Sabemos que el periódico es una fuente enriquecida de conocimiento. Cuando una persona necesita información sobre un tema o asunto en particular, busca en línea, pero es difícil obtener todos los artículos de noticias antiguos de los periódicos locales regionales relacionados con nuestra búsqueda. Como no todos los periódicos locales ofrecen una búsqueda en línea de personas, en este artículo presentaremos una idea para superar este problema.
¿Qué proyecto hace?
- Este proyecto utiliza imágenes o pdf de imágenes de periódicos de periódicos regionales antiguos como entrada para la base de datos.
- El modelo extraerá el texto de las imágenes usando Pytesseract.
- El texto del Pytesseract se limpiaría con prácticas de PNL para simplificar y eliminar las palabras ( palabras de parada ) que no nos son útiles.
- Los datos se guardarán en forma de par clave-valor en el que las claves tienen una ruta de imagen y los valores tienen palabras clave en la imagen.
- Búsqueda : cuando el usuario visite el sitio web, escribirá el nombre del tema o el nombre de la entidad en el cuadro de búsqueda y luego se cargarán imágenes del periódico en la pantalla.
¿Por qué PNL?
Los artículos de periódicos contienen muchos artículos, preposiciones y otras palabras vacías que no nos son útiles, por lo que la PNL nos ayuda a eliminar esas palabras vacías. También ayuda a obtener palabras únicas.
Tecnologías utilizadas:
- NLTK
- Python
Herramientas utilizadas :
- colaboración de Google
Bibliotecas utilizadas:
- pytesseract: imagen a texto.
- NLTK: preprocesamiento de texto, filtrado.
- pandas: marco de datos de almacenamiento.
Use el diagrama del caso

Implementación paso a paso:
Instalación de bibliotecas
Primero, instale las bibliotecas requeridas en colab.
Python3
!pip install nltk !pip install pytesseract !sudo apt install tesseract-ocr # to check if it installed properly # !which tesseract # pytesseract.pytesseract.tesseract_cmd = ( # r'/usr/bin/tesseract' # )
Importemos todas las bibliotecas necesarias:
Python3
import io
import glob
import os
from PIL import Image
import cv2
import pytesseract
# /usr/bin/tesseract
import pandas as pd
import nltk
nltk.download('popular')
nltk.download('stopwords')
nltk.download('wordnet')
from nltk.tokenize import RegexpTokenizer
from nltk.corpus import stopwords
from nltk.stem.wordnet import WordNetLemmatizer
from IPython.display import Image
from google.colab.patches import cv2_imshow
función previa
Esto limpiará el texto para obtener nombres importantes, palabras clave, etc. La siguiente función elimina las palabras vacías y las palabras duplicadas.
Python3
def pre(text):
text = text.lower()
tokenizer = RegexpTokenizer(r'\w+')
new_words = tokenizer.tokenize(text)
stop_words = list(stopwords.words("english"))
filtered_words = []
for w in new_words:
if w not in stop_words:
filtered_words.append(w)
unique = []
for w in filtered_words:
if w not in unique:
unique.append(w)
res = ' '.join([str(elem) for elem in unique])
res = res.lower()
return res
función to_df
cuando se le da la ruta de la imagen como parámetro, devuelve texto preprocesado en la variable de texto. luego este texto se pasa como parámetro a pre(). esta función devuelve un diccionario con nombre de archivo y texto importante.
Python
def to_df(imgno):
text = pytesseract.image_to_string(imgno)
out = pre(text)
data = {'filename':imgno,
'text':out}
return data
código de conductor
aquí estamos definiendo el marco de datos para almacenar el diccionario que tiene una ruta de imagen y el texto dentro de la imagen. Usaremos este marco de datos para buscar.
Python3
i=0 dff=pd.DataFrame()
Listado de todas las imágenes en la carpeta de contenido.
Python3
images = [] folder = "/content/" for filename in os.listdir(folder): img = cv2.imread(os.path.join(folder, filename)) if img is not None: print(filename) images.append(filename)
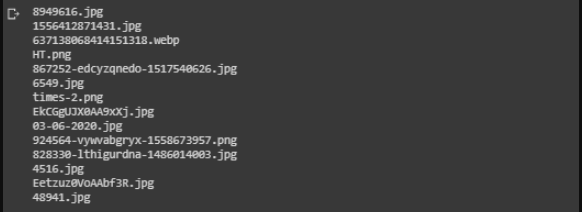
obtener todas las imágenes
For loop para obtener todas las imágenes de noticias de la carpeta.
Python3
for u in images: i += 1 data = to_df(u) dff = dff.append(pd.DataFrame(data, index=[i])) print(dff)
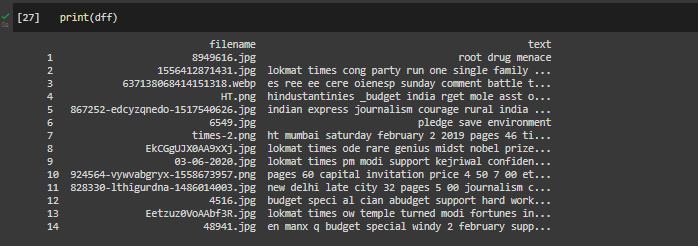
marco de datos
Procesando las imágenes
Python3
# sample text output after processing image dff.iloc[0]['text']
Guardando el marco de datos en la base de datos.

texto de muestra después del preprocesamiento
Guardar el marco de datos
Python3
# saving the dataframe
dff.to_csv('save newsdf.csv')

marco de datos guardado
buscando
Abra el archivo de trama de datos desde el almacenamiento.
Python3
data = pd.read_csv('/content/save newsdf.csv')
data
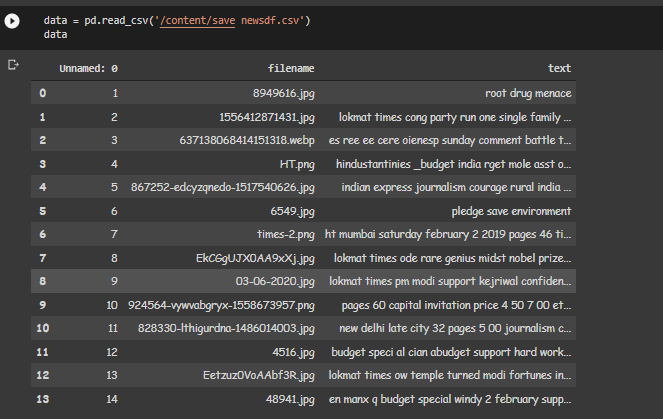
abrir marco de datos desde el almacenamiento
Proporcionamos una string como entrada para que la función obtenga una imagen en la que esté presente la palabra clave.
Python3
txt= 'modi' index= data['text'].str.find(txt ) index
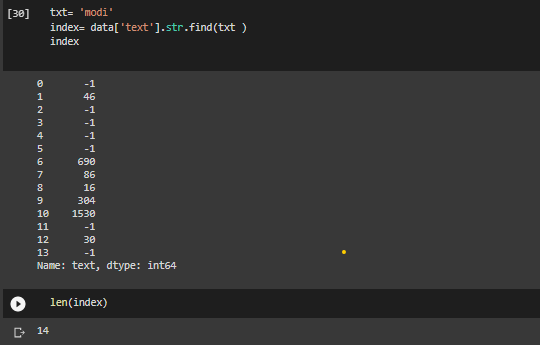
las imágenes de la fila no -1 contienen la palabra ‘modi’
mostrando el resultado
Python3
# we are showing the first result here
for i in range(len(index)):
if (index[i] != -1):
a.append(i)
try:
res = data.iloc[a[0]]['filename']
except:
print("no file")
Image(res)
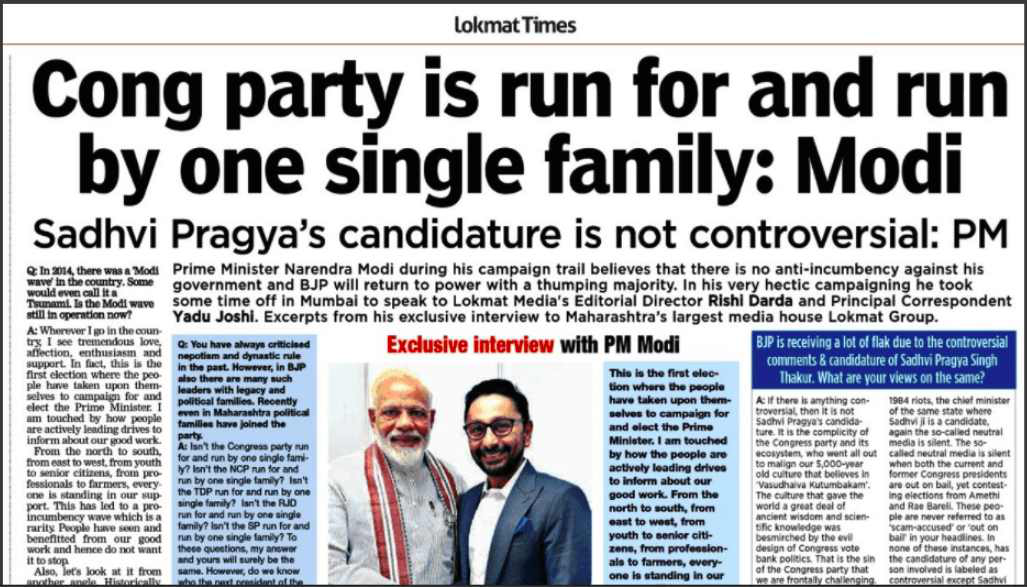
resultado del proyecto
Hemos buscado la palabra ‘ modi ‘. El primer periódico que tiene nuestra palabra buscada, por lo que se muestra aquí.
Alcance de mejora
Podríamos usar una base de datos dedicada, como lucent o elastic search para hacer la búsqueda más eficiente y rápida. Pero por el momento, usamos la biblioteca pandas para obtener la ruta de la imagen para mostrar al usuario.
Aplicación de proyectos en la vida real
- Voter Helper: A medida que se acercan las elecciones y Aman es un votante que no sabe mucho sobre el político por el que va a votar. En esta situación, abre nuestro news.search.in local, luego busca al político. El sitio web mostrará el número del artículo de los periódicos nacionales, así como de los periódicos locales regionales, relacionados con la persona buscada. Ahora está listo para decidir su voto.
- Investigación estudiantil simplificada: puede ser útil para los estudiantes que están investigando sobre el tema, ya que esto les dará todos los artículos de todos los periódicos relacionados con su tema en forma de imagen para que puedan tomar notas de ellos.
- Motor de búsqueda para empresa de periódicos: puede ser utilizado por empresas de prensa para tener una función de búsqueda en su sitio web.