BTS es una eminente banda de K-Pop compuesta por 7 miembros. Este artículo analiza un clasificador de imágenes que reconocería el nombre del miembro de la banda a partir de una imagen. El clasificador de imágenes se construiría usando fastai. Es una biblioteca de aprendizaje profundo que tiene como objetivo democratizar el aprendizaje profundo. Está construido sobre PyTorch y tiene una gran cantidad de modelos con pesos optimizados que están listos para usar. La aplicación se alojaría en Binder y el producto final se vería así:
Preparación del conjunto de datos
Como ocurre con cualquier clasificador de imágenes, el modelo debe entrenarse en un conjunto de datos del que pueda inferir y extraer las características correspondientes a una categoría en particular. El clasificador de imágenes BTS contendría 7 categorías (número total de miembros). El conjunto de datos se puede preparar recopilando manualmente imágenes de diferentes miembros y luego colocándolas en una carpeta de esa categoría. Para acelerar este proceso, se puede emplear un script de Python para crear el conjunto de datos. El script obtendría imágenes de Google Image Search. (Descargo de responsabilidad: el uso de estas imágenes puede conducir a una violación de los derechos de autor, así que proceda bajo su propio riesgo).
Aparecería una carpeta llamada simple_images en la ubicación donde está presente el script. Dentro de la carpeta simple_images estarían presentes las carpetas correspondientes a cada uno de los siete integrantes con 150 imágenes.
Es hora de codificar el clasificador. Se recomienda usar Google Collab (la GPU sería útil durante el entrenamiento) y cargar el conjunto de datos en Google Drive.
Python3
# Import fastbook
from fastbook import *
from fastai.vision.widgets import *
from google.colab import drive
drive.mount('/content/drive')
import fastbook
fastbook.setup_book()
class DataLoaders(GetAttr):
def __init__(self, *loaders): self.loaders = loaders
def __getitem__(self, i): return self.loaders[i]
train, valid = add_props(lambda i, self: self[i])
DataLoaders es una clase que se encarga de proporcionar el conjunto de datos válido y de entrenamiento al modelo.
Python3
# Import the required function to download from the Simple Image Download library.
from simple_image_download import simple_image_download as simp
# Create a response instance.
response = simp.simple_image_download
# The following lines would look up Google Images and download the number of images specified.
# The first argument is the term to search, and the second argument is the number of images to be downloaded.
response.download('BTS Jin', 150)
response.download('BTS Jimin', 150)
response.download('BTS RM', 150)
response.download('BTS J-Hope', 150)
response.download('BTS Suga', 150)
response.download('BTS Jungkook', 150)
Limpieza de los datos
Las imágenes que se han descargado pueden no tener las mismas dimensiones. Se prefiere tener todas las imágenes en el conjunto de datos de dimensionalidad uniforme. La biblioteca fastai tiene una función para esto:
Python3
bts = bts.new( item_tfms=RandomResizedCrop(224, min_scale=0.5), batch_tfms=aug_transforms()) dls = bts.dataloaders(path)
Todas las imágenes se redimensionan a 224 x 224, que es un tamaño estándar para imágenes en el conjunto de datos de entrenamiento.
Crear el modelo
Es hora de crear el Aprendiz. El alumno es el modelo que va a aprender del conjunto de datos que se proporciona. Luego podrá predecir la salida (variable independiente) cuando se le proporcione una imagen que no formaba parte del conjunto de entrenamiento. El alumno que se utiliza aquí se llama ‘Resnet18’. Ya está preentrenado, lo que significa que los pesos se ajustan de tal manera que el modelo debería poder hacer predicciones razonables sin más ajustes. Esta idea se llama transferencia de aprendizaje .
Python3
learn = cnn_learner(dls, resnet18, metrics=error_rate) learn.fine_tune(8)
fine_tune(8) significa que el aprendizaje tiene lugar durante 8 épocas. Se puede jugar con este número. La compensación entre la precisión y la potencia/tiempo de cómputo sería algo a considerar.
El modelo ahora está entrenado y el resultado se puede visualizar mirando la array de confusión.
Python3
interp = ClassificationInterpretation.from_learner(learn) interp.plot_confusion_matrix()
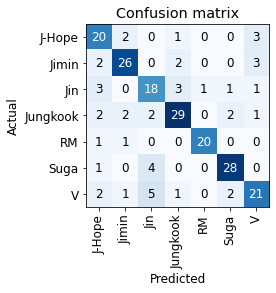
Idealmente, solo los elementos diagonales de la array de confusión deberían ser distintos de cero. Se puede ver que en las predicciones del modelo, hay algunas clasificaciones erróneas presentes.
Se pueden ver las imágenes con las mayores pérdidas . Estas suelen ser las imágenes que el modelo predice incorrectamente con gran certeza o correctamente con menos certeza.
Python3
interp.plot_top_losses(5, nrows=5)

Implementación del modelo
El modelo se implementaría mediante Binder. Se debe pegar la URL de GitHub del cuaderno. En primer lugar, es necesario exportar el modelo y generar un archivo con la extensión .pkl .
Python3
learn.export() path = Path() path.ls(file_exts='.pkl')
Visite el sitio web de Binder. Pegue la URL del repositorio de GitHub, que contiene el cuaderno y el archivo .pkl . En el espacio en blanco ‘URL para abrir’, ingrese la URL (GitHub) del cuaderno. Haga clic en ‘iniciar’ y, después de unos minutos, la aplicación web estará lista para usarse.
Nota: Este clasificador de imágenes se enseñó por primera vez en el curso Fast.AI Deep Learning, lección 2.
Publicación traducida automáticamente
Artículo escrito por akhilkashyap y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA