PyCaret es una biblioteca de aprendizaje automático de código abierto que es simple y fácil de usar. Le ayuda desde el comienzo de la preparación de datos hasta el final del análisis y la implementación del modelo. Además, es esencialmente un envoltorio de Python alrededor de varias bibliotecas y marcos de aprendizaje automático, como scikit-learn, spaCy, etc. También cuenta con el soporte de algoritmos complejos de aprendizaje automático que son tediosos de ajustar e implementar.
![]()
Entonces, ¿por qué usar Pycaret ? Bueno, hay muchas razones para esto, déjame explicarte algunas de ellas. El primer Pycaret es una biblioteca de código bajo que lo hace más productivo mientras resuelve un problema comercial. En segundo lugar, Pycaret puede realizar el preprocesamiento de datos y la ingeniería de características con una sola línea de código, cuando en realidad lleva mucho tiempo. Third Pycaret le permite comparar diferentes modelos de aprendizaje automático y ajustar su modelo muy fácilmente. Bueno, hay muchas otras ventajas, pero por ahora, quédese con ellas.
Instalación
pip install pycaret
si está utilizando Azure Notebooks o Google Colab
!pip install pycaret
En este artículo vamos a utilizar pycaret en el conjunto de datos de clasificación de Iris, puede descargar el conjunto de datos aquí https://archive.ics.uci.edu/ml/datasets/iris
Comencemos importando las bibliotecas requeridas.
Python3
# importing required libraries # for reading and manipulating data import numpy as np import pandas as pd
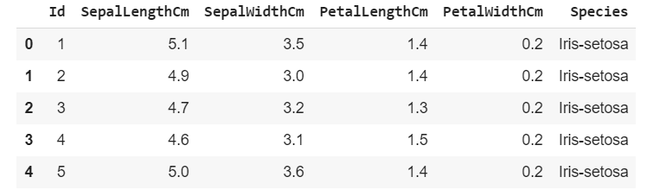
Leyendo el conjunto de datos usando la biblioteca pandas
Python3
# reading the data from csv file
iris_classification = pd.read_csv('Iris.csv')
# viewing top 5 rows of data
iris_classification.head(5)
Producción:
Comenzando con pycaret
Inicializar la configuración
Python3
#import classification module from pycaret from pycaret.classification import * #intialize the setup clf = setup(iris_classification, target = 'Species')
la configuración toma nuestros datos iris_classification y el valor objetivo (que debe predecirse) en nuestro caso, es Species
Producción:
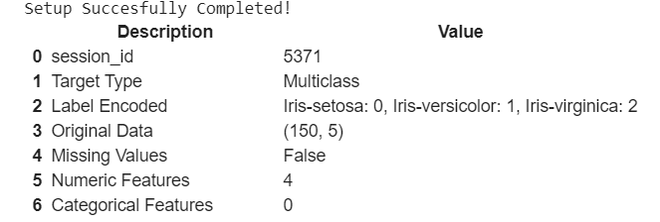
salida comprimida
Da una descripción básica de nuestro conjunto de datos, puede ver que codificó automáticamente las variables de destino en 0,1,2.
Ahora comparemos varios modelos de clasificación que Pycaret construyó para nosotros
Python3
# comparing different # classification models compare_models()
Producción:
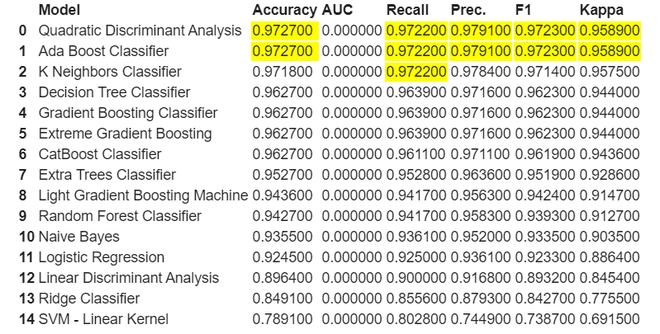
Como podemos ver aquí, resalta el valor más alto en cada columna respectiva. Aquí, para esta clasificación, tanto el análisis discriminante cuadrático como el clasificador Ada Boost están funcionando bien, tomemos QDA para nuestra creación y análisis de modelos adicionales.
Creación de modelo
Python3
# creating model qda
model = create_model('qda')
Producción:
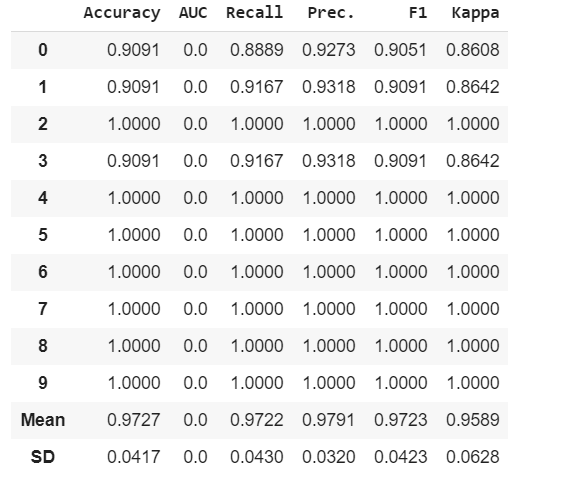
Muestra varias métricas utilizadas para evaluar el modelo en diferentes pliegues.
Ajustemos los hiperparámetros del modelo
Python3
# tuning model hyperparameters
tuned_model = tune_model('qda')
Producción:
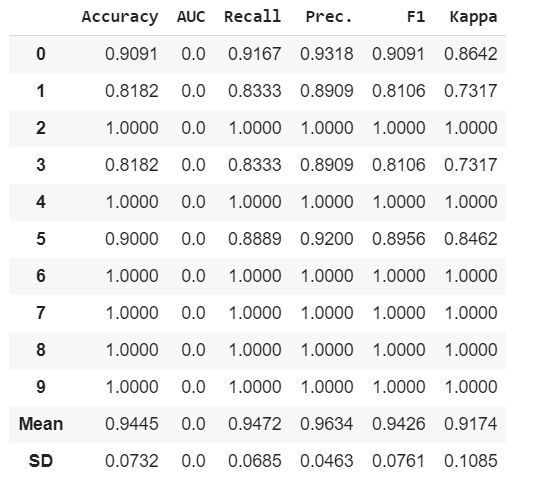
Podemos ver aquí que algunos Recall, Precision, F1 y Kappa han aumentado debido al ajuste fino de nuestro modelo.
Ahora hagamos un análisis del modelo.
Python3
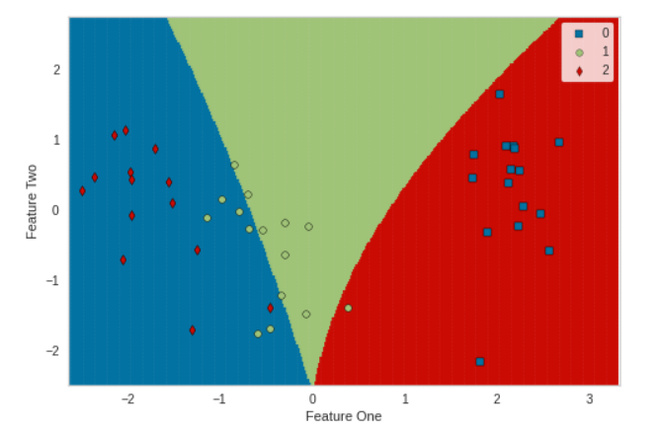
# plotting boundaries between different # labels plot_model(tuned_model, plot = 'boundary')
Producción:
Python3
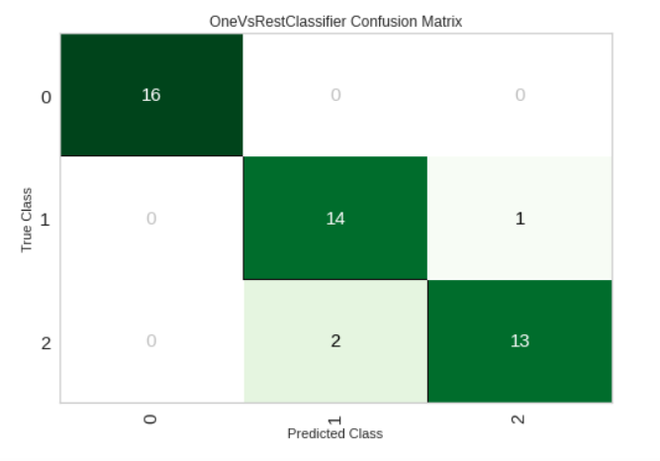
# plotting confusionmatrix for predicted labels plot_model(tuned_model, plot = 'confusion_matrix')
Producción:
Python3
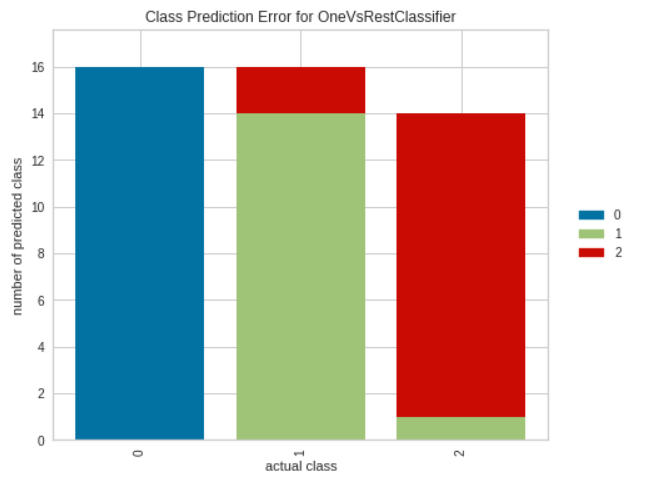
# plotting number of correctly # classified and misclassifed labels plot_model(tuned_model, plot = 'error')
Producción:
Python3
# plotting classification report plot_model(tuned_model, plot = 'class_report')
Producción:
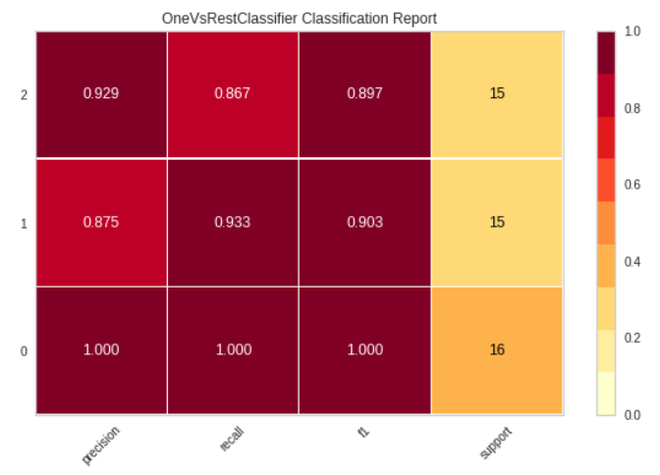
Finalizar el modelo
Python3
# finalizing the tuned_model finalize_model(tuned_model)
Producción:

Guardando el modelo
Python3
# saving the model save_model(tuned_model, 'qda1')
Producción:

Publicación traducida automáticamente
Artículo escrito por Koushik222 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA