En este artículo, implementaremos y entrenaremos una red neuronal convolucional CNN utilizando TensorFlow, una biblioteca de aprendizaje automático masivo.
Ahora, en este artículo, vamos a trabajar en un conjunto de datos llamado ‘rock_paper_sissors’ en el que simplemente debemos clasificar los signos de las manos como piedra, papel o tijera.
Implementación paso a paso
Paso 1: Importación de las bibliotecas
Vamos a comenzar con la importación de algunas bibliotecas importantes. Son TensorFlow, NumPy, Matplotlib y, finalmente, de TensorFlow, necesitamos conjuntos de datos de TensorFlow y Keras.
Python
pip install -q tensorflow tensorflow-datasets # Importing the packages import matplotlib.pyplot as plt import numpy as np import tensorflow as tf import tensorflow_datasets as tfds from tensorflow import keras
Paso 2: Cargar el conjunto de datos
Antes de elegir el conjunto de datos, no dude en explorar todos los conjuntos de datos disponibles en TensorFlow
Python
tfds.list_builders()
Producción:
['abstract_reasoning', 'accentdb', 'aeslc', 'aflw2k3d', 'ag_news_subset', 'ai2_arc', 'ai2_arc_with_ir', 'amazon_us_reviews', 'anli', 'arc', 'bair_robot_pushing_small', 'bccd', 'beans', 'big_patent', .... .. .
Antes de cargar el conjunto de datos, veremos información sobre nuestro conjunto de datos para que nos resulte fácil trabajar con los datos y recopilar información muy importante.
Python
# Getting info about the dataset
Dataset = tfds.builder('rock_paper_scissors')
info = Dataset.info
print(info)
Producción:
tfds.core.DatasetInfo(
name='rock_paper_scissors',
full_name='rock_paper_scissors/3.0.0',
description="""
Images of hands playing rock, paper, scissor game.
""",
homepage='http://laurencemoroney.com/rock-paper-scissors-dataset',
data_path='C:\\Users\\ksaty\\tensorflow_datasets\\rock_paper_scissors\\3.0.0',
download_size=Unknown size,
dataset_size=Unknown size,
features=FeaturesDict({
'image': Image(shape=(300, 300, 3), dtype=tf.uint8),
'label': ClassLabel(shape=(), dtype=tf.int64, num_classes=3),
}),
supervised_keys=('image', 'label'),
disable_shuffling=False,
splits={
},
citation="""@ONLINE {rps,
author = "Laurence Moroney",
title = "Rock, Paper, Scissors Dataset",
month = "feb",
year = "2019",
url = "http://laurencemoroney.com/rock-paper-scissors-dataset"
}""",
)
Finalmente cargando el conjunto de datos,
Python
# Loading the dataset ds_train = tfds.load(name="rock_paper_scissors", split="train") ds_test = tfds.load(name="rock_paper_scissors", split="test")
Producción:
Descargando y preparando el conjunto de datos Tamaño desconocido (descargar: Tamaño desconocido, generado: Tamaño desconocido, total: Tamaño desconocido) a C:\Users\ksaty\tensorflow_datasets\rock_paper_scissors\3.0.0…
Dl Completado…: 100%
2/2 [00:50<00:00, 25.01s/url]
Tamaño Dl…: 100%
219/219 [00:50<00:00, 4,38 MB/s]
Conjunto de datos rock_paper_scissors descargado y preparado en C:\Users\ksaty\tensorflow_datasets\rock_paper_scissors\3.0.0. Las llamadas posteriores reutilizarán estos datos.
Algunos de los ejemplos

Paso 3: Análisis y preprocesamiento de las imágenes
Primero, para mantenerlo limpio, iteramos sobre los datos y los almacenamos como una array NumPy y cancelamos las dimensiones de la imagen y la almacenamos como train_images, y probamos las imágenes con etiquetas.
Python
# Iterating over the images and storing # it in train and test datas train_images = np.array([image['image'].numpy()[:, :, 0] for image in ds_train]) train_labels = np.array([image['label'] .numpy() for image in ds_train]) test_images = np.array([image['image'].numpy()[:, :, 0] for image in ds_test]) test_labels = np.array([image['label'].numpy() for image in ds_test])
y luego, ahora vamos a remodelar las imágenes y luego convertir el tipo de datos a float32 desde uint8, y luego vamos a bajar todos los valores de 0 a 1 para que sea más fácil para el modelo aprender de él.
Python
# Reshaping the images
train_images = train_images.reshape(2520, 300, 300, 1)
test_images = test_images.reshape(372, 300, 300, 1)
# Changing the datatype
train_images = train_images.astype('float32')
test_images = test_images.astype('float32')
# getting the values down to 0 and 1
train_images /= 255
test_images /= 255
Paso 4: Una red neuronal convolucional básica
Ahora vamos a crear una CNN básica con solo 2 capas convolucionales con una función de activación relu y 64 y 32 kernels y un tamaño de kernel de 3 y aplanar la imagen a una array 1D y las capas convolucionales están directamente conectadas a la capa de salida.
Y para compilar usamos el optimizador Adam y para la pérdida usamos SparseCategoricalCrossentropy() y para las métricas, usamos la precisión y vamos a ajustar los datos.
Python
# A convolutional neural network # Defining the model model = keras.Sequential([ keras.layers.Conv2D(64, 3, activation='relu', input_shape=(300, 300, 1)), keras.layers.Conv2D(32, 3, activation='relu'), keras.layers.Flatten(), keras.layers.Dense(3, activation='softmax') ]) # Compiling the model model.compile(optimizer='adam', loss=keras.losses.SparseCategoricalCrossentropy(), metrics=['accuracy']) # Fitting the model with data model.fit(train_images, train_labels, epochs=5, batch_size=32)
Producción:
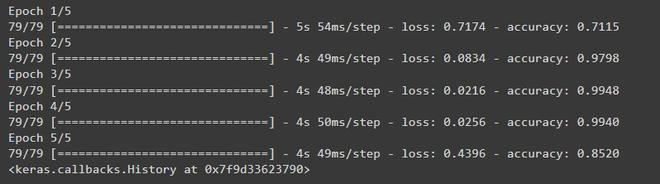
Y para evaluar el modelo.
Python
model.evaluate(test_images, test_labels)

Como puede ver, hay una precisión muy baja en los datos no vistos, esto se llama sobreajuste del modelo, lo que significa que el modelo está sobreajustado por los datos de entrenamiento, por lo que no puede manejar los datos no vistos. Para resolver esto, podemos modificar el modelo un poco.
Mejor red neuronal convolucional
Podemos mejorar este modelo agregando:
- Nodes de abandono
- puesta en común
- Capas densas totalmente conectadas
Python
# A better convolutional neural network # Model defining model = keras.Sequential([ keras.layers.AveragePooling2D(6, 3, input_shape=(300, 300, 1)), keras.layers.Conv2D(64, 3, activation='relu'), keras.layers.Conv2D(32, 3, activation='relu'), keras.layers.MaxPool2D(2, 2), keras.layers.Dropout(0.5), keras.layers.Flatten(), keras.layers.Dense(128, activation='relu'), keras.layers.Dense(3, activation='softmax') ]) # Compiling a model model.compile(optimizer='adam', loss=keras.losses.SparseCategoricalCrossentropy(), metrics=['accuracy']) # Fitting the model model.fit(train_images, train_labels, epochs=5, batch_size=32)
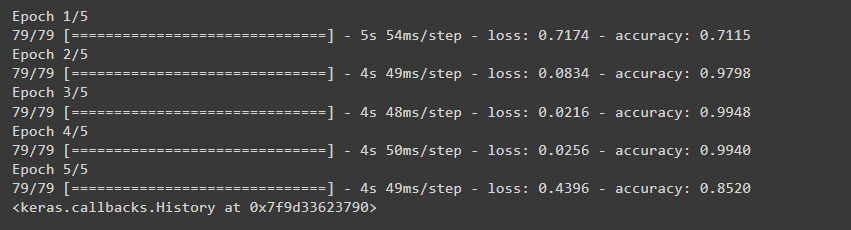
Ahora si evaluamos nuestro modelo, como pueden ver el modelo ha mejorado mucho.

Estos son los pasos para entrenar una red neuronal convolucional.
Nota: Todavía puede hacer algunos ajustes y giros al modelo para aumentar la precisión. TI es un proceso de aprendizaje continuo.
Publicación traducida automáticamente
Artículo escrito por sanjaysdev0901 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA