Prerrequisito: Primeros pasos con la clasificación/
La clasificación es quizás la tarea de aprendizaje automático más común. Antes de pasar a los clasificadores One-vs-Rest (OVR) y cómo funcionan, puede seguir el enlace a continuación y obtener una breve descripción general de qué es la clasificación y cómo es útil.
En general, existen dos tipos de algoritmos de clasificación:
- Algoritmos de clasificación binaria.
- Algoritmos de clasificación multiclase.
La clasificación binaria es cuando tenemos que clasificar los objetos en dos grupos. Generalmente, estos dos grupos consisten en ‘Verdadero’ y ‘Falso’. Por ejemplo, dado un determinado conjunto de atributos de salud, una tarea de clasificación binaria puede ser determinar si una persona tiene diabetes o no.
Por otro lado, en la clasificación multiclase, hay más de dos clases. Por ejemplo, dado un conjunto de atributos de la fruta, como su forma y color, una tarea de clasificación multiclase sería determinar el tipo de fruta.
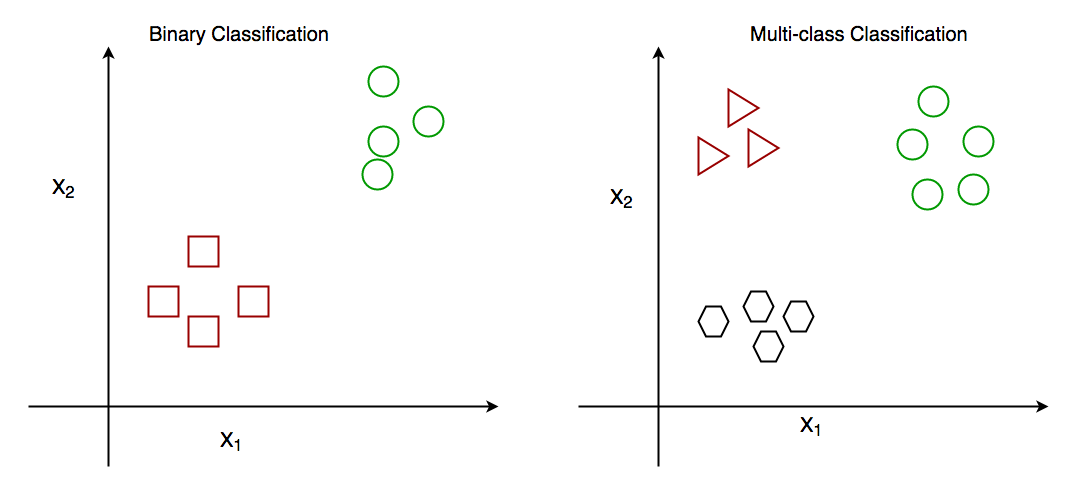
Entonces, ahora que tiene una idea de cómo funciona la clasificación binaria y multiclase, veamos cómo se usa el método heurístico uno contra el resto.
Método One-vs-Rest (OVR) :
muchos algoritmos de clasificación populares se diseñaron de forma nativa para problemas de clasificación binaria. Estos algoritmos incluyen:
- Regresión logística
- Máquinas de vectores de soporte (SVM)
- Modelos de perceptrón
y muchos más.
Por lo tanto, estos algoritmos de clasificación populares no se pueden usar directamente para problemas de clasificación de clases múltiples. Hay algunos métodos heurísticos disponibles que pueden dividir los problemas de clasificación de clases múltiples en muchos problemas de clasificación binaria diferentes. Para entender cómo funciona esto, consideremos un ejemplo : digamos, un problema de clasificación es clasificar varias frutas en tres tipos de frutas: plátano, naranja o manzana. Ahora bien, esto es claramente un problema de clasificación multiclase. Si desea utilizar un algoritmo de clasificación binaria como, por ejemplo, SVM. La forma en que el método One-vs-Rest se ocupará de esto se ilustra a continuación:
Dado que hay tres clases en el problema de clasificación, el método One-vs-Rest dividirá este problema en tres problemas de clasificación binaria:
- Problema 1: Plátano vs [Naranja, Manzana]
- Problema 2: Naranja vs [Plátano, Manzana]
- Problema 3: Apple vs [Plátano, Naranja]
Entonces, en lugar de resolverlo como (Banana vs Orange vs Apple), se resuelve usando tres problemas de clasificación binaria como se muestra arriba.
Una desventaja importante de este método es que se deben crear muchos modelos. Para un problema de varias clases con ‘n’ número de clases, se debe crear ‘n’ número de modelos, lo que puede ralentizar todo el proceso. Sin embargo, es muy útil con conjuntos de datos que tienen una pequeña cantidad de clases, donde queremos usar un modelo como SVM o Logistic Regression.
Implementación del método One-vs-Rest usando Python3
La biblioteca scikit-learn de Python ofrece un método OneVsRestClassifier(estimator, *, n_jobs=None) para implementar este método. Para esta implementación, usaremos el popular ‘Conjunto de datos de vino’, para determinar el origen de los vinos usando atributos químicos. Podemos dirigir este conjunto de datos usando scikit-learn. Para saber más sobre este conjunto de datos, puede usar el siguiente enlace: Wine Dataset
Usaremos una máquina de vectores de soporte, que es un algoritmo de clasificación binaria y la usaremos con la heurística One-vs-Rest para realizar una clasificación de clases múltiples.
Para evaluar nuestro modelo, veremos la puntuación de precisión del conjunto de prueba y el informe de clasificación del modelo.
from sklearn.datasets import load_wine
from sklearn.multiclass import OneVsRestClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import train_test_split
import warnings
'''
We are ignoring warnings because of a peculiar fact about this
dataset. The 3rd label, 'Label2' is never predicted and so the python
interpreter throws a warning. However, this can safely be ignored because
we are not concerned if a certain label is predicted or not
'''
warnings.filterwarnings('ignore')
# Loading the dataset
dataset = load_wine()
X = dataset.data
y = dataset.target
# Splitting the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.1, random_state = 13)
# Creating the SVM model
model = OneVsRestClassifier(SVC())
# Fitting the model with training data
model.fit(X_train, y_train)
# Making a prediction on the test set
prediction = model.predict(X_test)
# Evaluating the model
print(f"Test Set Accuracy : {accuracy_score(
y_test, prediction) * 100} %\n\n")
print(f"Classification Report : \n\n{classification_report(
y_test, prediction)}")
Producción:
Test Set Accuracy : 66.66666666666666 %
Classification Report :
precision recall f1-score support
0 0.62 1.00 0.77 5
1 0.70 0.88 0.78 8
micro avg 0.67 0.92 0.77 13
macro avg 0.66 0.94 0.77 13
weighted avg 0.67 0.92 0.77 13
Obtenemos una precisión del conjunto de prueba de aproximadamente 66.667%. Esto no es malo para este conjunto de datos. Este conjunto de datos es conocido por ser difícil de clasificar y la precisión de referencia es de 62,4 +- 0,4 %. Entonces, nuestro resultado es bastante bueno.
Conclusión:
ahora que sabe cómo usar el método heurístico One-vs-Rest para realizar una clasificación de clases múltiples con clasificadores binarios, puede intentar usarlo la próxima vez que tenga que realizar alguna tarea de clasificación de clases múltiples.
Publicación traducida automáticamente
Artículo escrito por alokesh985 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA