que desee usar la versión 1.0 de algún módulo para un proyecto, pero esta última versión dejó de usar una función que está disponible en 0.9 y prefiere usar la versión anterior para este nuevo proyecto o simplemente desea actualizar las bibliotecas sin romper proyectos antiguos y existentes. La solución es un entorno aislado para cada proyecto/script por separado.
Cómo instalar Virtual Env:
use pip o pip3 para instalar virtualenv si aún no está instalado:
pip install virtualenvConfiguración de un entorno aislado para cada proyecto/secuencia de comandos:
A continuación, navegue hasta algún directorio para almacenar sus proyectos y luego:
virtualenv nombre_aplicación # (O)
virtualenv -p /ruta/a/py3(o)2.7 nombre_aplicación # Para
fuentes específicas de dependencia del intérprete nombre_aplicación/bin/activar # Comenzar a trabajar
desactivar # Para salir
Ahora puede usar pip para instalar todos los módulos deseados y actúan como independientes para este proyecto aislado y no necesita preocuparse por la ruptura de secuencias de comandos en todo el sistema. por ejemplo: con el entorno virtual y la fuente activados,
pip install pip install pandas==0.22.0
Una cosa importante que debe hacer es crear un archivo vacío explícito llamado:
__init__.pyEsto se hace para tratar el directorio como si contuviera paquetes y acceder a los submódulos dentro del directorio. Si no crea dicho archivo, Python no buscará explícitamente submódulos dentro del directorio del proyecto y cualquier intento de acceder a ellos genera un error.
Importación de los módulos guardados anteriormente en archivos nuevos:
ahora puede comenzar a importar los módulos guardados anteriormente en archivos nuevos de cualquiera de las siguientes formas:
import module
from module import submodule # (o) from module.submodule import subsubmodule1, subsubmodule2
from module import * # (o) from module.submodule import *
La primera línea le permite acceder a las referencias a través de module.feature() o module.variable.
La segunda línea le permite acceder directamente a la referencia del módulo específico mencionado. por ejemplo: función()
La tercera línea le permite acceder a todas las referencias directamente. por ejemplo: característica1(), característica2() etc.
Ejemplo de un solo archivo desordenado:
Point.py
# point.py
class Point:
def __init__(self):
self.x = int(input ("Enter the x-coordinate: "))
self.y = int(input ("Enter the y-coordinate: "))
def distance (self, other):
return ((self.x - other.x)**2 + (self.y - other.y)**2) ** 0.5
if __name__ == "__main__":
print("Point 1")
p1 = Point ()
print("\nPoint 2")
p2 = Point ()
print( "Distance between the 2 points is {:.4f}".format (p1.distance(p2)))
El aspecto extraño ‘ if __name__ == “__main__”: ‘ se usa para evitar la ejecución del código debajo de él cuando se importa en otros módulos.
Simplemente podemos abstraer la implementación de puntos en un archivo separado y usar un archivo principal para cumplir con nuestro requisito exacto.
Dividiendo el código en partes más pequeñas:
El programa se puede dividir de manera que:
1) Archivo principal -> Programa controlador, crear, manipular y usar objetos.
2) Archivo de Puntos -> Todos los métodos que podemos definir usando un Punto en el plano cartesiano.
Este programa de ejemplo contiene:
Helper.py -> Que consiste en una clase Point que contiene métodos como la distancia y también consta del método init que ayuda a inicializar automáticamente las variables x e y requeridas.
Main.py -> Programa principal que crea 2 objetos y encuentra la distancia entre ellos.
Helper.py
# Helper.py
class Point:
def __init__(self):
self.x = int(input ("Enter the x-coordinate: "))
self.y = int(input ("Enter the y-coordinate: "))
def distance (self, other):
return ((self.x - other.x)**2 + (self.y - other.y)**2) ** 0.5
Main.py
# Main.py
from Helper import Point
def main ():
print("Point 1")
p1 = Point ()
print("\nPoint 2")
p2 = Point ()
print( "Distance between the 2 points is {:.4f}".format (p1.distance(p2)))
main ()
Producción:
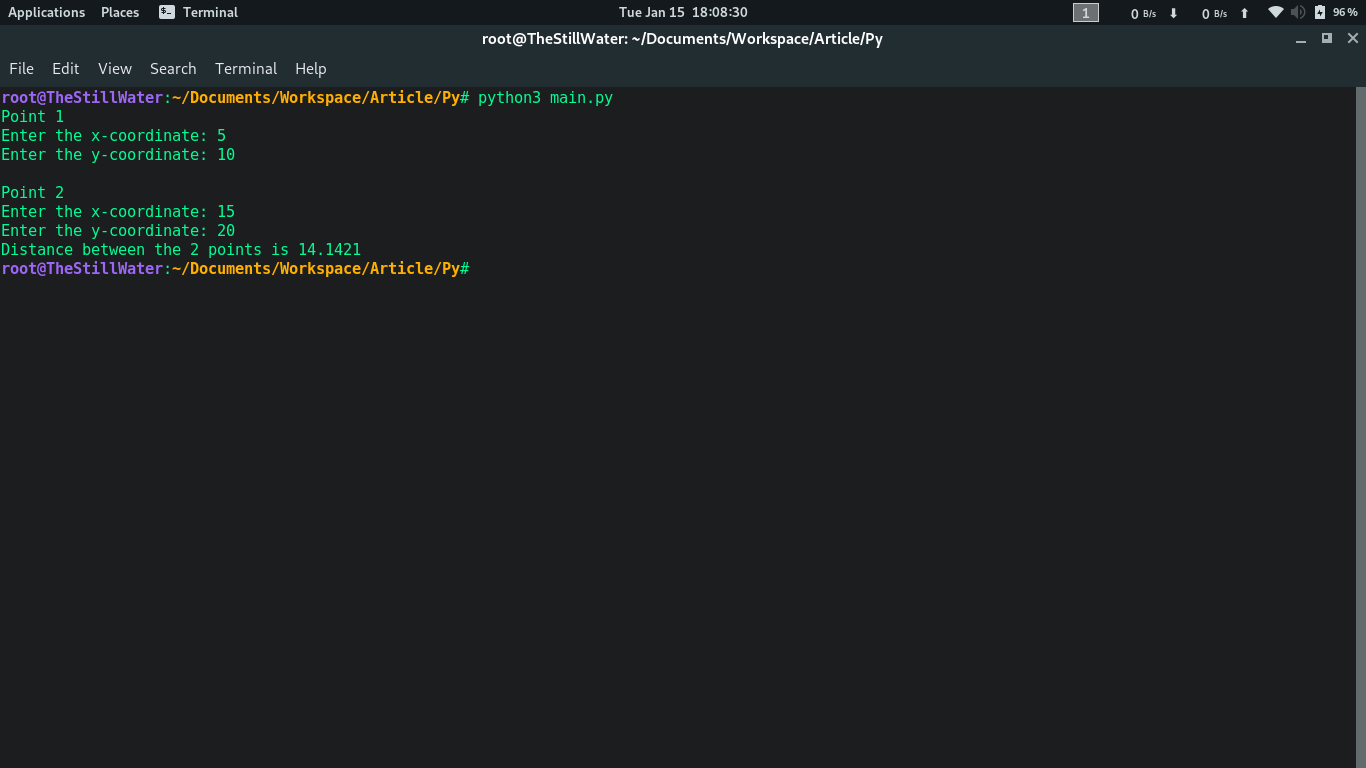
Java
Es similar a Python. Navegue al nuevo directorio para guardar los archivos del proyecto y en todo el subprograma escriba:
package app_name;En la línea de salida, y crea una clase como de costumbre.
Importe el módulo en el nuevo programa Java escribiendo nuevamente: paquete nombre_aplicación y simplemente haga referencia a ese módulo en particular . función() ya que pertenecen al mismo paquete (están almacenados en el mismo directorio) y Java agrega implícitamente las siguientes líneas, pero si necesita importar nuevo módulo(s) de diferentes paquetes y luego hágalo de la siguiente manera:
import package.*; import package.classname; import static package.*; Fully Qualified Name // eg: package.classname ob = new classname ();
La primera y la segunda forma de parecerse a la sintaxis de importación de python, pero debe indicar explícitamente la clase. Para lograr una forma no recomendada pero pythonica de … estilo de sintaxis de importación , debe usar el tercer método, es decir, importar estática para lograr resultados similares, pero debe recurrir al uso de un nombre completamente calificado para evitar colisiones y aclarar humanos. malentendidos de todos modos.
Ejemplo de un solo archivo desordenado:
Check.java
// Check.java
import java.util.*;
class Math {
static int check(int a, int b)
{
return a > b ? 'a' : 'b';
}
}
class Main {
public static void main(String args[])
{
Scanner s = new Scanner(System.in);
System.out.print("Enter value of a: ");
int a = s.nextInt();
System.out.print("Enter value of b: ");
int b = s.nextInt();
if (a == b)
System.out.println("Both Values are Equal");
else
System.out.printf("%c's value is Greater\n",
Math.check(a, b));
}
}
Una vez más, existe un ámbito de división y abstracción. Podemos crear Múltiples archivos independientes que se ocupan de los números y aquí para el ejemplo, podemos dividir
Dividir el código en partes más pequeñas:
el programa se puede dividir de manera que:
1) Archivo principal -> Programa controlador, escriba el código manipulativo aquí.
2) Archivo matemático -> Todos los métodos relacionados con las matemáticas (aquí Función de verificación parcialmente implementada).
El programa de muestra contiene:
Math.java -> Que pertenece al paquete foo y una clase Math que consiste en la verificación de métodos que solo puede comparar 2 números. excluyendo la desigualdad.
Main.java -> Main Program toma 2 números como entrada e imprime el mayor de 2.
Math.java
// Math.java
package foo;
public class Math {
public static int check(int a, int b)
{
return a > b ? 'A' : 'B';
}
}
Main.java
// Main.java
// Driver Program
package foo;
import java.util.*;
class Main {
public static void main(String args[])
{
Scanner s = new Scanner(System.in);
System.out.print("Enter value of a: ");
int a = s.nextInt();
System.out.print("Enter value of b: ");
int b = s.nextInt();
if (a == b)
System.out.println("Both Values are Equal");
else
System.out.printf("%c's value is Greater\n",
Math.check(a, b));
}
}
Compilacion:
javac -d /path file1.java file2.java
A veces, es posible que desee configurar su classpath para que apunte a algún lugar, use:
establecer classpath= ruta/a/ubicación
// (o) pase el conmutador para java y javac como
javac -cp /ruta/al/archivo de ubicación.java// (o)
java -classpath /ruta/al/archivo de ubicación
De forma predeterminada, apunta al directorio actual, es decir, “ . ”
Ejecutando el código:
java packagename.Main // Aquí en el ejemplo es: “java foo.Main”
Producción: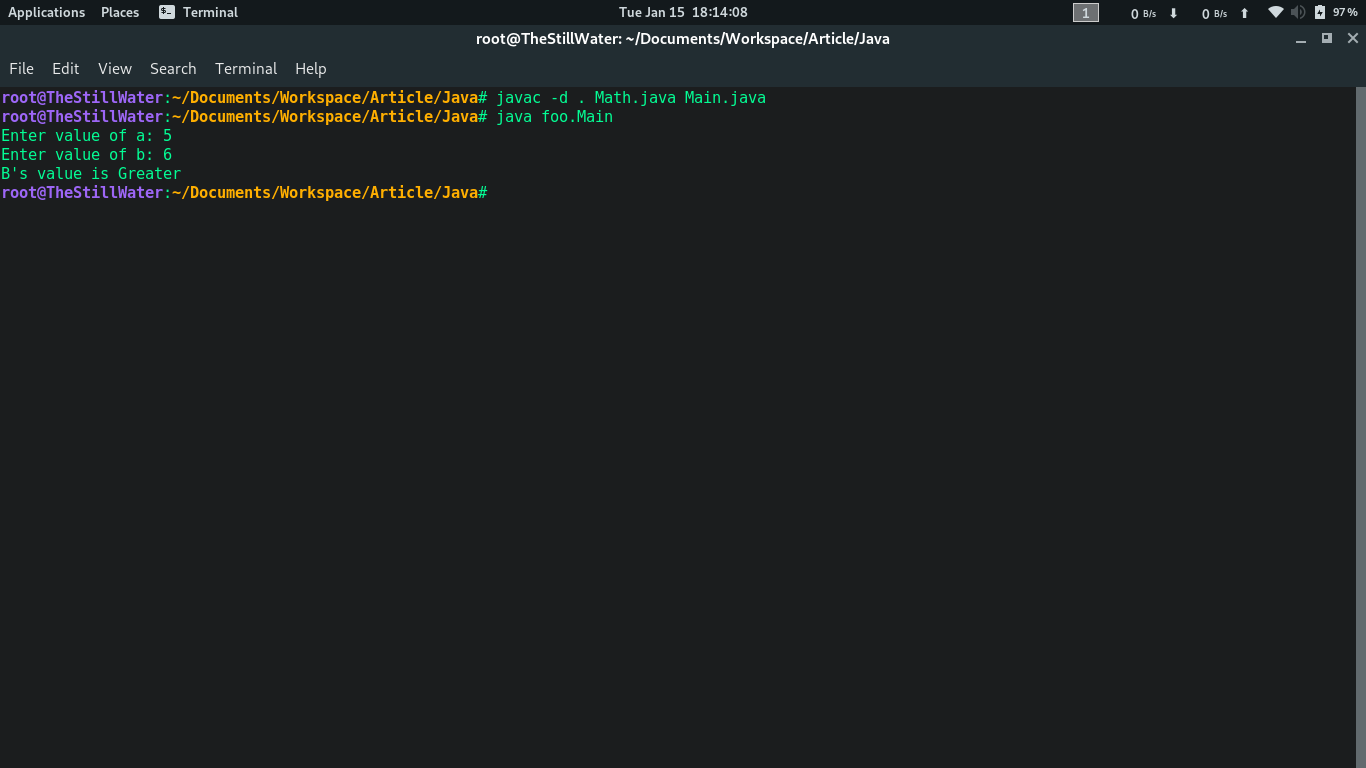
Publicación traducida automáticamente
Artículo escrito por TheStillWater y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA