requisitos previos:
- Regresión lineal
- Descenso de gradiente
- Regresión de lazo y cresta
Introducción:
La regresión de red elástica es una modificación de la regresión lineal que comparte la misma función hipotética para la predicción. La función de costo de la regresión lineal está representada por J .

Here, m is the total number of training examples in the dataset. h(x(i)) represents the hypothetical function for prediction. y(i) represents the value of target variable for ith training example.
La regresión lineal sufre de sobreajuste y no puede manejar datos colineales. Cuando hay muchas características en el conjunto de datos e incluso algunas de ellas no son relevantes para el modelo predictivo. Esto hace que el modelo sea más complejo con una predicción demasiado inexacta en el conjunto de prueba (o sobreajuste). Tal modelo con alta varianza no generaliza sobre los nuevos datos. Entonces, para lidiar con estos problemas, incluimos la regularización de las normas L-2 y L-1 para obtener los beneficios de Ridge y Lasso al mismo tiempo. El modelo resultante tiene mejor poder predictivo que Lasso. Realiza la selección de características y también simplifica la hipótesis. La función de costo modificada para la regresión de red elástica se muestra a continuación:
![\frac{1}{m}\left[\sum_{l=1}^{m}\left(y^{(i)}-h\left(x^{(i)}\right)\right)^{2}+\lambda_{1} \sum_{j=1}^{n} w_{j}+\lambda_{2} \sum_{j=1}^{n} w_{j}^{2}\right]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-b9ecaab808c8021fe133006037b4c435_l3.png "Rendered by QuickLaTeX.com")
Here, w(j) represents the weight for jth feature. n is the number of features in the dataset. lambda1 is the regularization strength for L-1 norm. lambda2 is the regularization strength for L-2 norm.
Intuición matemática:
Durante la optimización del descenso de gradiente de su función de costo, el término de penalización L-2 agregado reduce los pesos del modelo a casi cero. Debido a la penalización de los pesos, la hipótesis se vuelve más simple, más generalizada y menos propensa al sobreajuste. Se agregaron pesos reducidos de penalización L1 cercanos a cero o cero. Esos pesos que se reducen a cero eliminan las características presentes en la función hipotética. Debido a esto, las características irrelevantes no participan en el modelo predictivo. Esta penalización de los pesos hace que la hipótesis sea más predictiva lo que favorece la escasez (modelo con pocos parámetros).
Diferentes casos para ajustar valores de lambda1 y lamda2.
- Si lambda1 y lambda2 se establecen en 0, la regresión de red elástica es igual a la regresión lineal.
- Si lambda1 se establece en 0, la regresión de red elástica es igual a la regresión de cresta.
- Si lambda2 se establece en 0, la regresión de red elástica es igual a la regresión de lazo.
- Si lambda1 y lambda2 se establecen en infinito, todos los pesos se reducen a cero
Entonces, deberíamos establecer lambda1 y lambda2 en algún lugar entre 0 e infinito.
Implementación:
El conjunto de datos utilizado en esta implementación se puede descargar desde el enlace .
Tiene 2 columnas: » Años de experiencia » y » Salario » para 30 empleados en una empresa. Entonces, en esto, entrenaremos un modelo de regresión de red elástica para conocer la correlación entre la cantidad de años de experiencia de cada empleado y su salario respectivo. Una vez entrenado el modelo, podremos predecir el salario de un empleado en base a sus años de experiencia.
Código:
# Importing libraries import numpy as np import pandas as pd from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt # Elastic Net Regression class ElasticRegression() : def __init__( self, learning_rate, iterations, l1_penality, l2_penality ) : self.learning_rate = learning_rate self.iterations = iterations self.l1_penality = l1_penality self.l2_penality = l2_penality # Function for model training def fit( self, X, Y ) : # no_of_training_examples, no_of_features self.m, self.n = X.shape # weight initialization self.W = np.zeros( self.n ) self.b = 0 self.X = X self.Y = Y # gradient descent learning for i in range( self.iterations ) : self.update_weights() return self # Helper function to update weights in gradient descent def update_weights( self ) : Y_pred = self.predict( self.X ) # calculate gradients dW = np.zeros( self.n ) for j in range( self.n ) : if self.W[j] > 0 : dW[j] = ( - ( 2 * ( self.X[:,j] ).dot( self.Y - Y_pred ) ) + self.l1_penality + 2 * self.l2_penality * self.W[j] ) / self.m else : dW[j] = ( - ( 2 * ( self.X[:,j] ).dot( self.Y - Y_pred ) ) - self.l1_penality + 2 * self.l2_penality * self.W[j] ) / self.m db = - 2 * np.sum( self.Y - Y_pred ) / self.m # update weights self.W = self.W - self.learning_rate * dW self.b = self.b - self.learning_rate * db return self # Hypothetical function h( x ) def predict( self, X ) : return X.dot( self.W ) + self.b # Driver Code def main() : # Importing dataset df = pd.read_csv( "salary_data.csv" ) X = df.iloc[:,:-1].values Y = df.iloc[:,1].values # Splitting dataset into train and test set X_train, X_test, Y_train, Y_test = train_test_split( X, Y, test_size = 1/3, random_state = 0 ) # Model training model = ElasticRegression( iterations = 1000, learning_rate = 0.01, l1_penality = 500, l2_penality = 1 ) model.fit( X_train, Y_train ) # Prediction on test set Y_pred = model.predict( X_test ) print( "Predicted values ", np.round( Y_pred[:3], 2 ) ) print( "Real values ", Y_test[:3] ) print( "Trained W ", round( model.W[0], 2 ) ) print( "Trained b ", round( model.b, 2 ) ) # Visualization on test set plt.scatter( X_test, Y_test, color = 'blue' ) plt.plot( X_test, Y_pred, color = 'orange' ) plt.title( 'Salary vs Experience' ) plt.xlabel( 'Years of Experience' ) plt.ylabel( 'Salary' ) plt.show() if __name__ == "__main__" : main()
Producción:
Predicted values [ 40837.61 122887.43 65079.6 ] Real values [ 37731 122391 57081] Trained W 9323.84 Trained b 26851.84
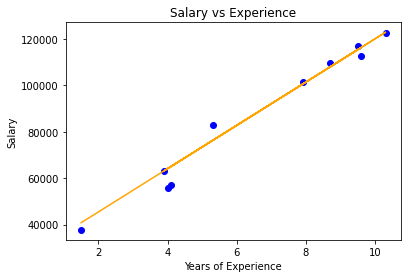
Visualización de modelos de red elástica
Nota: Elastic-Net Regression automatiza ciertas partes de la selección del modelo y conduce a la reducción de la dimensionalidad, lo que lo convierte en un modelo computacionalmente eficiente.
Publicación traducida automáticamente
Artículo escrito por mohit baliyan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA