Los codificadores automáticos son un tipo de red neuronal que genera una codificación de «n capas» de la entrada dada e intenta reconstruir la entrada usando el código generado. Esta arquitectura de red neuronal se divide en la estructura del codificador, la estructura del decodificador y el espacio latente, también conocido como «cuello de botella». Para aprender las representaciones de datos de la entrada, la red se entrena utilizando datos no supervisados. Estas representaciones de datos comprimidas pasan por un proceso de decodificación en el que se reconstruye la entrada. Un autocodificador es una tarea de regresión que modela una función de identidad.
Estructura del codificador
Esta estructura comprende una red neuronal de avance convencional que está estructurada para predecir la representación de vista latente de los datos de entrada. Está dado por:

Donde  representa la capa oculta 1,
representa la capa oculta 1,  representa la capa oculta 2,
representa la capa oculta 2,  representa la entrada del codificador automático y h representa el espacio de datos de baja dimensión de la entrada
representa la entrada del codificador automático y h representa el espacio de datos de baja dimensión de la entrada
Estructura del decodificador
Esta estructura comprende una red neuronal de avance, pero la dimensión de los datos aumenta en el orden de la capa del codificador para predecir la entrada. Está dado por:

Donde  representa la capa oculta 1,
representa la capa oculta 1,  representa la capa oculta 2,
representa la capa oculta 2,  representa el espacio de datos de baja dimensión generado por la estructura del codificador y
representa el espacio de datos de baja dimensión generado por la estructura del codificador y  representa la entrada reconstruida.
representa la entrada reconstruida.
Estructura espacial latente
Esta es la representación de datos o la representación comprimida de bajo nivel de la entrada del modelo. La estructura del decodificador utiliza esta forma de datos de baja dimensión para reconstruir la entrada. está representado por 
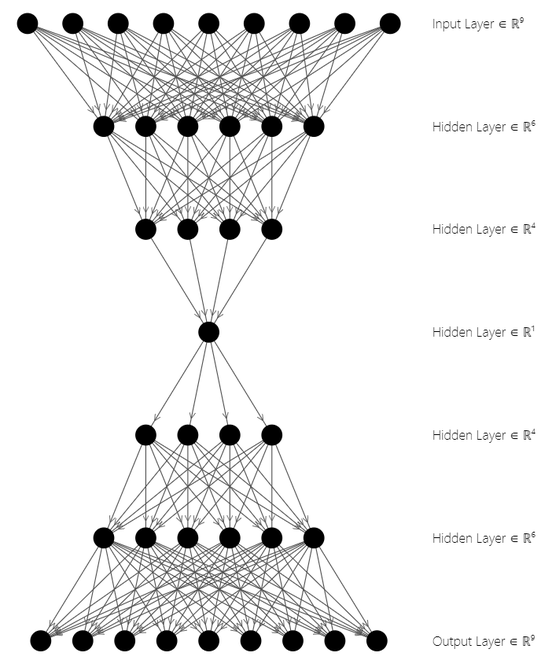
Arquitectura del codificador automático
En la figura anterior, las tres capas superiores representan el bloque codificador, mientras que las tres capas inferiores representan el bloque decodificador. El espacio de estado latente está en el medio de la arquitectura  . Los codificadores automáticos se utilizan para la compresión de imágenes, extracción de características, reducción de dimensionalidad, etc. Veamos ahora la implementación.
. Los codificadores automáticos se utilizan para la compresión de imágenes, extracción de características, reducción de dimensionalidad, etc. Veamos ahora la implementación.
Módulos necesarios
- torch: este paquete de python proporciona computación de tensor de alto nivel y redes neuronales profundas basadas en el sistema autograd.
pip install torch
- torchvision: este módulo consta de una amplia gama de bases de datos, arquitecturas de imágenes y transformaciones para visión por computadora
pip install torchvision
Implementación de Autoencoder en Pytorch
Paso 1: Importación de módulos
Usaremos los módulos torch.optim y torch.nn del paquete torch y conjuntos de datos y transformaciones del paquete torchvision. En este artículo, utilizaremos el popular conjunto de datos MNIST que comprende imágenes en escala de grises de dígitos individuales escritos a mano entre 0 y 9.
Python3
import torch from torchvision import datasets from torchvision import transforms import matplotlib.pyplot as plt
Paso 2: cargando el conjunto de datos
Este fragmento carga el conjunto de datos MNIST en el cargador mediante el módulo DataLoader. El conjunto de datos se descarga y se transforma en tensores de imagen. Con el módulo DataLoader, los tensores se cargan y están listos para usarse. El conjunto de datos se carga con la reproducción aleatoria habilitada y un tamaño de lote de 64.
Python3
# Transforms images to a PyTorch Tensor tensor_transform = transforms.ToTensor() # Download the MNIST Dataset dataset = datasets.MNIST(root = "./data", train = True, download = True, transform = tensor_transform) # DataLoader is used to load the dataset # for training loader = torch.utils.data.DataLoader(dataset = dataset, batch_size = 32, shuffle = True)
Paso 3: crear una clase de codificador automático
En este fragmento de codificación, la sección del codificador reduce la dimensionalidad de los datos secuencialmente como lo indica:
28*28 = 784 ==> 128 ==> 64 ==> 36 ==> 18 ==> 9
Donde el número de Nodes de entrada es 784 que se codifican en 9 Nodes en el espacio latente. Mientras que, en la sección del decodificador, la dimensionalidad de los datos se incrementa linealmente al tamaño de entrada original, para reconstruir la entrada.
9 ==> 18 ==> 36 ==> 64 ==> 128 ==> 784 ==> 28*28 = 784
Donde la entrada es la representación del espacio latente de 9 Nodes y la salida es la entrada reconstruida de 28*28.
El codificador comienza con 28*28 Nodes en una capa Lineal seguida de una capa ReLU, y continúa hasta que la dimensionalidad se reduce a 9 Nodes. El descifrador usa estas 9 representaciones de datos para recuperar la imagen original usando la arquitectura inversa del codificador. La arquitectura del descifrador utiliza una capa sigmoide para variar los valores entre 0 y 1 únicamente.
Python3
# Creating a PyTorch class # 28*28 ==> 9 ==> 28*28 class AE(torch.nn.Module): def __init__(self): super().__init__() # Building an linear encoder with Linear # layer followed by Relu activation function # 784 ==> 9 self.encoder = torch.nn.Sequential( torch.nn.Linear(28 * 28, 128), torch.nn.ReLU(), torch.nn.Linear(128, 64), torch.nn.ReLU(), torch.nn.Linear(64, 36), torch.nn.ReLU(), torch.nn.Linear(36, 18), torch.nn.ReLU(), torch.nn.Linear(18, 9) ) # Building an linear decoder with Linear # layer followed by Relu activation function # The Sigmoid activation function # outputs the value between 0 and 1 # 9 ==> 784 self.decoder = torch.nn.Sequential( torch.nn.Linear(9, 18), torch.nn.ReLU(), torch.nn.Linear(18, 36), torch.nn.ReLU(), torch.nn.Linear(36, 64), torch.nn.ReLU(), torch.nn.Linear(64, 128), torch.nn.ReLU(), torch.nn.Linear(128, 28 * 28), torch.nn.Sigmoid() ) def forward(self, x): encoded = self.encoder(x) decoded = self.decoder(encoded) return decoded
Paso 4: inicialización del modelo
Validamos el modelo usando la función de error cuadrático medio, y usamos un Adam Optimizer con una tasa de aprendizaje de 0.1 y una caída de peso de 
Python3
# Model Initialization model = AE() # Validation using MSE Loss function loss_function = torch.nn.MSELoss() # Using an Adam Optimizer with lr = 0.1 optimizer = torch.optim.Adam(model.parameters(), lr = 1e-1, weight_decay = 1e-8)
Paso 5: Crear generación de salida
La salida de cada época se calcula pasándola como parámetro a la clase Model() y el tensor final se almacena en una lista de salida. La imagen en (-1, 784) y se pasa como parámetro a la clase Autoencoder, que a su vez devuelve una imagen reconstruida. La función de pérdida se calcula usando la función MSELoss y se grafica. En el optimizador, los valores de gradiente iniciales se vuelven a cero usando zero_grad(). loss.backward() calcula los valores de graduación y los almacena. Usando la función step(), el optimizador se actualiza.
La imagen original y la imagen reconstruida de la lista de salidas se separan y transforman en una array NumPy para trazar las imágenes.
Nota: este fragmento tarda entre 15 y 20 minutos en ejecutarse, según el tipo de procesador. Inicialice epoch = 1, para obtener resultados rápidos. Use un tiempo de ejecución GPU/TPU para cálculos más rápidos.
Python3
epochs = 20
outputs = []
losses = []
for epoch in range(epochs):
for (image, _) in loader:
# Reshaping the image to (-1, 784)
image = image.reshape(-1, 28*28)
# Output of Autoencoder
reconstructed = model(image)
# Calculating the loss function
loss = loss_function(reconstructed, image)
# The gradients are set to zero,
# the gradient is computed and stored.
# .step() performs parameter update
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Storing the losses in a list for plotting
losses.append(loss)
outputs.append((epochs, image, reconstructed))
# Defining the Plot Style
plt.style.use('fivethirtyeight')
plt.xlabel('Iterations')
plt.ylabel('Loss')
# Plotting the last 100 values
plt.plot(losses[-100:])
Producción:
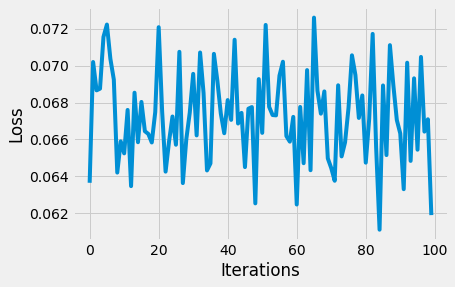
Gráfico de función de pérdida
Paso 6: Entrada/Entrada reconstruida a/desde Autoencoder
La primera array de imágenes de entrada y la primera array de imágenes de entrada reconstruida se trazaron utilizando plt.imshow().
Python3
for i, item in enumerate(image): # Reshape the array for plotting item = item.reshape(-1, 28, 28) plt.imshow(item[0]) for i, item in enumerate(reconstructed): item = item.reshape(-1, 28, 28) plt.imshow(item[0])
Producción:
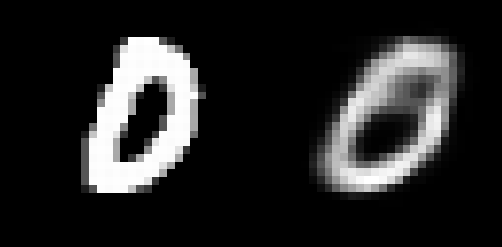
Gráfico de muestra 1: imagen de entrada (izquierda) y entrada reconstruida (derecha)
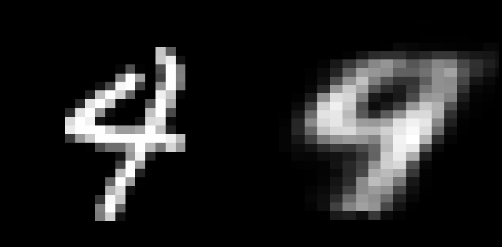
Gráfico de muestra 2: imagen de entrada (izquierda) y entrada reconstruida (derecha)
Aunque las imágenes reconstruidas parecen ser adecuadas, son extremadamente granulosas. Para mejorar este resultado, se pueden agregar capas y/o neuronas adicionales, o el modelo de codificador automático podría construirse sobre una arquitectura de red neuronal de convoluciones. Para la reducción de dimensionalidad, los codificadores automáticos son bastante beneficiosos. Sin embargo, también podría usarse para eliminar el ruido de los datos y comprender la dispersión de un conjunto de datos.
Publicación traducida automáticamente
Artículo escrito por therealnavzz y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA