Se utiliza una gráfica de desviación estándar para verificar si hay una desviación entre diferentes grupos de datos. Estos grupos se pueden generar manualmente o se pueden decidir en función de alguna propiedad del conjunto de datos.
Los gráficos de desviación estándar se pueden formar de:
- Eje vertical: Grupo Desviación estándar
- Eje Horizontal: Identificador de Grupo/ Etiqueta de los grupos.
Se traza una línea recta de referencia entre la desviación estándar general.
La gráfica de desviación estándar se usa para responder las siguientes preguntas:
- ¿Hay algún cambio en la variación?
- ¿Cuál es la magnitud del cambio en la variación?
- ¿Hay algún patrón distinto en el cambio de la variación?
Generalmente se usa una gráfica de desviación estándar para medir la escala, la misma medida de escala también se puede usar para encontrar con gráfica absoluta media y gráfica de desviación promedio. Estos gráficos también proporcionan una mayor precisión en términos de identificación de valores atípicos.
Usos de la gráfica de desviación estándar
- Generalmente se usa una gráfica de desviación estándar para medir la escala, la misma medida de escala también se puede encontrar con la gráfica absoluta media y la gráfica de desviación promedio. Estos gráficos también proporcionan una mayor precisión en términos de identificación de valores atípicos.
- Una suposición común en muchos análisis, como el análisis de 1 factor, es que la varianza es la misma para diferentes niveles de variables factoriales. Se puede usar una gráfica de desviación estándar para verificar eso.
- También podemos verificar los supuestos de varianza constante de los datos univariados dividiendo los datos en particiones de igual tamaño y trazando la varianza para cada una de las particiones.
Implementación
- En esta implementación, usamos el conjunto de datos meteorológicos de Delhi de Kaggle. El enlace al conjunto de datos se puede encontrar aquí .
Python3
# import necessary modules
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
sns.set_style('darkgrid')
%matplotlib inline
sns.mpl.rcParams['figure.figsize'] = (10.0, 8.0)
# read weather dataset
df =pd.read_csv('weather.csv')
# remove the hours and minutes from time to keep date only
df['datetime_utc'] = pd.to_datetime(df['datetime_utc']).dt.date
df.head()
# group by dataframe into months, calculate standard deviation,
# and sort them in chronological order
month_Df =df.groupby(df['datetime_utc'].dt.strftime('%B'))[" _tempm"].std()
new_order = ['January', 'February', 'March', 'April', 'May', 'June', 'July',
'August', 'September', 'October', 'November', 'December']
month_Df=month_Df.reindex(new_order)
month_Df
# plot scatterplot of the standard deviation (standard deviation plot)
graph =sns.scatterplot(y= month_Df.values, x= month_Df.index)
graph.axhline(df[" _tempm"].std(), color='red')
plt.show()
datetime_utc _conds _dewptm _fog _hail _heatindexm _hum _precipm _pressurem _rain _snow _tempm _thunder _tornado _vism _wdird _wdire _wgustm _windchillm _wspdm 0 1996-11-01 Smoke 9.0 0 0 NaN 27.0 NaN 1010.0 0 0 30.0 0 0 5.0 280.0 West NaN NaN 7.4 1 1996-11-01 Smoke 10.0 0 0 NaN 32.0 NaN -9999.0 0 0 28.0 0 0 NaN 0.0 North NaN NaN NaN 2 1996-11-01 Smoke 11.0 0 0 NaN 44.0 NaN -9999.0 0 0 24.0 0 0 NaN 0.0 North NaN NaN NaN 3 1996-11-01 Smoke 10.0 0 0 NaN 41.0 NaN 1010.0 0 0 24.0 0 0 2.0 0.0 North NaN NaN NaN 4 1996-11-01 Smoke 11.0 0 0 NaN 47.0 NaN 1011.0 0 0 23.0 0 0 1.2 0.0 North NaN NaN 0.0
datetime_utc April 5.817769 August 2.928722 December 5.288852 February 5.404892 January 4.646874 July 3.394908 June 4.520245 March 5.905230 May 5.441476 November 5.556417 October 4.930381 September 3.437260 Name: _tempm, dtype: float64
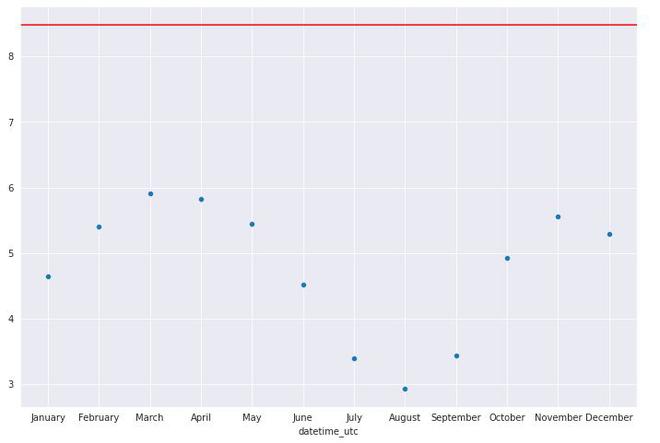
Gráfica de desviación estándar