Generar una leyenda para una imagen dada es un problema desafiante en el dominio del aprendizaje profundo. En este artículo, utilizaremos diferentes técnicas de visión artificial y PNL para reconocer el contexto de una imagen y describirlas en un lenguaje natural como el inglés. Construiremos un modelo de trabajo del generador de leyendas de imágenes utilizando unidades CNN (redes neuronales convolucionales) y LSTM (memoria a largo plazo).
Para entrenar nuestro modelo, estoy usando el conjunto de datos Flickr8K . Consta de 8000 imágenes únicas y cada imagen se asignará a cinco oraciones diferentes que describirán la imagen.
Paso 1: importa las bibliotecas requeridas
# linear algebra import numpy as np # data processing, CSV file I / O (e.g. pd.read_csv) import pandas as pd import os import tensorflow as tf from keras.preprocessing.sequence import pad_sequences from keras.preprocessing.text import Tokenizer from keras.models import Model from keras.layers import Flatten, Dense, LSTM, Dropout, Embedding, Activation from keras.layers import concatenate, BatchNormalization, Input from keras.layers.merge import add from keras.utils import to_categorical, plot_model from keras.applications.inception_v3 import InceptionV3, preprocess_input import matplotlib.pyplot as plt # for plotting data import cv2
Paso 2: Cargar las descripciones
El formato de nuestro archivo es imagen y título separados por un salto de línea (“\n”) es decir, consta del nombre de la imagen seguido de un espacio y la descripción de la imagen en formato CSV. Aquí necesitamos asignar la imagen a sus descripciones almacenándolas en un diccionario.
def load_description(text):
mapping = dict()
for line in text.split("\n"):
token = line.split("\t")
if len(line) < 2: # remove short descriptions
continue
img_id = token[0].split('.')[0] # name of the image
img_des = token[1] # description of the image
if img_id not in mapping:
mapping[img_id] = list()
mapping[img_id].append(img_des)
return mapping
token_path = '/kaggle / input / flickr8k / flickr_data / Flickr_Data / Flickr_TextData / Flickr8k.token.txt'
text = open(token_path, 'r', encoding = 'utf-8').read()
descriptions = load_description(text)
print(descriptions['1000268201_693b08cb0e'])
Producción:
['A child in a pink dress is climbing up a set of stairs in an entry way .', 'A girl going into a wooden building .', 'A little girl climbing into a wooden playhouse .', 'A little girl climbing the stairs to her playhouse .', 'A little girl in a pink dress going into a wooden cabin .']
Paso 3: Limpiar el texto
Uno de los pasos principales en NLP es eliminar el ruido para que la máquina pueda detectar fácilmente los patrones en el texto. El ruido estará presente en forma de caracteres especiales como hashtags, puntuación y números. Todos los cuales son difíciles de entender para las computadoras si están presentes en el texto. Por lo tanto, debemos eliminarlos para obtener mejores resultados. Además, también puede eliminar palabras vacías y realizar Stemming y Lematization mediante el uso de la biblioteca NLTK.
def clean_description(desc):
for key, des_list in desc.items():
for i in range(len(des_list)):
caption = des_list[i]
caption = [ch for ch in caption if ch not in string.punctuation]
caption = ''.join(caption)
caption = caption.split(' ')
caption = [word.lower() for word in caption if len(word)>1 and word.isalpha()]
caption = ' '.join(caption)
des_list[i] = caption
clean_description(descriptions)
descriptions['1000268201_693b08cb0e']
Paso 4: generar el vocabulario
El vocabulario es un conjunto de palabras únicas que están presentes en nuestro corpus de texto. Al procesar texto sin procesar para NLP, todo se hace en torno al vocabulario.
def to_vocab(desc): words = set() for key in desc.keys(): for line in desc[key]: words.update(line.split()) return words vocab = to_vocab(descriptions)
Paso 5: Carga las imágenes
Aquí necesitamos mapear las imágenes en el conjunto de entrenamiento a sus correspondientes descripciones que están presentes en nuestra variable descripciones. Cree una lista de nombres de todas las imágenes de entrenamiento y luego cree un diccionario vacío y asigne las imágenes a sus descripciones usando el nombre de la imagen como clave y una lista de descripciones como su valor. mientras mapea las descripciones, agregue palabras únicas al principio y al final para identificar el principio y el final de la oración.
import glob
images = '/kaggle / input / flickr8k / flickr_data / Flickr_Data / Images/'
# Create a list of all image names in the directory
img = glob.glob(images + '*.jpg')
train_path = '/kaggle / input / flickr8k / flickr_data / Flickr_Data / Flickr_TextData / Flickr_8k.trainImages.txt'
train_images = open(train_path, 'r', encoding = 'utf-8').read().split("\n")
train_img = [] # list of all images in training set
for im in img:
if(im[len(images):] in train_images):
train_img.append(im)
# load descriptions of training set in a dictionary. Name of the image will act as ey
def load_clean_descriptions(des, dataset):
dataset_des = dict()
for key, des_list in des.items():
if key+'.jpg' in dataset:
if key not in dataset_des:
dataset_des[key] = list()
for line in des_list:
desc = 'startseq ' + line + ' endseq'
dataset_des[key].append(desc)
return dataset_des
train_descriptions = load_clean_descriptions(descriptions, train_images)
print(train_descriptions['1000268201_693b08cb0e'])
Producción:
['startseq child in pink dress is climbing up set of stairs in an entry way endseq', 'startseq girl going into wooden building endseq', 'startseq little girl climbing into wooden playhouse endseq', 'startseq little girl climbing the stairs to her playhouse endseq', 'startseq little girl in pink dress going into wooden cabin endseq']
Paso 6: extraiga el vector de características de todas las imágenes
Ahora daremos una imagen como entrada a nuestro modelo, pero a diferencia de los humanos, las máquinas no pueden entender la imagen al verlas. Entonces necesitamos convertir la imagen en una codificación para que la máquina pueda entender los patrones en ella. Para esta tarea, estoy usando el aprendizaje por transferencia, es decir, usamos un modelo previamente entrenado que ya ha sido entrenado en grandes conjuntos de datos y extraemos las características de estos modelos y las usamos para nuestro trabajo. Aquí estoy usando el modelo InceptionV3 que se entrenó en el conjunto de datos de Imagenet que tenía 1000 clases diferentes para clasificar. Podemos importar directamente este modelo desde el módulo Keras.applications.
Necesitamos eliminar la última capa de clasificación para obtener el vector de características dimensionales (2048, ) del modelo InceptionV3.
from keras.preprocessing.image import load_img, img_to_array
def preprocess_img(img_path):
# inception v3 excepts img in 299 * 299 * 3
img = load_img(img_path, target_size = (299, 299))
x = img_to_array(img)
# Add one more dimension
x = np.expand_dims(x, axis = 0)
x = preprocess_input(x)
return x
def encode(image):
image = preprocess_img(image)
vec = model.predict(image)
vec = np.reshape(vec, (vec.shape[1]))
return vec
base_model = InceptionV3(weights = 'imagenet')
model = Model(base_model.input, base_model.layers[-2].output)
# run the encode function on all train images and store the feature vectors in a list
encoding_train = {}
for img in train_img:
encoding_train[img[len(images):]] = encode(img)
Paso 7: tokenizar el vocabulario
En este paso, necesitamos tokenizar todas las palabras presentes en nuestro vocabulario. Alternativamente, podemos usar tokenizer en Keras para realizar esta tarea.
# list of all training captions
all_train_captions = []
for key, val in train_descriptions.items():
for caption in val:
all_train_captions.append(caption)
# consider only words which occur atleast 10 times
vocabulary = vocab
threshold = 10 # you can change this value according to your need
word_counts = {}
for cap in all_train_captions:
for word in cap.split(' '):
word_counts[word] = word_counts.get(word, 0) + 1
vocab = [word for word in word_counts if word_counts[word] >= threshold]
# word mapping to integers
ixtoword = {}
wordtoix = {}
ix = 1
for word in vocab:
wordtoix[word] = ix
ixtoword[ix] = word
ix += 1
# find the maximum length of a description in a dataset
max_length = max(len(des.split()) for des in all_train_captions)
max_length
Paso 8: incrustaciones de vectores de guantes
GloVe significa vectores globales para la representación de palabras. Es un algoritmo de aprendizaje no supervisado desarrollado por Stanford para generar incrustaciones de palabras mediante la agregación de una array global de coocurrencia palabra-palabra a partir de un corpus. Además, tenemos 8000 imágenes y cada imagen tiene 5 subtítulos asociados. Significa que tenemos 30000 ejemplos para entrenar nuestro modelo. Como hay más ejemplos, también puede usar el generador de datos para alimentar la entrada en forma de lotes a nuestro modelo en lugar de dar todo al mismo tiempo. Para simplificar, no estoy usando esto aquí.
Además, vamos a utilizar una array de incrustación para almacenar las relaciones entre las palabras de nuestro vocabulario. Una array de incrustación es un mapeo lineal del espacio original a un espacio de valor real donde las entidades tendrán relaciones significativas.
X1, X2, y = list(), list(), list()
for key, des_list in train_descriptions.items():
pic = train_features[key + '.jpg']
for cap in des_list:
seq = [wordtoix[word] for word in cap.split(' ') if word in wordtoix]
for i in range(1, len(seq)):
in_seq, out_seq = seq[:i], seq[i]
in_seq = pad_sequences([in_seq], maxlen = max_length)[0]
out_seq = to_categorical([out_seq], num_classes = vocab_size)[0]
# store
X1.append(pic)
X2.append(in_seq)
y.append(out_seq)
X2 = np.array(X2)
X1 = np.array(X1)
y = np.array(y)
# load glove vectors for embedding layer
embeddings_index = {}
golve_path ='/kaggle / input / glove-global-vectors-for-word-representation / glove.6B.200d.txt'
glove = open(golve_path, 'r', encoding = 'utf-8').read()
for line in glove.split("\n"):
values = line.split(" ")
word = values[0]
indices = np.asarray(values[1: ], dtype = 'float32')
embeddings_index[word] = indices
emb_dim = 200
emb_matrix = np.zeros((vocab_size, emb_dim))
for word, i in wordtoix.items():
emb_vec = embeddings_index.get(word)
if emb_vec is not None:
emb_matrix[i] = emb_vec
emb_matrix.shape
Paso 9: Definir el modelo
Para definir la estructura de nuestro modelo, utilizaremos el modelo Keras de la API funcional. Tiene tres pasos principales:
- Procesando la secuencia del texto
- Extrayendo el vector de características de la imagen
- Decodificación de la salida mediante la concatenación de las dos capas anteriores
# define the model ip1 = Input(shape = (2048, )) fe1 = Dropout(0.2)(ip1) fe2 = Dense(256, activation = 'relu')(fe1) ip2 = Input(shape = (max_length, )) se1 = Embedding(vocab_size, emb_dim, mask_zero = True)(ip2) se2 = Dropout(0.2)(se1) se3 = LSTM(256)(se2) decoder1 = add([fe2, se3]) decoder2 = Dense(256, activation = 'relu')(decoder1) outputs = Dense(vocab_size, activation = 'softmax')(decoder2) model = Model(inputs = [ip1, ip2], outputs = outputs)
Producción:
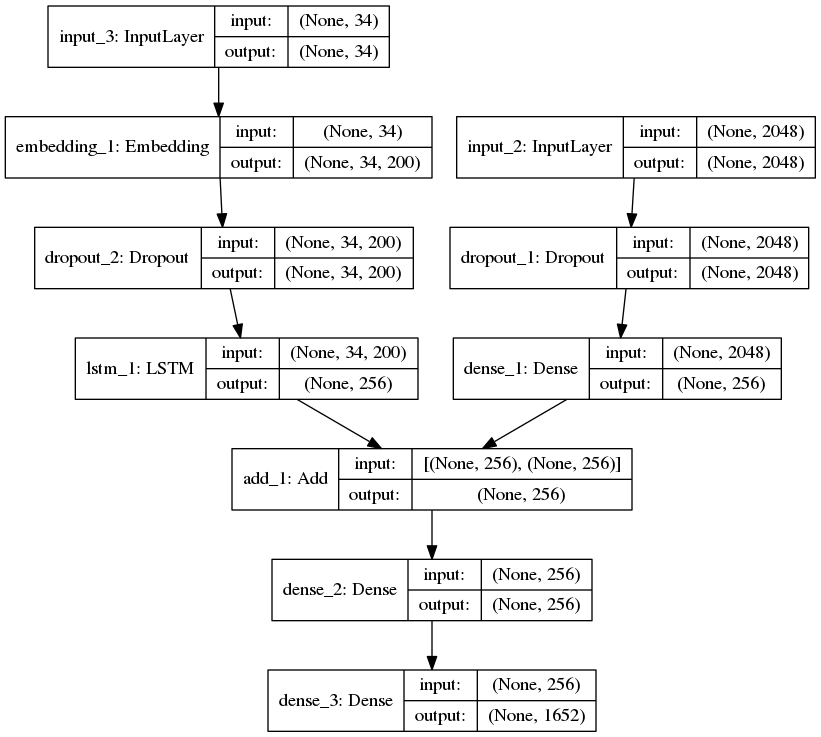
Modelo de aprendizaje profundo del generador de subtítulos
Paso 10: Entrenamiento del modelo
Para entrenar nuestro modelo, estoy usando el optimizador de Adam y la función de pérdida como entropía cruzada categórica. Estoy entrenando el modelo para 50 épocas que serán suficientes para predecir la salida. En caso de que tenga más poder computacional (número de GPU), puede entrenarlo disminuyendo el tamaño del lote y aumentando el número de épocas.
model.layers[2].set_weights([emb_matrix]) model.layers[2].trainable = False model.compile(loss = 'categorical_crossentropy', optimizer = 'adam') model.fit([X1, X2], y, epochs = 50, batch_size = 256) # you can increase the number of epochs for better results
Producción:
Epoch 1/1 292328/292328 [==============================] - 55s 189us/step - loss: 3.8895 Epoch 1/1 292328/292328 [==============================] - 55s 187us/step - loss: 3.1549 Epoch 1/1 292328/292328 [==============================] - 54s 186us/step - loss: 2.9185 Epoch 1/1 292328/292328 [==============================] - 54s 186us/step - loss: 2.7652 Epoch 1/1 292328/292328 [=================>.........] - ETA: 15s - loss: 2.6496
Paso 11: Predicción de la salida
def greedy_search(pic): start = 'startseq' for i in range(max_length): seq = [wordtoix[word] for word in start.split() if word in wordtoix] seq = pad_sequences([seq], maxlen = max_length) yhat = model.predict([pic, seq]) yhat = np.argmax(yhat) word = ixtoword[yhat] start += ' ' + word if word == 'endseq': break final = start.split() final = final[1:-1] final = ' '.join(final) return final
PRODUCCIÓN:

Salida prevista: cuatro niñas están sentadas en un piso de madera

Resultado previsto: el perro negro corre por la hierba

Resultado previsto: el hombre está patinando en rampa
Publicación traducida automáticamente
Artículo escrito por dark_coder88 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA