En este artículo, vamos a ver el funcionamiento de las redes neuronales de convolución con TensorFlow, una poderosa biblioteca de aprendizaje automático para crear redes neuronales.
Ahora a saber, cómo una red neuronal de convolución permite dividirla en partes. las 3 partes más importantes de esta red neuronal de convolución son,
- Circunvolución
- puesta en común
- Aplastamiento
Estas 3 acciones son las cosas muy especiales que hacen que las redes neuronales de convolución funcionen mucho mejor en comparación con otras redes neuronales artificiales. Ahora, vamos a discutirlos en detalle,
Circunvolución
Piense en una imagen de 28*28 como un conjunto de datos MINST que es básicamente un reconocimiento de dígitos escritos a mano. Para construir un modelo que reconozca los dígitos con una red neuronal artificial simple, alimentaremos el valor de cada píxel individualmente como una entrada de característica dentro del modelo y eso es 784 Nodes de entrada y tendrá un par de capas ocultas y el modelo puede funcionar bien pero el problema aquí es que el modelo no podrá reconocer las características importantes de la imagen. Leerá ciegamente los píxeles y escupirá la salida.
Pero una imagen que es tan pequeña en tamaño como este conjunto de datos MINST (imagen de 28 por 28) que le dará al modelo 784 entradas, cada Node debe dividirse en capas ocultas y habrá mucho peso asignado y obviamente habrá una gran cantidad de calculo Ahora piensa en una imagen del tamaño de 1920 por 1080 en Ultra HD, si seguimos el mismo método, prácticamente habrá 2 millones de Nodes de entrada e incluso tomamos una capa oculta de 64 Nodes que no es suficiente para este gran entrada tendremos 130 millones de pesos y habrá una cantidad increíble de cálculos y su máquina ni siquiera puede pensar en administrar tantos cálculos a la vez.
Entonces, para esto, primero debemos encontrar las características importantes de una imagen,
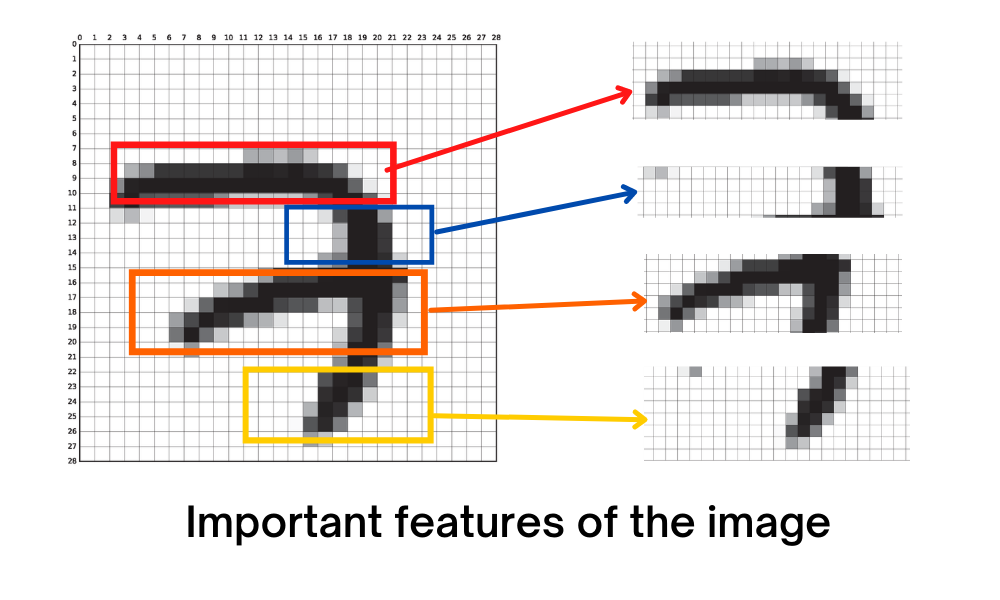
Al encontrar estas características importantes, podemos dejar atrás algunos píxeles no deseados sin comprometer la calidad de salida. Con este método, podemos darle al modelo un nivel humano de reconocimiento de imágenes en el mundo real. Así que para esto, tenemos convolución.
La convolución es el tema más confuso y difícil en Internet, pero simplemente se trata de buscar en la imagen deslizando un filtro (núcleo) a lo largo de la imagen para encontrar diferentes características de la imagen. Los núcleos son solo arrays 2D con diferentes pesos en ellos. Básicamente, este núcleo pasará por encima de la imagen reemplazando los valores de píxeles con el promedio de la suma de su peso en la parte respectiva de la imagen. Estos núcleos son una forma increíble de encontrar las características más importantes de la imagen.
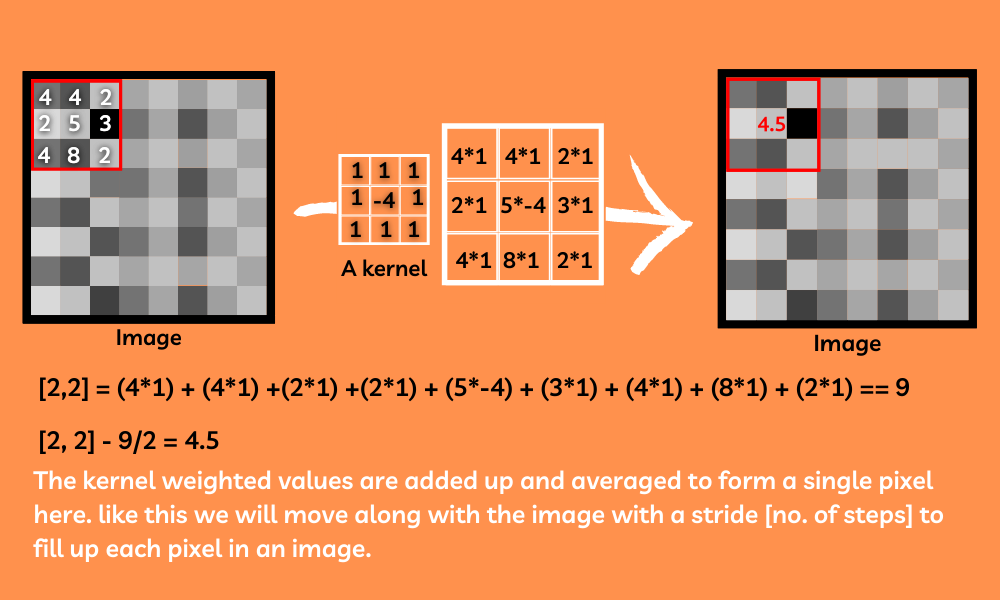
Aplicaremos una serie de kernels generados aleatoriamente a la imagen para encontrar muchas características diferentes de las imágenes.
Entonces, después de aplicar esta capa de convolución a nuestro modelo, necesitamos agrupar las características.
puesta en común
Ahora que ha encontrado las características importantes de la imagen, aún así, la cantidad de entrada es muy grande y nuestra máquina no podría manejar esta cantidad de entradas. Así que aquí es donde viene la agrupación.
La agrupación es simplemente reducir el tamaño de la imagen sin perder las características que encontramos con la convolución. Por ejemplo, un método MaxPooling tomará la forma de una array y devolverá el valor más grande en ese rango. Al hacer esto, podemos comprimir la imagen sin perder las características importantes de esta imagen.
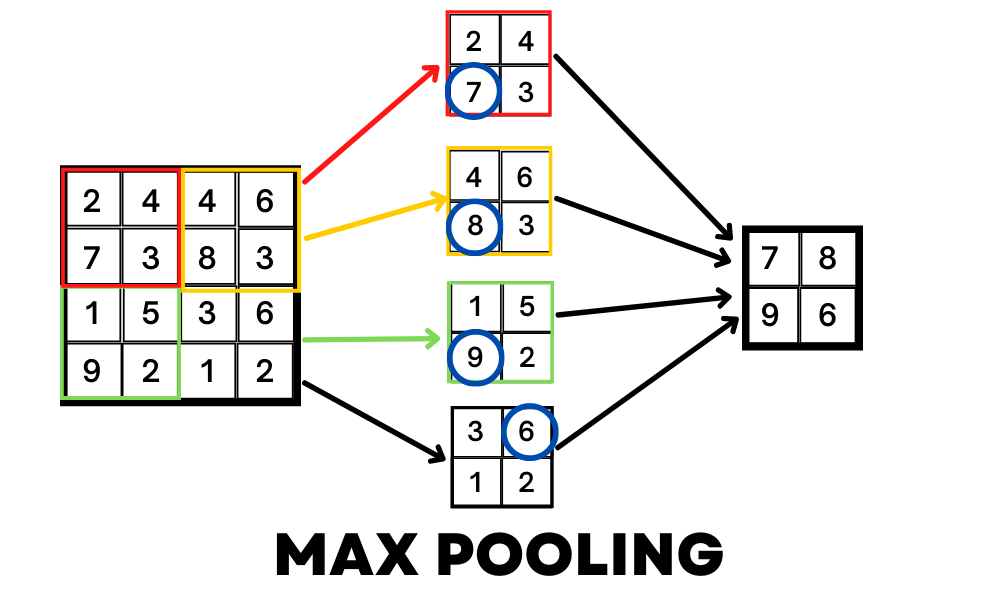
Aplastamiento
El aplanamiento no es más que convertir una array 3D o 2D en una entrada 1D para el modelo; este será nuestro último paso para procesar la imagen y conectar las entradas a una capa densa completamente conectada para una mayor clasificación.
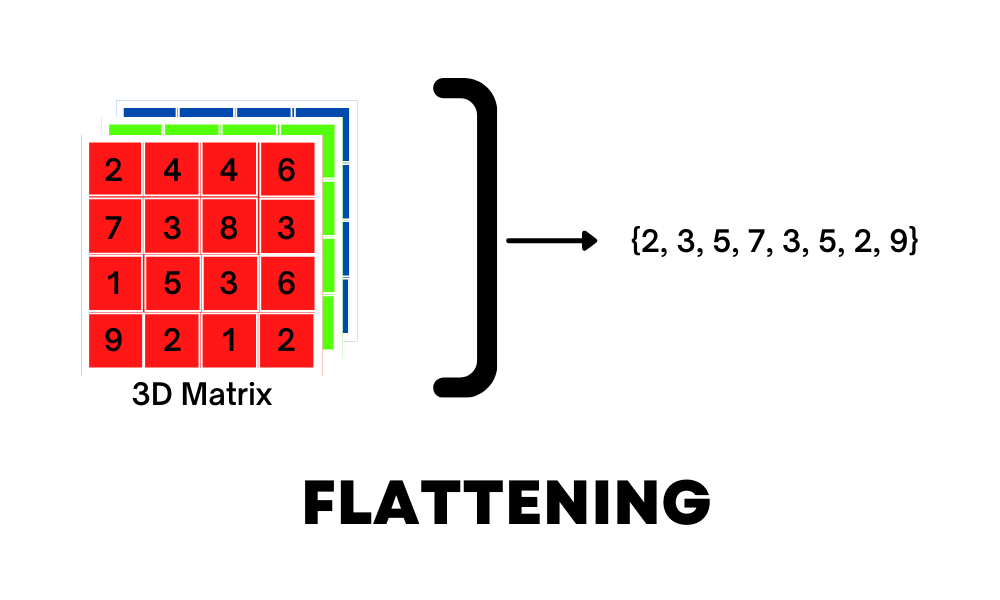
En resumen, la forma en que funciona una red neuronal de convolución es:
- Aplicar convolución para encontrar diferentes características importantes dentro de la imagen
sintaxis: model.add(layers.Conv2D(nº de kernels, tamaño del kernel, activación=’relu’, input_shape)
- Aplicar pooling para comprimir la imagen sin perder sus características
sintaxis: model.add(layers.MaxPooling2D((tamaño del kernel)))
- Aplanarlo a una entrada unidimensional desde 3D [imágenes en color] o 2D [imágenes en blanco y negro] para pasar al modelo
sintaxis: model.add(layers.Flatten()
- Entrada totalmente conectada y capas ocultas para jugar con pesos y sesgos y funciones de activación y optimizadores.
- ¡Vaya! Has construido el mejor clasificador de imágenes.
Un modelo típico de CNN se verá así:
Python
# Importing the library import tensorflow as tf from tensorflow import keras # Designing the model model = tf.keras.models.Sequential([ # Convolutional layer1 tf.keras.layers.Conv2D( 32, (3, 3), activation='relu', input_shape=(32, 32, 3)) tf.keras.layers.MaxPooling2D((2, 2)) # Pooling # COnvolutional layer2 tf.keras.layers.Conv2D(64, (3, 3), activation='relu') tf.keras.layers.MaxPooling2D((2, 2)) # Pooling # COnvolutional layer3 tf.keras.layers.Conv2D(64, (3, 3), activation='relu') tf.keras.layers.MaxPooling2D((2, 2)) # Pooling # Flattening the input tf.keras.layers.Flatten(), # Fully connected layers tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(256, activation='relu'), tf.keras.layers.Dense(10, activation='softmax') ]) # Compiling the model model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy( from_logits=True), metrics=['accuracy']) # FItting the data to a model history = model.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))
Producción:
Publicación traducida automáticamente
Artículo escrito por sanjaysdev0901 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA