El aprendizaje profundo ha ido en aumento en esta década y sus aplicaciones son tan amplias y asombrosas que es casi difícil creer que solo han pasado unos pocos años en sus avances. Y en el centro del aprendizaje profundo se encuentra una «unidad» básica que gobierna su arquitectura, sí, son las redes neuronales.
Una arquitectura de red neuronal comprende una serie de neuronas o unidades de activación, como las llamamos, y este circuito de unidades cumple su función de encontrar relaciones subyacentes en los datos. Y está matemáticamente probado que las redes neuronales pueden encontrar cualquier tipo de relación/función independientemente de su complejidad, siempre que sea lo suficientemente profunda/optimizada, ese es el potencial que tiene.
Ahora aprendamos a implementar una red neuronal usando TensorFlow
Instalar Tensorflow
Tensorflow es una biblioteca/plataforma creada y de código abierto por Google. Es la biblioteca más utilizada para aplicaciones de aprendizaje profundo. Ahora, la creación de una red neuronal puede no ser la función principal de la biblioteca TensorFlow, pero se usa con bastante frecuencia para este propósito. Entonces, antes de continuar, instalemos e importemos el módulo TensorFlow.
Usando el comando pip/conda para instalar TensorFlow en su sistema
# terminal/zsh/cmd command # pip pip install tensorflow --upgrade # conda conda install -c conda-forge tensorflow %tensorflow_version 2.x
Descargar y leer los datos
Puede usar cualquier conjunto de datos que desee, aquí he usado el conjunto de datos de calidad del vino tinto de Kaggle. Este es un problema de clasificación, por supuesto, puedes aprender a aplicar el concepto a otros problemas. Primero, descargue el conjunto de datos en su directorio de trabajo. Ahora que los datos están descargados, carguemos los datos como marco de datos.
Python3
import numpy as np
import pandas as pd
# be sure to change the file path
# if you have the dataset in another
# directly than the working folder
df = pd.read_csv('winequality-red.csv')
df.head()
Producción:

Preprocesamiento de datos/división en tren/válido/conjunto de prueba
Hay varias formas de dividir los datos, puede definir funciones personalizadas o usar marcas de tiempo si están presentes o usar funciones predefinidas como train_test_split i n scikit-learn.
Aquí hemos usado la función de muestra para obtener el 75% de los datos para crear el conjunto de entrenamiento y luego usamos el resto de los datos para el conjunto de validación. También puede y debe crear un conjunto de prueba, pero aquí tenemos un conjunto de datos muy pequeño y nuestro enfoque principal aquí es familiarizarse con el proceso y entrenar una red neuronal, ¿verdad?
Ahora dividamos nuestro conjunto de datos.
Python3
import tensorflow as tf # 75% of the data is selected train_df = df.sample(frac=0.75, random_state=4) # it drops the training data # from the original dataframe val_df = df.drop(train_df.index)
Algo a tener en cuenta es que las redes neuronales generalmente funcionan mejor con datos que están en el mismo rango. Por ejemplo, si tiene diferentes columnas y en 1 columna tiene valores que oscilan entre 1 y 10, pero en otra oscila entre 100 y 1000, se sugiere escalar primero todas las columnas al mismo rango para un mejor rendimiento.
Ahora, el método más simple para hacerlo es:
value – (valor mínimo de la columna) / (rango de la columna)
Python3
# calling to (0,1) range max_val = train_df.max(axis= 0) min_val = train_df.min(axis= 0) range = max_val - min_val train_df = (train_df - min_val)/(range) val_df = (val_df- min_val)/range
Ya que hemos terminado de escalar nuestros datos y crear nuestros conjuntos de datos de entrenamiento y validación, separémoslos en características, es decir, entradas y objetivos, ya que así es como vamos a pasarlos al modelo.
Python3
# now let's separate the targets and labels
X_train = train_df.drop('quality',axis=1)
X_val = val_df.drop('quality',axis=1)
y_train = train_df['quality']
y_val = val_df['quality']
# We'll need to pass the shape
# of features/inputs as an argument
# in our model, so let's define a variable
# to save it.
input_shape = [X_train.shape[1]]
input_shape
Producción:
[11]
Esto significa que pasaremos 11 características como entrada a la primera capa de nuestra red neuronal.
Crear modelo de red neuronal
El módulo Keras se basa en TensorFlow y nos brinda toda la funcionalidad para crear una variedad de arquitecturas de redes neuronales. Usaremos la clase Sequential en Keras para construir nuestro modelo. Primero, puede intentar usar el modelo lineal, ya que la red neuronal básicamente sigue las mismas ‘matemáticas’ que la regresión, puede crear un modelo lineal usando una red neuronal de la siguiente manera:
Crear un modelo lineal
Python3
model = tf.keras.Sequential([ tf.keras.layers.Dense(units=1,input_shape=input_shape)]) # after you create your model it's # always a good habit to print out it's summary model.summary()
Producción:
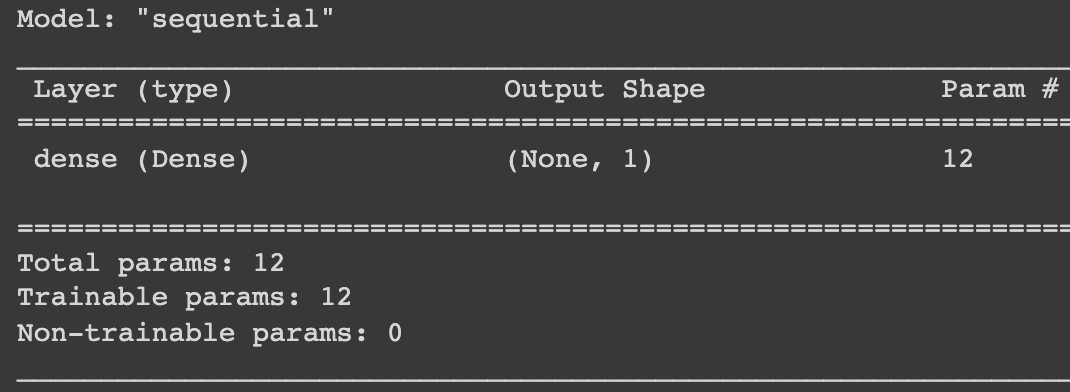
Pero este es básicamente un modelo lineal, ¿qué sucede si su conjunto de datos es un poco más complejo y las relaciones entre las características son mucho más diversas y desea un modelo no lineal? ¿Que necesitas? La respuesta es Funciones de activación . Aquí es donde las redes neuronales realmente comienzan a brillar. No podemos profundizar en las funciones de activación en este artículo, pero básicamente, estas agregan/introducen la no linealidad a nuestro modelo, cuanto más las use, más patrones complejos puede encontrar nuestro modelo.
Creación de una red neuronal multicapa
Crearemos una red de 3 capas con 1 capa de entrada, 1 capa oculta1 con 64 unidades y 1 capa de salida. Usaremos la función de activación ‘relu’ en las capas ocultas. Usaremos el método secuencial en el módulo Keras, que se usa muy a menudo para crear redes neuronales de varias capas. En keras, tenemos diferentes tipos de capas de redes neuronales y/o capas de transformación que puede usar para construir varios tipos de redes neuronales, pero aquí solo hemos usado 3 capas densas (en keras.layers) con función de activación de relu.
Python3
model = tf.keras.Sequential([ tf.keras.layers.Dense(units=64, activation='relu', input_shape=input_shape), tf.keras.layers.Dense(units=64, activation='relu'), tf.keras.layers.Dense(units=1) ]) model.summary()
Producción:
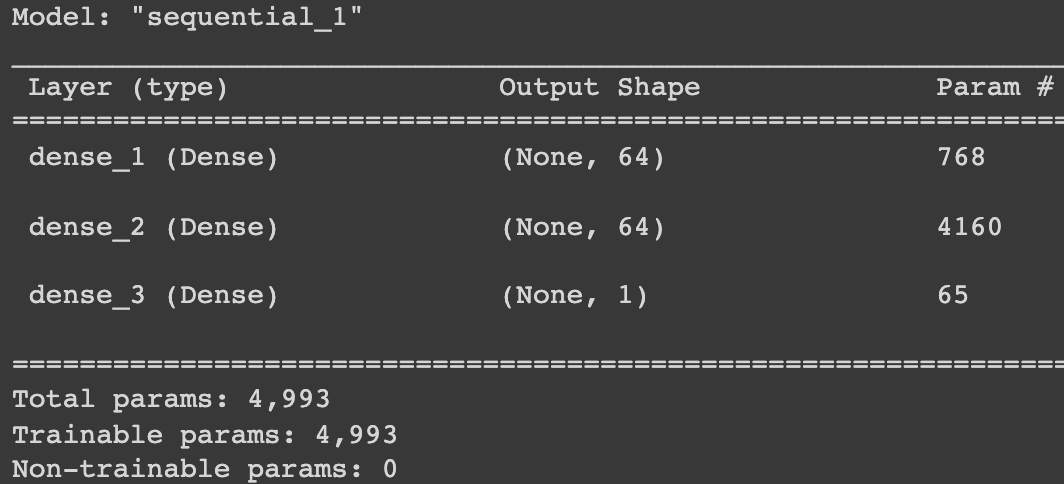
En Keras, después de crear su modelo, debe ‘compilar’ otros parámetros para él, como se muestra a continuación. Esto es como si estableciésemos todos los parámetros para nuestro modelo.
Python3
# adam optimizer works pretty well for # all kinds of problems and is a good starting point model.compile(optimizer='adam', # MAE error is good for # numerical predictions loss='mae')
Así que usamos el optimizador Adam y también le dijimos al modelo que calculara la pérdida mae (error absoluto medio).
Entrenando al modelo
Ya que terminamos de crear e instanciar nuestro modelo, ahora es el momento de entrenarlo. Usaremos el método de ajuste para entrenar nuestro modelo. Este método toma características y objetivos como objetivos, y también podemos pasar los datos de validación con él, probará automáticamente su modelo en la validación y anotará las métricas de pérdida. También proporcionamos el tamaño de lote, lo que hace es dividir nuestros datos en lotes pequeños y alimentarlos a nuestro modelo para el entrenamiento en cada época, esto es muy útil cuando tiene grandes conjuntos de datos porque reduce el consumo de RAM y CPU en su máquina.
Ahora, aquí solo hemos entrenado nuestro modelo para 15 épocas porque nuestro propósito aquí es familiarizarnos con el proceso y no con la precisión en sí, pero tendrá que aumentar o disminuir la cantidad de épocas en su máquina. Hay métodos de optimización que puede usar, como la detención anticipada que detendrá automáticamente el entrenamiento cuando el modelo comience a sobreajustarse, por lo que también puede intentar usarlos. Le proporcioné un enlace en la parte inferior si desea leer al respecto.
Python3
losses = model.fit(X_train, y_train, validation_data=(X_val, y_val), # it will use 'batch_size' number # of examples per example batch_size=256, epochs=15, # total epoch )
Producción:

Aquí solo hemos entrenado durante 15 épocas, pero definitivamente deberías entrenar para más e intentar cambiar el modelo en sí.
Genere predicciones y analice la precisión
Ya que hemos completado el proceso de entrenamiento, intentemos usarlo para predecir la ‘calidad del vino’. Para hacer predicciones usaremos la función de predicción del objeto modelo. Solo demos tres ejemplos como entradas e intentemos predecir la calidad del vino para los 3.
Python3
# this will pass the first 3 rows of features # of our data as input to make predictions model.predict(X_val.iloc[0:3, :])
Producción:
array([[0.40581337],
[0.5295989 ],
[0.3883106 ]], dtype=float32)
Ahora, comparemos nuestras predicciones con el valor objetivo.
Python3
y_val.iloc[0:3]
Producción:
0 0.4 9 0.4 12 0.4 Name: quality, dtype: float64
Como podemos ver, nuestras predicciones están bastante cerca del valor real, es decir, 0,4 en los tres casos. Puede definir otra función para convertir la predicción en un número entero para predecir la calidad en una escala del 1 al 10 para una mejor comprensión, pero eso es algo trivial, lo principal es que comprenda todo el proceso que se describe aquí.
Visualización de entrenamiento frente a pérdida de validación
Puede analizar la pérdida y determinar si se trata de un sobreajuste o no es fácil y luego tomar las medidas adecuadas en consecuencia.
Python3
loss_df = pd.DataFrame(losses.history) # history stores the loss/val # loss in each epoch # loss_df is a dataframe which # contains the losses so we can # plot it to visualize our model training loss_df.loc[:,['loss','val_loss']].plot()
Producción:
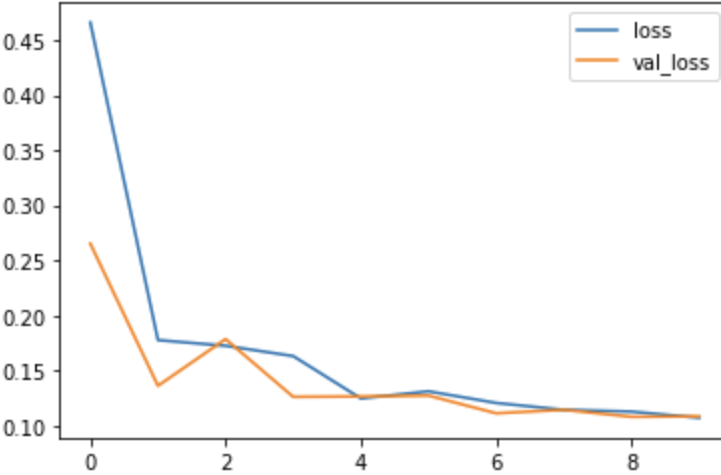
El punto clave a tener en cuenta al analizar la precisión/error de su modelo es:
Obviamente, su función de pérdida disminuye continuamente, pero ese podría no ser el caso para el conjunto de datos de validación y, en algún momento, su modelo se sobreajustará a los datos y el error de validación comenzará a aumentar en lugar de disminuir. Por lo tanto, puede detenerse en la época en la que la pérdida de validación parece estar aumentando. También puede probar otros algoritmos de optimización, como la detención anticipada (devolución de llamada en Keras). Puedes leer sobre esto aquí .
Publicación traducida automáticamente
Artículo escrito por bobde_yagyesh y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA