Un gráfico de retraso es un tipo especial de gráfico de dispersión en el que el eje X representa el conjunto de datos con algunas unidades de tiempo por delante o por detrás en comparación con el eje Y. La diferencia entre estas unidades de tiempo se denomina lag o retardada y se representa por k .
El gráfico de retardo contiene los siguientes ejes:
- Eje vertical : Y i para todo i
- Eje horizontal : Y i-k para todo i, donde k es el valor de retraso
El gráfico de retardo se utiliza para responder a las siguientes preguntas:
- Distribución del modelo : la distribución del modelo aquí significa decidir cuál es la forma de los datos sobre la base del gráfico de retraso. A continuación se muestran algunos ejemplos de diagramas de retardo y su diagrama original:
- Si el gráfico de retardo es lineal, entonces la estructura subyacente es del modelo autorregresivo.
- Si el diagrama de retardo tiene forma elíptica, entonces la estructura subyacente representa una función periódica continua como seno, coseno, etc.
- Valores atípicos : los valores atípicos son un conjunto de puntos de datos que representan los valores extremos en la distribución
- Aleatoriedad en los datos : el diagrama de retraso también es útil para verificar si el conjunto de datos dado es aleatorio o no. Si hay aleatoriedad en los datos, se reflejará en el gráfico de retraso, si no hay un patrón en el gráfico de retraso.
- Estacionalidad: si hay estacionalidad en el gráfico, se obtendrá un gráfico de retraso periódico.
- Autocorrelación : si el gráfico de retardo da un gráfico lineal, significa que la autocorrelación está presente en los datos, ya sea que haya una autocorrelación positiva o negativa que depende de la pendiente de la línea del conjunto de datos. Si se concentran más datos en la diagonal en el gráfico de retraso, significa que hay una fuerte autocorrelación.
Implementación
- En esta implementación, seremos bibliotecas NumPy y SciPy, estas están preinstaladas en Colab pero se pueden instalar en un entorno local usando pip install . Usaremos datos de precios de acciones de GOOGLE y datos de Flicker para esta implementación.
Python3
# Import Libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats as sc
# Sine graph and lag plot
time= np.arange(0, 10, 0.1);
amplitude=np.sin(time)
fig, ax = plt.subplots(1, 2, figsize=(12, 7))
ax[0].plot(time, amplitude)
ax[0].set_xlabel('Time')
ax[0].set_ylabel('Amplitude')
ax[0].axhline(y=0, color='k')
amplitude_series = pd.Series(amplitude)
pd.plotting.lag_plot(amplitude_series, lag= 3, ax =ax[1])
plt.show()
# Random and Lag Plot
sample_size=1000
fig, ax = plt.subplots(1, 2, figsize=(12, 7))
random_series= pd.Series(np.random.normal(size=sample_size))
random=random_series.reset_index(inplace=True)
ax[0].plot(random['index'],random[0])
pd.plotting.lag_plot(random[0],lag=1)
plt.show()
# Google Stock and Lag Plot (Strong Autocorrelation)
google_stock_data = pd.read_csv('GOOG.csv')
google_stock_data.reset_index(inplace=True)
fig, ax = plt.subplots(1, 2, figsize=(12, 7))
ax[0].plot(google_stock_data['Adj Close'], google_stock_data['index'])
pd.plotting.lag_plot(google_stock_data['Adj Close'], lag=1,ax=ax[1])
plt.show()
# FLicker Data (Weak Autocorrelation)
df =pd.read_csv('Flicker.DAT', header=None)
df.reset_index(inplace=True)
fig, ax = plt.subplots(1, 2, figsize=(12, 7))
ax[0].plot(df['index'],df[0])
pd.plotting.lag_plot(df[0],lag=1,ax =ax[1])
plt.show()
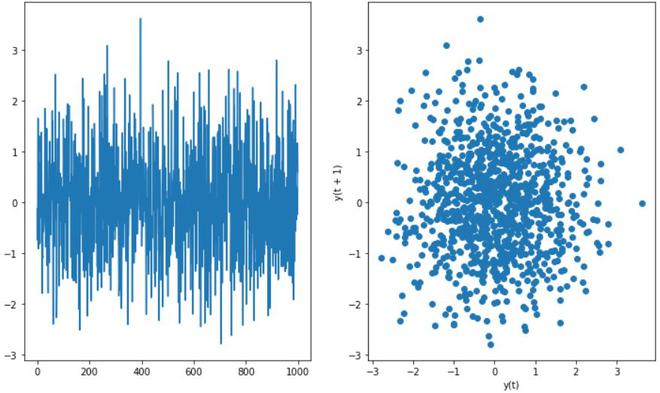
Gráfico aleatorio (sin autocorrelación)
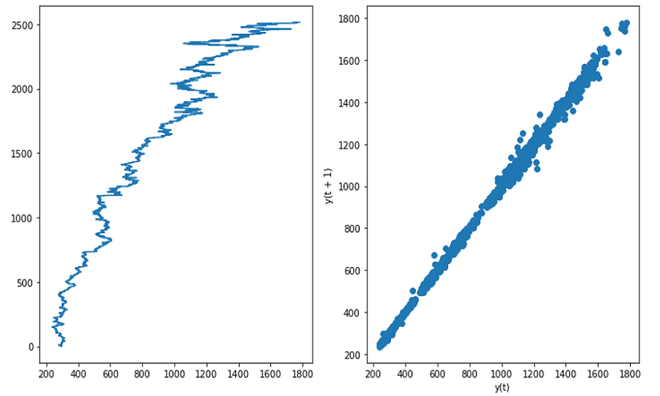
Datos de acciones de Google (autocorrelación fuerte)
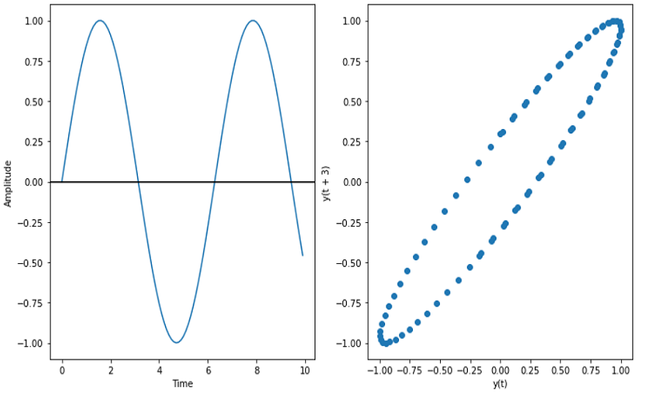
Gráfico de seno (curva elíptica)
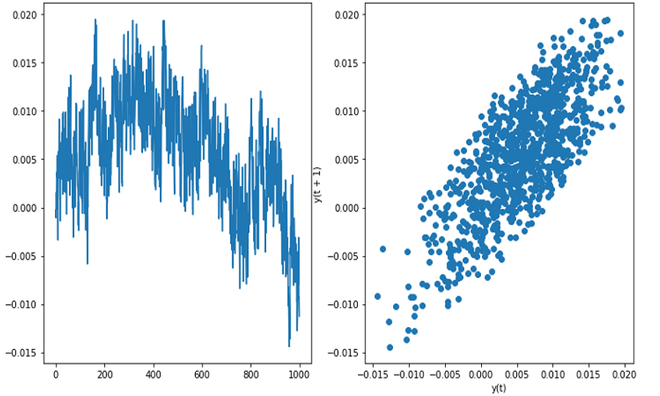
Datos de parpadeo (autocorrelación moderada)