En el filtrado colaborativo, tendemos a encontrar usuarios similares y recomendar lo que les gusta a los usuarios similares. En este tipo de sistema de recomendación, no utilizamos las características del artículo para recomendarlo, sino que clasificamos a los usuarios en grupos de tipos similares y recomendamos a cada usuario según la preferencia de su grupo.
Medición de la similitud: un ejemplo simple del sistema de recomendación de películas nos ayudará a explicarlo: 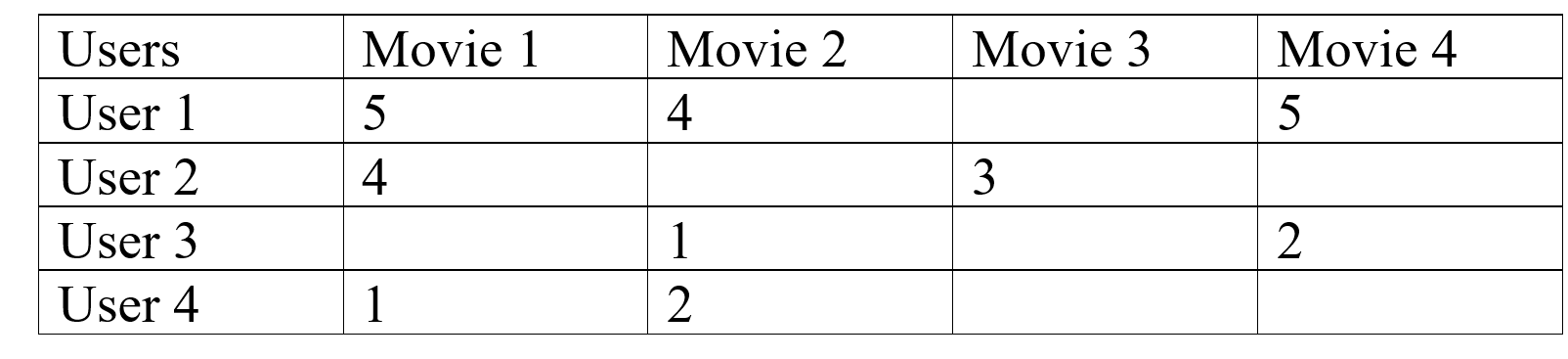 en este tipo de escenario, podemos ver que el usuario 1 y el usuario 2 otorgan calificaciones casi similares a la película, por lo que podemos concluir que la película 3 también va. para ser del agrado promedio del Usuario 1, pero la Película 4 será una buena recomendación para el Usuario 2, así también podemos ver que hay usuarios que tienen diferentes opciones, como el Usuario 1 y el Usuario 3, que son opuestos entre sí. Se puede ver que el Usuario 3 y el Usuario 4 tienen un interés común en la película, sobre esa base podemos decir que la Película 4 tampoco le gustará al Usuario 4. Este es el Filtrado Colaborativo, recomendamos a los usuarios los elementos que les gustan. por los usuarios de dominio de interés similar. Coseno Distancia:También podemos usar la distancia del coseno entre los usuarios para encontrar a los usuarios con intereses similares, un coseno más grande implica que hay un ángulo más pequeño entre dos usuarios, por lo tanto, tienen intereses similares. Podemos aplicar la distancia del coseno entre dos usuarios en la array de utilidad, y también podemos dar el valor cero a todas las columnas vacías para facilitar el cálculo, si obtenemos un coseno más pequeño, habrá una distancia mayor entre los usuarios y si el coseno es más grande que tenemos un pequeño ángulo entre los usuarios, y podemos recomendarles cosas similares.
en este tipo de escenario, podemos ver que el usuario 1 y el usuario 2 otorgan calificaciones casi similares a la película, por lo que podemos concluir que la película 3 también va. para ser del agrado promedio del Usuario 1, pero la Película 4 será una buena recomendación para el Usuario 2, así también podemos ver que hay usuarios que tienen diferentes opciones, como el Usuario 1 y el Usuario 3, que son opuestos entre sí. Se puede ver que el Usuario 3 y el Usuario 4 tienen un interés común en la película, sobre esa base podemos decir que la Película 4 tampoco le gustará al Usuario 4. Este es el Filtrado Colaborativo, recomendamos a los usuarios los elementos que les gustan. por los usuarios de dominio de interés similar. Coseno Distancia:También podemos usar la distancia del coseno entre los usuarios para encontrar a los usuarios con intereses similares, un coseno más grande implica que hay un ángulo más pequeño entre dos usuarios, por lo tanto, tienen intereses similares. Podemos aplicar la distancia del coseno entre dos usuarios en la array de utilidad, y también podemos dar el valor cero a todas las columnas vacías para facilitar el cálculo, si obtenemos un coseno más pequeño, habrá una distancia mayor entre los usuarios y si el coseno es más grande que tenemos un pequeño ángulo entre los usuarios, y podemos recomendarles cosas similares.
Redondeo de datos: en el filtrado colaborativo, redondeamos los datos para compararlos más fácilmente, ya que podemos asignar calificaciones inferiores a 3 como 0 y superiores como 1, esto nos ayudará a comparar datos más fácilmente, por ejemplo: 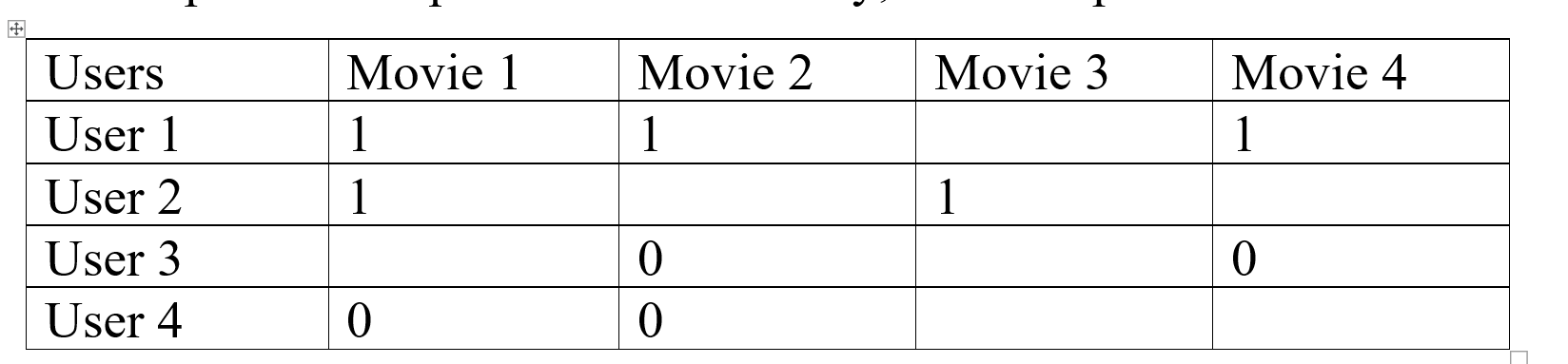 nuevamente tomamos el ejemplo anterior y aplicamos el proceso de redondeo, como puede ver qué tan legibles se han vuelto los datos después de realizar este proceso, podemos ver que el Usuario 1 y el Usuario 2 son más similares y el Usuario 3 y el Usuario 4 son más parecidos.
nuevamente tomamos el ejemplo anterior y aplicamos el proceso de redondeo, como puede ver qué tan legibles se han vuelto los datos después de realizar este proceso, podemos ver que el Usuario 1 y el Usuario 2 son más similares y el Usuario 3 y el Usuario 4 son más parecidos.
Calificación de normalización: en el proceso de normalización, tomamos la calificación promedio de un usuario y le restamos todas las calificaciones dadas, por lo que obtendremos valores positivos o negativos como calificación, que simplemente pueden clasificarse más en grupos similares. Al normalizar los datos, podemos crear grupos de usuarios que otorgan una calificación similar a elementos similares y luego podemos usar estos grupos para recomendar elementos a los usuarios.
Publicación traducida automáticamente
Artículo escrito por yugantshekhar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA