Kaggle es una comunidad en línea de científicos de datos e ingenieros de aprendizaje automático propiedad de Google . Un sentimiento general de los principiantes en el campo del aprendizaje automático y la ciencia de datos hacia el sitio web es de vacilación. Este sentimiento surge principalmente debido a los conceptos erróneos que las personas externas tienen sobre el sitio web. Éstos son algunos de ellos –
Kaggle es un sitio web de alojamiento de concursos de aprendizaje automático : este concepto erróneo está muy extendido porque muchas organizaciones organizan concursos de aprendizaje automático para contratar científicos de datos o para obtener una solución a un problema al que se enfrenta. Los usuarios y equipos con las mejores soluciones a menudo son recompensados con premios en efectivo. Además de los concursos de alojamiento, el sitio web también alberga una gran cantidad de conjuntos de datos. Los usuarios también son recompensados por los mejores conjuntos de datos.
Solo los PhD y los científicos de datos pueden ganar las competencias : esta es la historia de un niño de secundaria que estaba muy interesado en el tema que aprendió por sí mismo. No aprendió sobre las complicadas matemáticas detrás de los algoritmos y, en cambio, obtuvo un sentido lógico de las técnicas.
Las personas piensan que no son lo suficientemente buenas para participar en las competencias : como proceso de aprendizaje, uno debe centrarse en la parte exploratoria y la ingeniería de funciones de un proyecto de aprendizaje automático.
Para comenzar con Kaggle, se debe seguir un esquema general de pasos:
Paso #1: elegir un lenguaje de programación :
Python y R son los dos lenguajes de programación más famosos para la ciencia de datos y el aprendizaje automático. Por lo general, si una persona tiene experiencia en desarrollo, se prefiere Python, mientras que si una persona tiene experiencia en estadística/análisis, se prefiere R. En un consenso general, se prefiere Python porque es un lenguaje de programación de propósito general y puede adaptarse a las necesidades del usuario.
Paso #2: Aprender los conceptos básicos del análisis exploratorio :
como se indicó anteriormente, uno debe concentrarse en realizar el análisis exploratorio de los datos proporcionados. También se debe aprender a visualizar los datos y, en general, las bibliotecas de Python, Matplotlib y Seaborn , se consideran excelentes puntos de partida.
Paso n.º 3: aprender los conceptos básicos para entrenar un modelo :
antes de profundizar en Kaggle, uno debe tener un poco de experiencia en el entrenamiento de un modelo de aprendizaje. En general, la biblioteca de Python Sklearn se considera la mejor para este propósito.
Paso #4: Entrar en Kaggle :
Kaggle tiene muchas categorías diferentes de competencias. Una de ellas es la categoría ‘Primeros pasos’, que está estructurada como las principales competiciones que recompensan con dinero. Estas competencias tienen conjuntos de datos más fáciles y tutoriales creados por la comunidad.
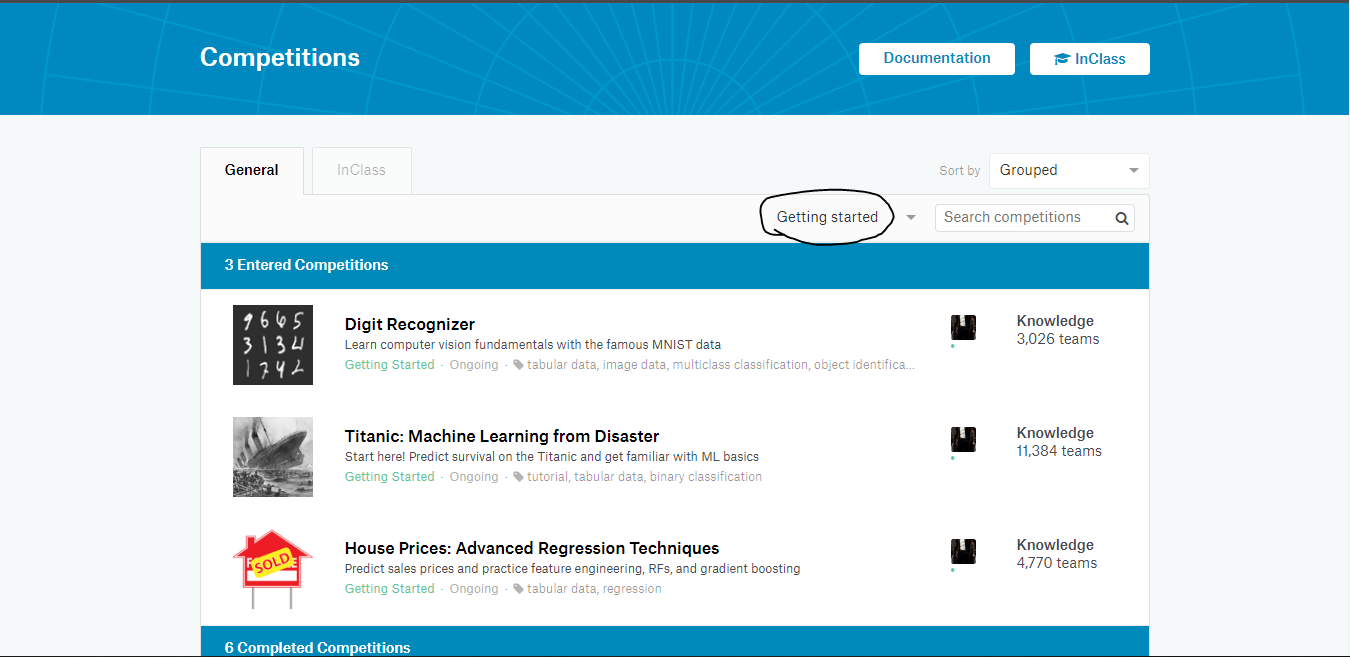
Paso #5: Compite para aprender :
uno debe competir en el sitio web con la intención de aprender y no de ganar dinero.
Paso n.º 6: haga referencia a los núcleos votados : los
núcleos en Kaggle son una forma de compartir sus cuadernos virtuales de Jupyter y ejecutarlos en la nube. Muchos ganadores tienen entrevistas públicas sobre su proceso de pensamiento. Uno puede consultar los otros núcleos votados para aprender y ampliar su espacio de pensamiento.
Kaggle es un gran trampolín y debería ser parte de cada futuro ingeniero de aprendizaje automático y científico de datos.
Publicación traducida automáticamente
Artículo escrito por AlindGupta y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA