Hoy en día, se utilizan diferentes técnicas de Machine Learning para manejar diferentes tipos de datos. Uno de los tipos de datos más difíciles de manejar y el pronóstico son los datos secuenciales. Los datos secuenciales son diferentes de otros tipos de datos en el sentido de que, si bien se puede suponer que todas las características de un conjunto de datos típico son independientes del orden, esto no se puede suponer para un conjunto de datos secuenciales. Para manejar este tipo de datos, se concibió el concepto de Redes Neuronales Recurrentes . Se diferencia de otras Redes Neuronales Artificiales en su estructura. Mientras que otras redes «viajan» en una dirección lineal durante el proceso de avance o el proceso de propagación hacia atrás, la red recurrente sigue una relación de recurrencia en lugar de un paso hacia adelante y utiliza la propagación hacia atrás a través del tiempo para aprender.
La Red Neuronal Recurrente consta de múltiples unidades de función de activación fija, una para cada paso de tiempo. Cada unidad tiene un estado interno que se denomina estado oculto de la unidad. Este estado oculto significa el conocimiento pasado que la red tiene actualmente en un paso de tiempo dado. Este estado oculto se actualiza en cada paso de tiempo para indicar el cambio en el conocimiento de la red sobre el pasado. El estado oculto se actualiza utilizando la siguiente relación de recurrencia:-

[Tex]- The new hidden state[/Tex]
[Tex]- The old hidden state[/Tex]
[Tex]- The current input[/Tex]
[Tex]- The fixed function with trainable weights[/Tex]
Nota: Por lo general, para comprender los conceptos de una red neuronal recurrente, a menudo se ilustra en su forma desenrollada y esta norma se seguirá en esta publicación.
En cada paso de tiempo, el nuevo estado oculto se calcula usando la relación de recurrencia como se indicó anteriormente. Este nuevo estado oculto generado se utiliza para generar de hecho un nuevo estado oculto y así sucesivamente.
El flujo de trabajo básico de una red neuronal recurrente es el siguiente:
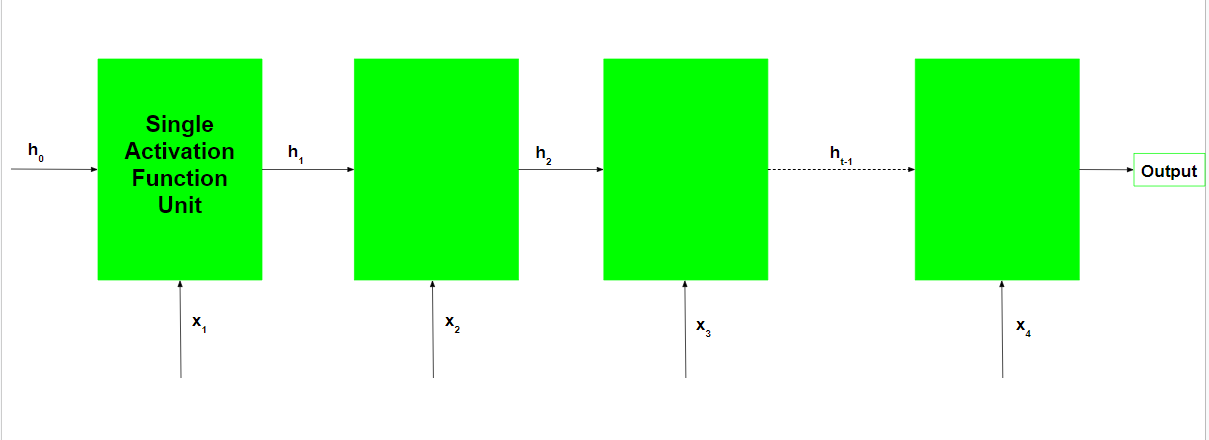
Tenga en cuenta que  es el estado oculto inicial de la red. Por lo general, es un vector de ceros, pero también puede tener otros valores. Un método consiste en codificar las suposiciones sobre los datos en el estado oculto inicial de la red. Por ejemplo, para un problema para determinar el tono de un discurso pronunciado por una persona de renombre, los tonos de los discursos anteriores de la persona pueden codificarse en el estado oculto inicial. Otra técnica es convertir el estado oculto inicial en un parámetro entrenable. Aunque estas técnicas agregan pequeños matices a la red, inicializar el vector de estado oculto a ceros suele ser una opción efectiva.
es el estado oculto inicial de la red. Por lo general, es un vector de ceros, pero también puede tener otros valores. Un método consiste en codificar las suposiciones sobre los datos en el estado oculto inicial de la red. Por ejemplo, para un problema para determinar el tono de un discurso pronunciado por una persona de renombre, los tonos de los discursos anteriores de la persona pueden codificarse en el estado oculto inicial. Otra técnica es convertir el estado oculto inicial en un parámetro entrenable. Aunque estas técnicas agregan pequeños matices a la red, inicializar el vector de estado oculto a ceros suele ser una opción efectiva.
Funcionamiento de cada Unidad Recurrente:
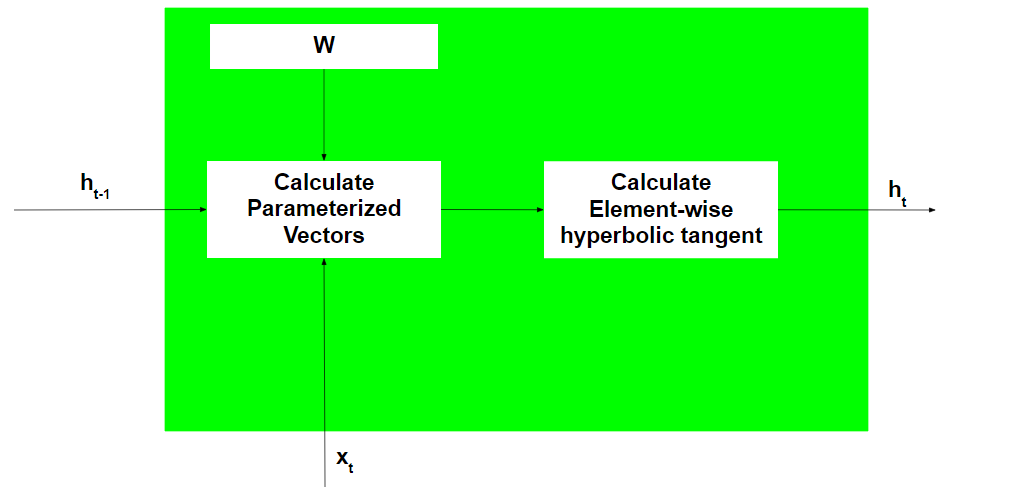
- Tome como entrada el vector de estado previamente oculto y el vector de entrada actual.
Tenga en cuenta que dado que el estado oculto y la entrada actual se tratan como vectores, cada elemento del vector se coloca en una dimensión diferente que es ortogonal a las otras dimensiones. Por lo tanto, cada elemento, cuando se multiplica por otro elemento, solo da un valor distinto de cero cuando los elementos involucrados son distintos de cero y los elementos están en la misma dimensión.
- Por elementos, multiplica el vector de estado oculto por los pesos de estado ocultos y, de manera similar, realiza la multiplicación por elementos del vector de entrada actual y los pesos de entrada actuales. Esto genera el vector de estado oculto parametrizado y el vector de entrada actual.
Tenga en cuenta que los pesos para diferentes vectores se almacenan en la array de peso entrenable.
- Realice la suma vectorial de los dos vectores parametrizados y luego calcule la tangente hiperbólica por elementos para generar el nuevo vector de estado oculto.
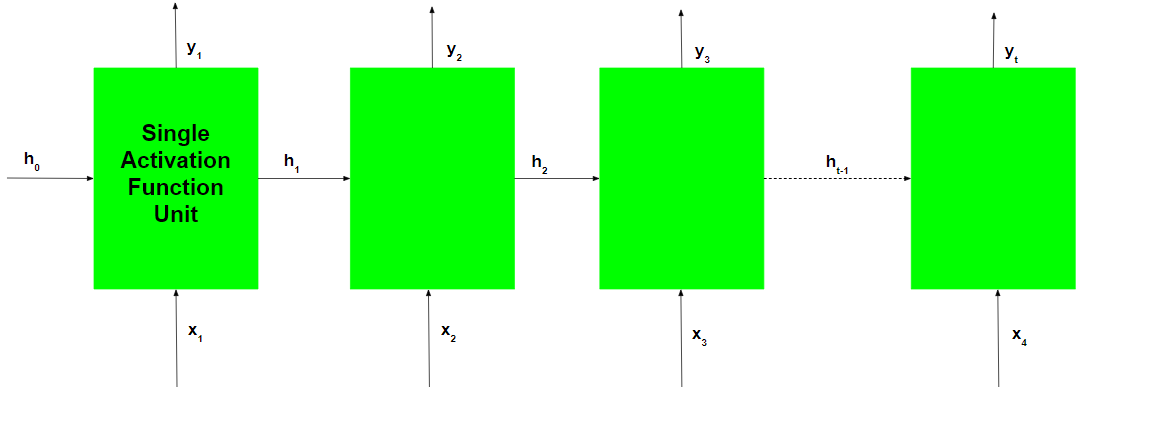
Durante el entrenamiento de la red recurrente, la red también genera una salida en cada paso de tiempo. Esta salida se usa para entrenar la red usando descenso de gradiente.
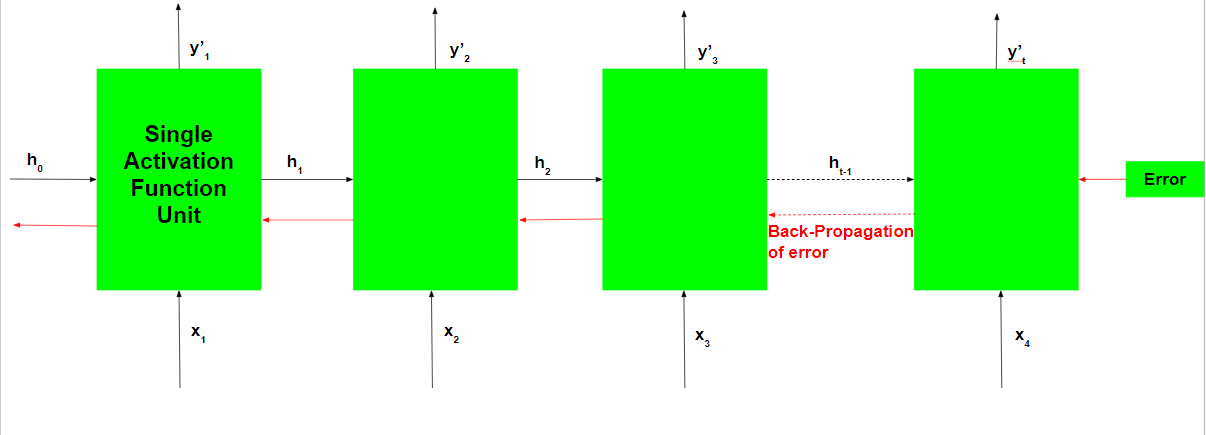
La retropropagación involucrada es similar a la utilizada en una red neuronal artificial típica con algunos cambios menores. Estos cambios se notan como: –
Sea la salida pronosticada de la red en cualquier paso de tiempo  y la salida real sea
y la salida real sea  . Entonces el error en cada paso de tiempo está dado por: –
. Entonces el error en cada paso de tiempo está dado por: –

El error total viene dado por la suma de los errores en todos los pasos de tiempo.


De manera similar, el valor  se puede calcular como la suma de los gradientes en cada paso de tiempo.
se puede calcular como la suma de los gradientes en cada paso de tiempo.

Usando la regla de la string del cálculo y usando el hecho de que la salida en un paso de tiempo t es una función del estado oculto actual de la unidad recurrente, surge la siguiente expresión:

Tenga en cuenta que la array de peso W utilizada en la expresión anterior es diferente para el vector de entrada y el vector de estado oculto y solo se usa de esta manera por conveniencia de notación.
Así surge la siguiente expresión:

Por lo tanto, la retropropagación a través del tiempo solo se diferencia de una retropropagación típica en el hecho de que los errores en cada paso de tiempo se suman para calcular el error total.
Aunque la red neuronal recurrente básica es bastante efectiva, puede sufrir un problema importante. Para redes profundas, el proceso de retropropagación puede generar los siguientes problemas:
- Gradientes que desaparecen: esto ocurre cuando los gradientes se vuelven muy pequeños y tienden a cero.
- Explosión de gradientes: esto ocurre cuando los gradientes se vuelven demasiado grandes debido a la retropropagación.
El problema de la Explosión de Gradientes puede resolverse usando un truco: Poniendo un umbral en los gradientes que se retroceden en el tiempo. Pero esta solución no se ve como una solución al problema y también puede reducir la eficiencia de la red. Para hacer frente a estos problemas, se desarrollaron dos variantes principales de redes neuronales recurrentes: redes de memoria a largo plazo y redes de unidades recurrentes cerradas .
Publicación traducida automáticamente
Artículo escrito por AlindGupta y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA